NoSQL Interview Questions and Answers for .NET Developers (2026) – MongoDB, Redis, Vector DBs, Graph DBs & More


Welcome to the our .NET Interview Questions and Answers series exploring the ins and outs of C# and .NET! This chapter explores NoSQL Databases questions that .NET engineers should be able to answer in an interview.
The Answers are split into sections: What 👼 Junior, 🎓 Middle, and 👑 Senior .NET engineers should know about a particular topic.
Also, please take a look at other articles in the series: C# / .NET Interview Questions and Answers
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum
NoSQL Core Concepts, Design Patterns, and Best Practices Interview Questions and Answers
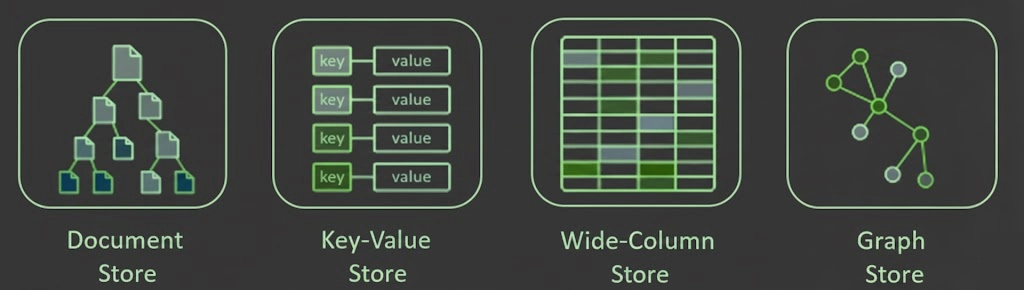
❓ What are the main categories of NoSQL databases?
NoSQL databases can be categorized into four main groups. Each is built for a different purpose:
1. Document databases
Store data as JSON-like documents. Each document can have a flexible structure, making them ideal for apps that evolve quickly.
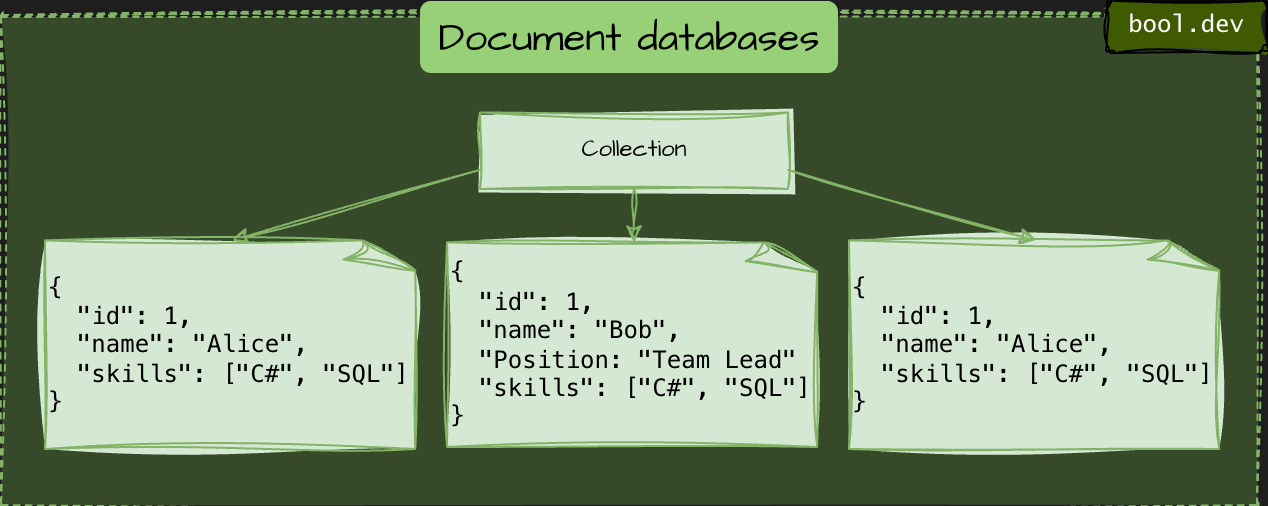
{
"id": 1,
"name": "Alice",
"skills": ["C#", "SQL"]
}Suitable for: APIs, user profiles, and content apps.
2. Key-Value stores
Use a simple key–value pair structure, such as a dictionary. Perfect for caching and high-speed lookups.

Suitable for: caching, session storage, leaderboards.
3. Column-family (Wide-Column Database) Databases
Store data by columns, not rows. Optimized for large-scale analytics and time-series workloads.
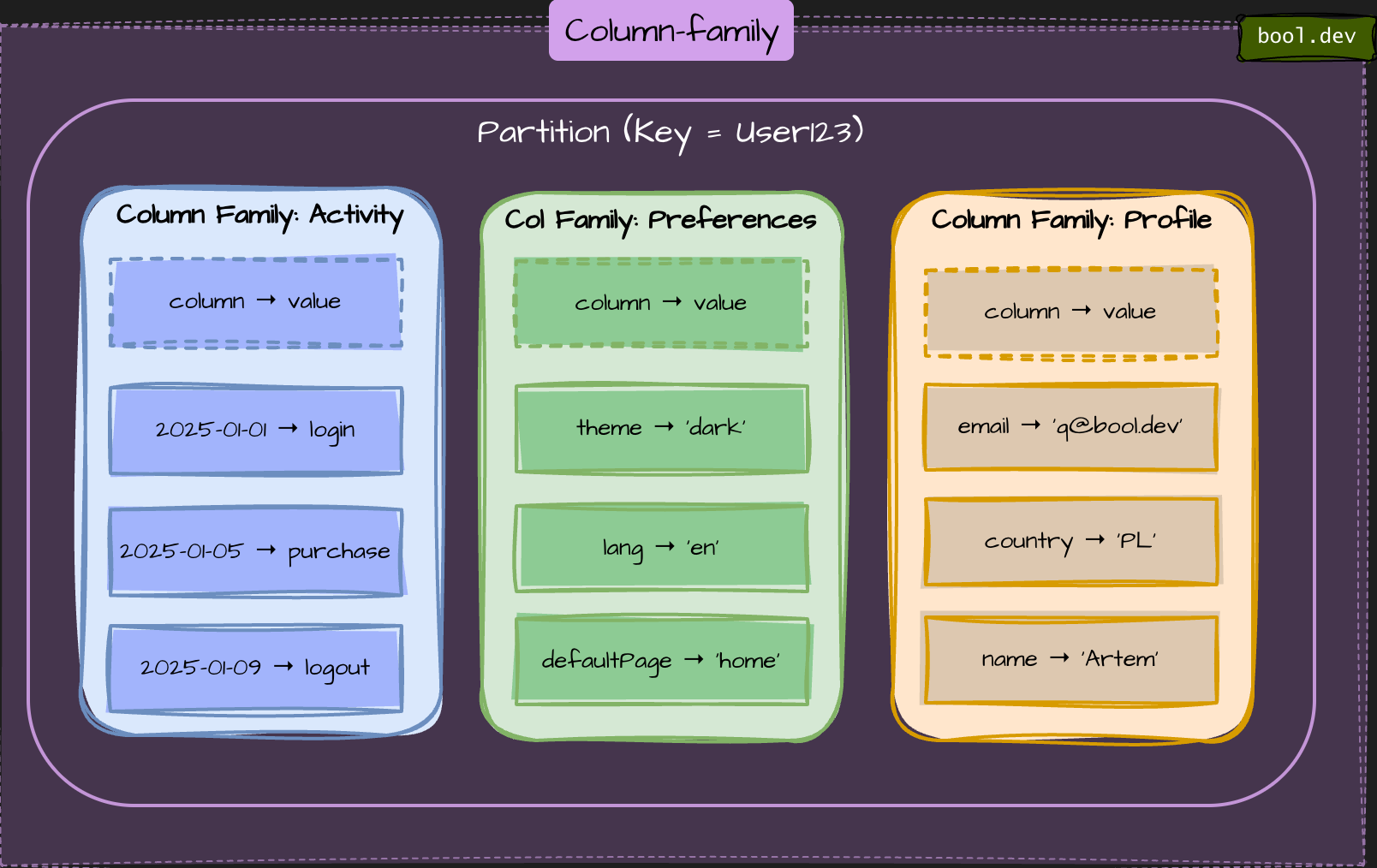
Example: Apache Cassandra, HBase
Suitable for logs, IoT data, and reporting purposes.
4. Graph databases
Focus on connections: nodes represent entities, edges represent connections. Used for social networks, recommendations, and fraud detection.
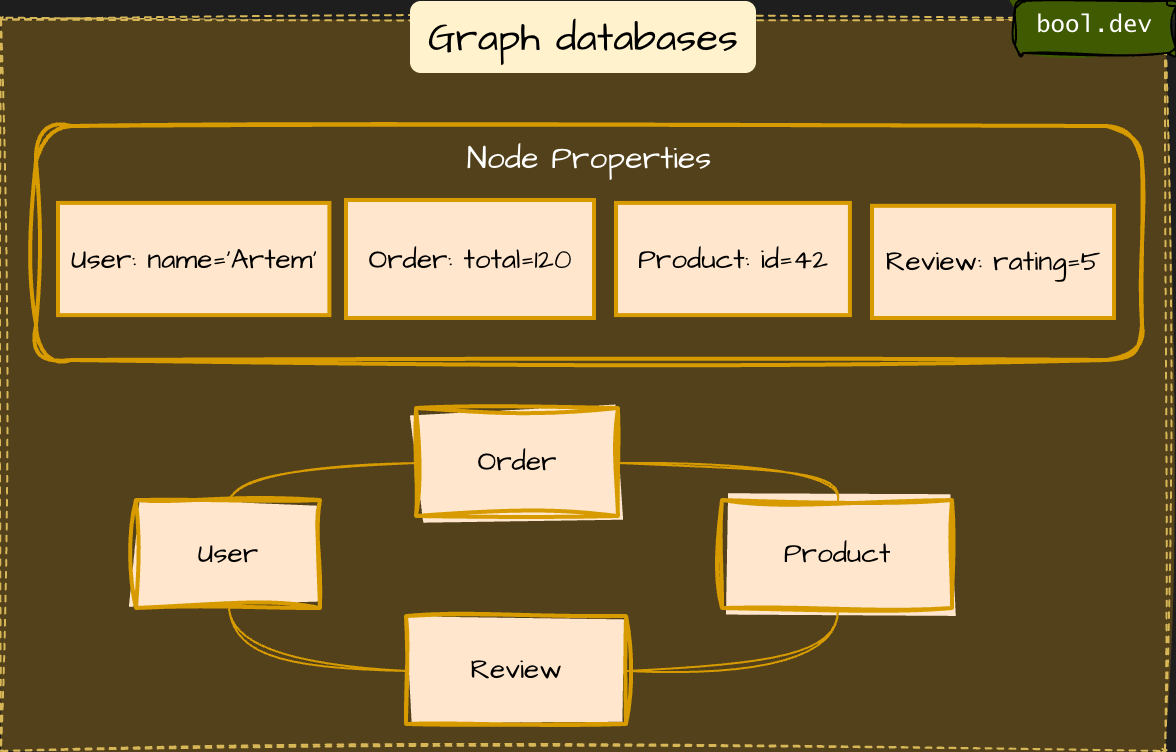
Example: Neo4j, Amazon Neptune
Suitable for: social networks, recommendations, fraud checks.
Vector Databases
A vector database is a specialized database designed to store, manage, and search high-dimensional vector embeddings, which are numerical representations (arrays of numbers) of unstructured data like text, images, audio, or video, enabling AI to find conceptually similar items (similarity search) rather than just matching keywords. It organizes these vectors in mathematical space, placing related items close together, which is crucial for semantic search, recommendation engines, and powering Generative AI tools by providing context and grounding for LLMs.
Example: Chroma, pgvector, Pinecone, Faiss, Milvus
What .NET devs should know
- 👼 Junior: NoSQL includes document, key-value, column, and graph databases, each of which stores data differently.
- 🎓 Middle: Pick type by use case: key-value for caching, document for APIs, column for analytics, graph for relationships.
- 👑 Senior: Design around data access patterns, not schema flexibility. Often, hybrid architectures combine different types — for example, Redis for caching, MongoDB for content, and Neo4j for recommendations.
❓ How do you decide between SQL and NoSQL for a new feature?
Choosing between SQL and NoSQL is all about matching the tool to your data. I run a quick 4-point check:
- Data shape
- Consistency
- Queries
- Scale
What .NET engineers should know:
- 👼 Junior: Should know SQL is structured and relational, while NoSQL is schema-less and built for scalability.
- 🎓 Middle: Should analyze data relationships, query patterns, and future scalability needs before choosing.
- 👑 Senior: Should design hybrid models when needed, mixing SQL for core data and NoSQL for flexibility or performance, ensuring consistency, backups, and proper data flows between them.
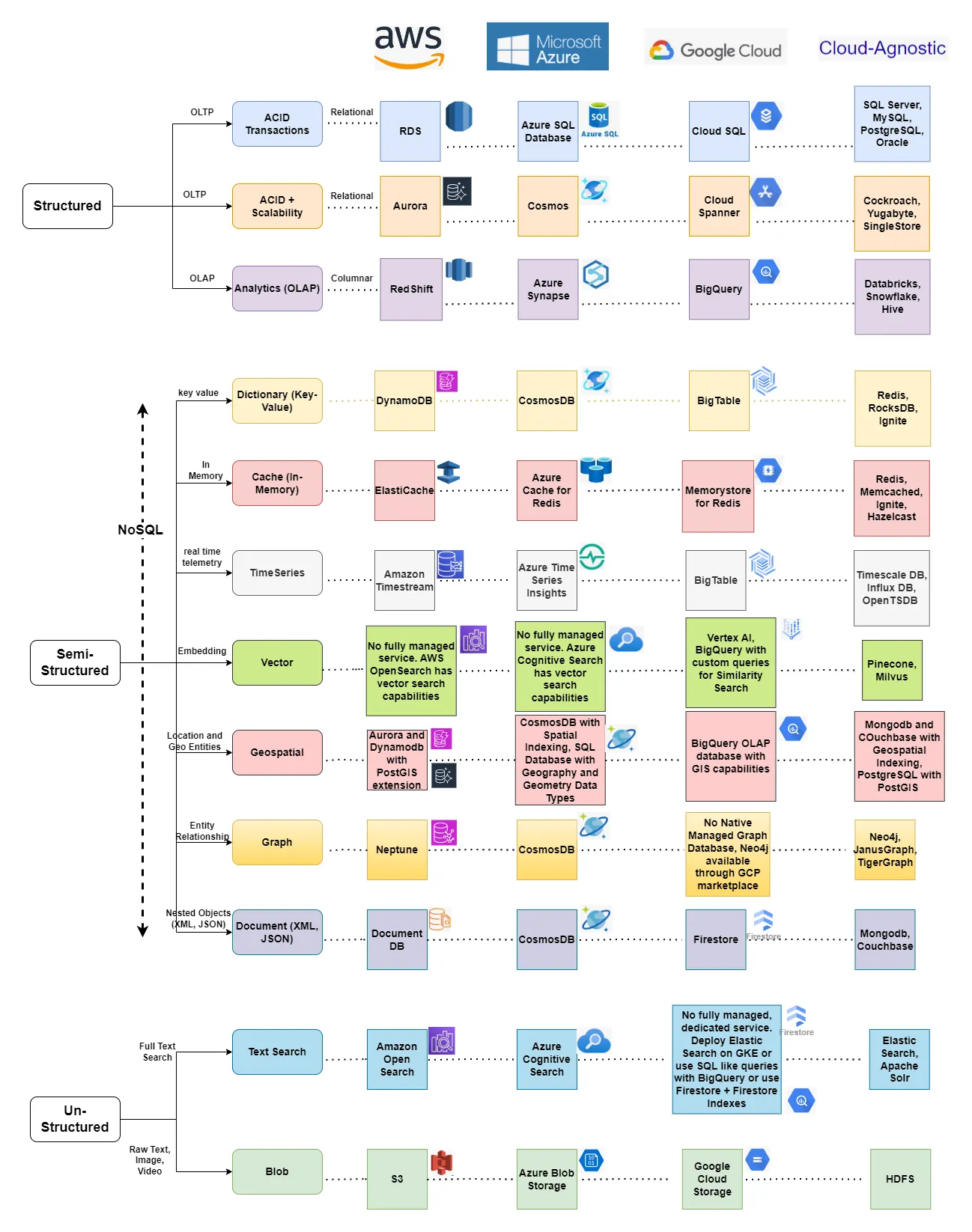
📚 Resources: Choosing the Right Database: A Guide to AWS, Azure, GCP, and Cloud-Agnostic Solutions
❓ What are common read/write patterns in NoSQL (GetByID, fan-out, time-series, append-only)?
That's a great question about NoSQL design. Unlike relational databases, NoSQL designs are access-pattern-driven, meaning the data structure is optimized for the specific read and write operations your application performs.
Here are four common read/write patterns in NoSQL, focusing on key-value and document stores like DynamoDB or MongoDB:
GetByID (key-value lookup)
Fast primary-key read. Everything lives under a single ID.
Perfect for profile lookups, config, and sessions.
GET users:123Fan-out (one-to-many)
You write multiple copies of data, so reads are cheap.
Example: when a user posts something, you copy it into each follower's feed.
- Write cost: high
- Read cost: extremely fast
Used by Twitter, Instagram, and TikTok feed systems.
Time-series (sorted by timestamp)
Data arrives in order, and you query recent entries.
Use partition keys grouped by device/user/date, and sort the keys by timestamp.
Examples: metrics, logs, IoT, events.
PK = device#42
SK = 2025-11-30T12:00:00ZAppend-only (immutable events)
Never update or delete. Just add new events.
Great for audit logs, streams, event sourcing, and analytics pipelines.
What .NET engineers should know:
- 👼 Junior: Basic patterns: GetByID, time-series by timestamp, append-only logs.
- 🎓 Middle: Use fan-out-on-write for fast feeds, materialized views for read-heavy workloads, and stable keys for time-series.
- 👑 Senior: Design full read/write paths, optimize shard keys, apply denormalization safely, combine event streams + views, and avoid hot partitions.
❓ How do ACID and BASE principles differ in the context of NoSQL?
ACID and BASE are two ways to handle data reliability. ACID is strict. BASE is flexible.
ACID (used in SQL databases)
- Atomicity: All or nothing — a transaction either completes fully or not at all.
- Consistency: Data always follows the rules (no half-written junk).
- Isolation: One transaction doesn’t mess up another.
- Durability: Once saved, data remains intact even after crashes.
Best for: banking, orders, and inventory — where mistakes can be costly.
BASE (used in NoSQL)
- Basically Available: The system continues to function even if parts fail.
- Soft state: Data might be out of sync for a short time.
- Eventually consistent: It catches up, just not instantly.
Best for: social feeds, shopping carts, analytics, where speed and uptime matter more than perfect sync.
In practice, Many NoSQL databases (like MongoDB, DynamoDB, Cosmos DB) let you pick:
- Want instant correctness? Turn on strong consistency.
- Need max speed? Use eventual consistency.
What .NET devs should know
- 👼 Junior: ACID keeps data always correct; BASE allows temporary inconsistencies for better speed and scalability.
- 🎓 Middle: Relational systems use ACID for strict consistency. NoSQL uses BASE to ensure speed and availability in distributed environments.
- 👑 Senior: Choose based on business requirements: critical systems require ACID, while distributed and high-traffic systems rely on BASE. Some databases now support tunable consistency, allowing users to achieve the best of both worlds.
📚 Resources:
❓ How does the CAP theorem influence database architecture design?
The CAP theorem says that in a distributed database, you can only guarantee two out of three things at the same time:
- Consistency (C): Every read gets the latest data. No stale info.
- Availability (A): Every request receives a response (even if the system is under stress).
- Partition tolerance (P): The system continues to function even if network messages are lost between servers.
| Type | What it prioritizes | Example databases |
|---|---|---|
| CP (Consistency + Partition Tolerance) | Keeps data correct, might reject requests during partitions | MongoDB (strong mode), Redis (in cluster mode), HBase |
| AP (Availability + Partition Tolerance) | Always responds, may serve slightly outdated data | Cassandra, DynamoDB, CouchDB |
| CA (Consistency + Availability) | Works only without network issues (mostly theoretical) | Single-node SQL databases |

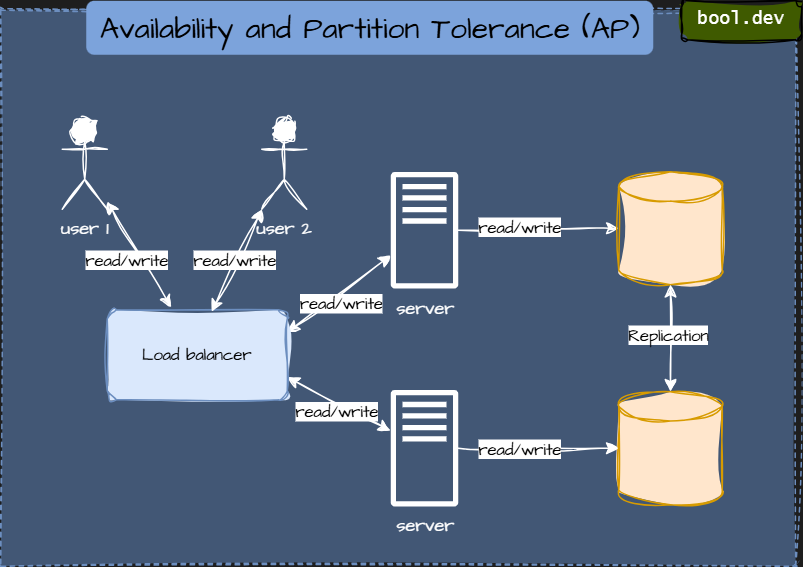
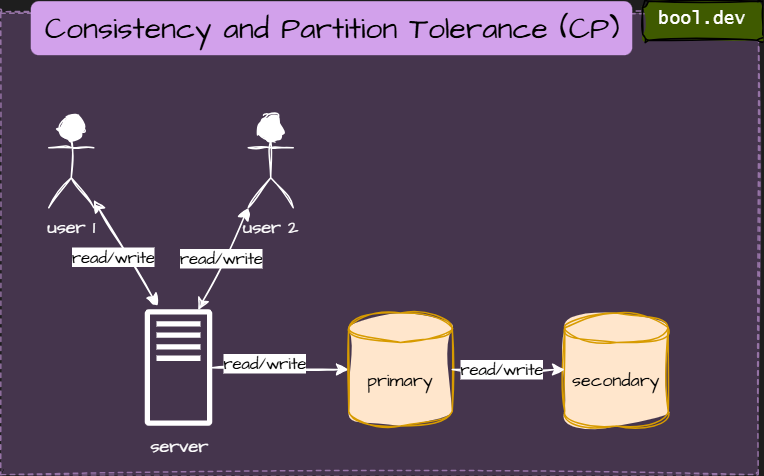
What .NET devs should know about CAP theorem
- 👼 Junior: Understand what CAP stands for and why you can’t have all three at once.
- 🎓 Middle: Be able to choose between CP and AP systems depending on the app’s needs, for example, using MongoDB for strong consistency or Redis for high availability.
- 👑 Senior: Know that CAP isn’t the whole story, also understand the PACELC theorem, which adds Latency vs Consistency trade-offs even when there’s no partition. Design distributed systems with tunable consistency and clear business-driven choices.
📚 Resources: CAP Theorem
❓ What are typical consistency models?
Consistency models define how up-to-date and synchronized data is across replicas in a distributed system.
They describe what a read operation can expect after a write, ranging from strictest to most relaxed guarantees.
1. Strong consistency (Immediate consistency)
After a successful write, all reads return the latest value. It feels like a single-node database, but it may reduce availability during partitions.
Example: Cosmos DB (strong mode), Spanner, MongoDB (majority writes).
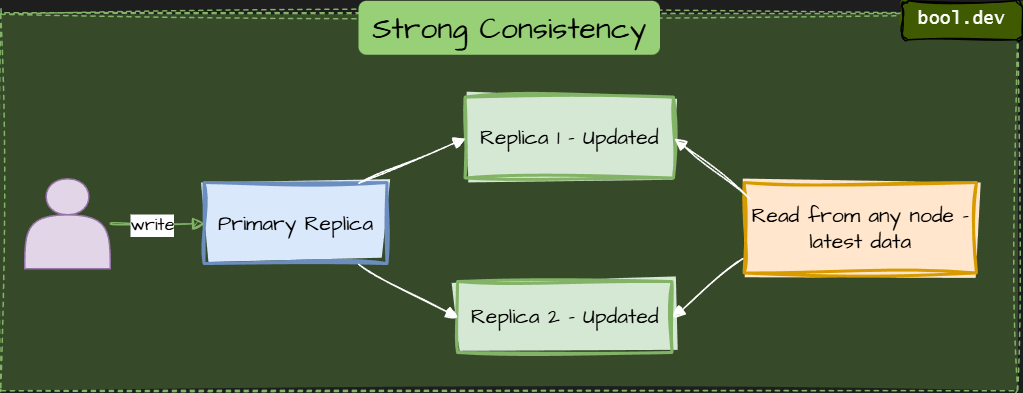
⚠️ Higher latency and lower availability
2. Bounded staleness consistency
Reads may lag writes, but only for a defined time window or a specified number of versions.
It provides a predictable delay — useful when you can tolerate slightly outdated data.
Example: Cosmos DB bounded staleness with “lag = 5 writes.”
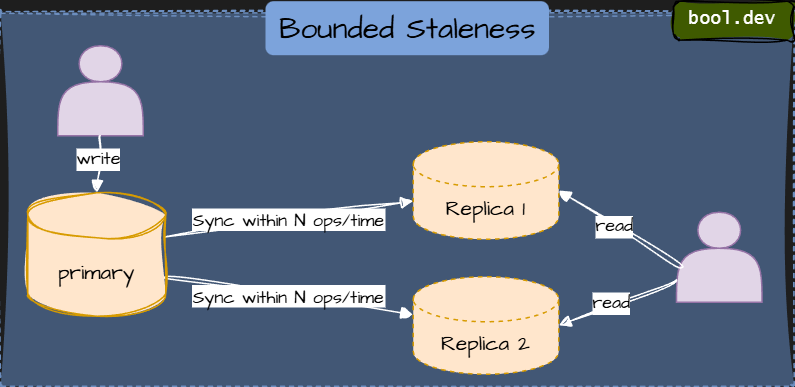
⚠️ Data may be slightly stale but within defined limits
3. Session consistency
Guarantees that within a single client session, reads always reflect the user’s previous writes.
Across sessions, other users might see older data.
Example: Cosmos DB session model, DynamoDB with session tokens.
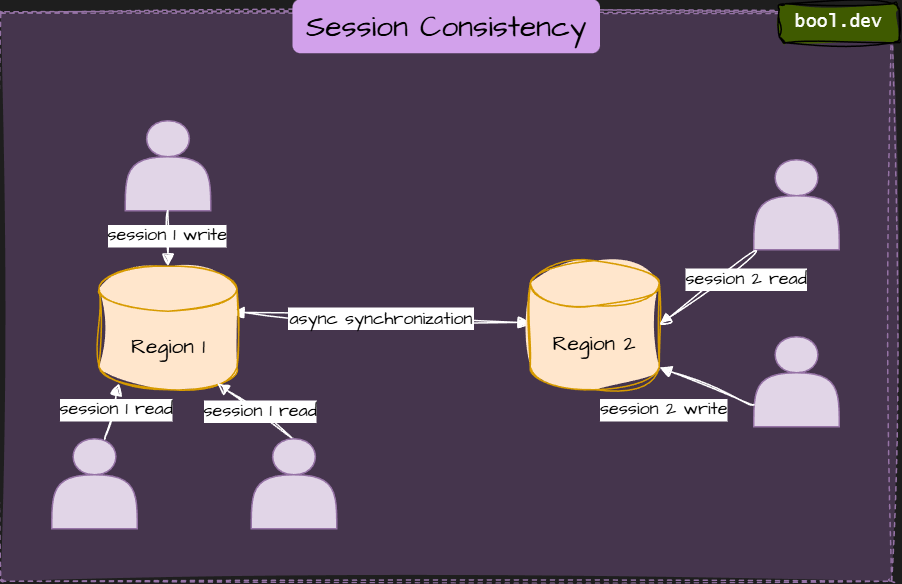
⚠️ Doesn’t enforce global real-time sync; replication logic gets more complex
4. Causal consistency
If operation A causes operation B, everyone sees them in that order.
Maintains logical event order without enforcing global synchronization.
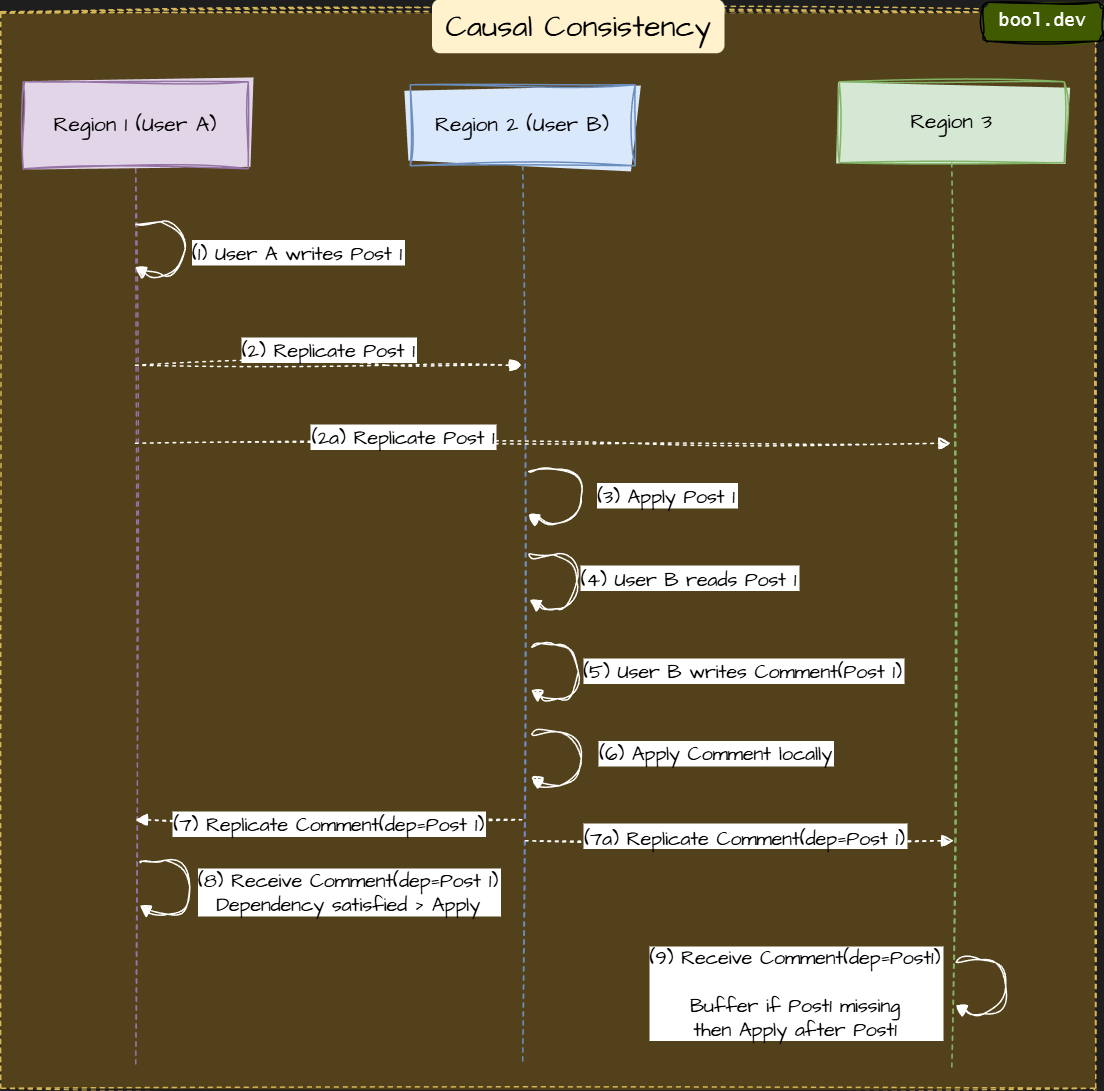
⚠️ More complex replication logic
5. Eventual consistency
Writes propagate asynchronously so that replicas may return old data; however, all replicas will eventually converge.
Used when high availability and performance matter more than strict accuracy.
Example: DynamoDB (default), Cassandra, CouchDB.
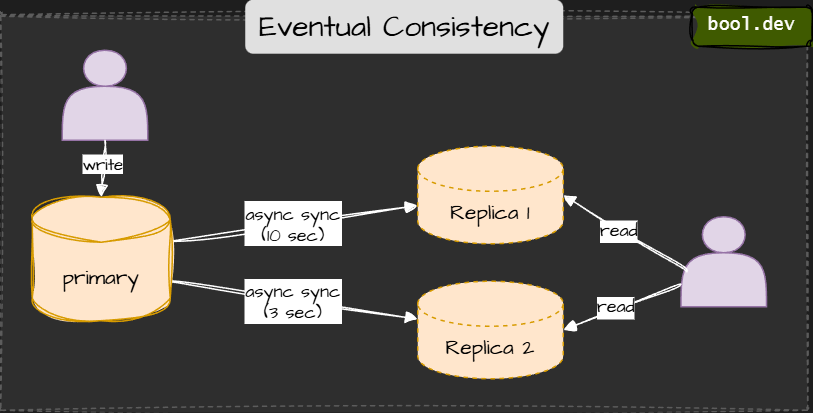
⚠️ Temporary inconsistency
What .NET engineers should know:
- 👼 Junior: Understand that consistency defines how fresh your reads are after a write — stronger consistency means slower but safer data.
- 🎓 Middle: Be able to pick the right model for the job: strong for transactions, session for user actions, eventual for analytics or caching.
- 👑 Senior: Know how consistency models map to CAP and PACELC trade-offs. Understand that platforms like Cosmos DB, DynamoDB, and MongoDB allow for tunable consistency, enabling you to mix models per operation for a balance of performance and reliability.
📚 Resources: Consistency Models for Distributed Systems
❓ What are polyglot persistence patterns, and when are they appropriate?
Polyglot persistence refers to using multiple database types within the same system — each chosen for its specific strengths. Instead of forcing a single database to handle every workload, you mix technologies such as SQL, NoSQL, and search engines to optimize performance, scalability, and cost.

Example:
In an e-commerce system:
- SQL (PostgreSQL, SQL Server): for orders, payments, and transactions — strong consistency.
- NoSQL (MongoDB, DynamoDB): for product catalogs — flexible schema.
- Redis: for caching sessions and fast lookups.
- Elasticsearch: for full-text search.
- Neo4j: for product recommendations or relationships.
Each component stores data in the format and engine that fits its access pattern.
📚 Resources: Polyglot Persistence
❓ How would you model relationships in NoSQL systems that don’t support joins?
In NoSQL, there are no traditional SQL joins. Therefore, you must design relationships based on how data is accessed, rather than how it’s normalized. The key is deciding between embedding (storing together) and referencing (storing separately).
What .NET engineers should know:
- 👼 Junior: Understand that NoSQL doesn’t have joins — you either embed data together or reference it by ID.
- 🎓 Middle: Know when to embed (for fast reads and few updates) versus reference (to avoid duplication). Handle joins in the app layer or via aggregation frameworks.
- 👑 Senior: Model relationships based on query patterns, data growth, and consistency needs. Able to denormalize intentionally and consider patterns like CQRS, read models, or materialized views for join-heavy use cases.
📚 Resources: MongoDB Best Practices Guide
❓ What are common anti-patterns in NoSQL data modeling?
The most significant anti-pattern is treating NoSQL databases as if they were relational databases. If you normalize everything and rely on joins, performance drops fast.
Another common mistake is over-embedding huge or frequently changing data. The opposite is also undesirable: over-referencing everything, forcing the app to manually join multiple documents for a single read.
Partitioning mistakes are also significant — selecting a poor partition key can lead to hot partitions and reduce throughput.
And finally, modeling without thinking about how the app actually queries the data. In NoSQL, the schema should follow access patterns, not the other way around.
What .NET engineers should know:
- 👼 Junior: Know that NoSQL shouldn’t be modeled like SQL — avoid heavy normalization.
- 🎓 Middle: Balance embedding vs referencing and design around read/write patterns.
- 👑 Senior: Prevent hot partitions, manage document growth, and apply patterns like CQRS or materialized views for complex domains.
❓ What’s the difference between schema-on-write and schema-on-read?
Schema-on-write means you validate and shape the data before saving it. If the data doesn’t match the structure, it won’t get in. This is how relational databases work. Schema-on-write gives strong consistency and clean data, but slows down ingestion.
Schema-on-read means you dump the data as-is and structure it only when you query it. That’s how data lakes and many NoSQL systems behave. Schema-on-read is fast to write and flexible, but it puts more work on readers and can hide dirty data.
What .NET engineers should know:
- 👼 Junior: know that relational DBs enforce schema when writing, while NoSQL/data lakes often don’t.
- 🎓 Middle: know when each model fits: strict business rules → write, analytics, and logs → read.
- 👑 Senior: understand operational impact: validation cost, query complexity, storage formats, and downstream tradeoffs.
📚 Resources: Schema-on-Write Vs. Schema-on-Read
❓ How do you handle data versioning and schema evolution in NoSQL systems?
The typical pattern is to add new fields, retain the old ones for a while, and let the application handle both versions. Most teams use version fields, migration scripts, or lazy migrations when reading documents.
NoSQL offers freedom, but you must own the discipline.
Common patterns:
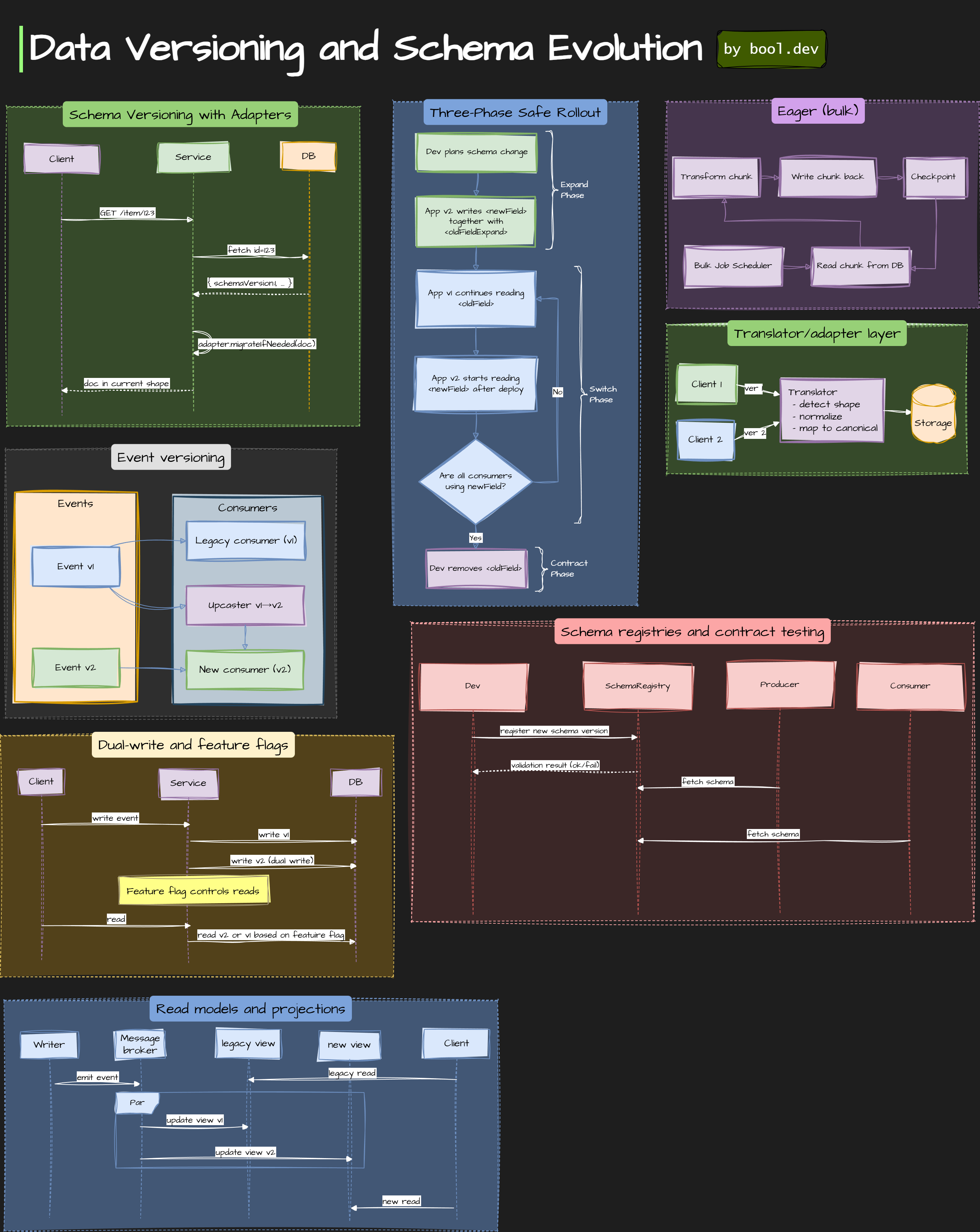
What .NET engineers should know:
- 👼 Junior: Be aware that documents can vary, and apps must handle missing fields safely.
- 🎓 Middle: know patterns like version tags, backward compatibility, and lazy migrations.
- 👑 Senior: Know when to use lazy migrations vs complete rewrites, how to guarantee compatibility across microservices, and how to design data models that evolve without breaking consumers.
📚 Resources: Data Versioning and Schema Evolution Patterns
❓ How do you implement referential integrity or constraints in a NoSQL world?
NoSQL databases won’t enforce foreign keys, so the service must define all relationship rules.
You validate references on write, clearly structure ownership, and use events to keep dependent data in sync.
Practical ways to do it:
- Application-level checks. Before creating an Order, verify that the User exists. Your code enforces the relationship.
- Ownership boundaries. One service owns both sides, or one side is read-only, no cross-service FK chaos.
- Embed when stable. If data rarely changes, store it directly inside the document. Removes joins completely.
- Soft references. Store only IDs. Validate them before writing. Very common in MongoDB, DynamoDB, and Cosmos DB.
- Event-driven cleanup. When the parent is removed, publish an event so that other collections delete or archive children.
- Integrity audits. Background jobs detect orphans and fix them.
What .NET engineers should know:
- 👼 Junior: NoSQL doesn't enforce relationships, so the service must check references manually.
- 🎓 Middle: Use ID-based references, service-level validation, and clear ownership boundaries.
- 👑 Senior: Model bounded contexts, use embedding strategically, rely on events for cleanup, and run integrity audits for long-term consistency.
📚 Resources:
MongoDB Interview Questions and Answers
❓ If you were designing a blog post with comments, would you embed comments or use a separate collection?
It depends on how the data will be read, written, and scaled. MongoDB gives you two options:
- Embed comments inside the blog post document.
- Reference comments from a separate collection.
Example (embedded):
{
"_id": 1,
"title": "Pagination Strategies in Databases",
"content": "...",
"comments": [
{ "author": "Alex", "text": "Nice read!", "date": "2025-10-18" },
{ "author": "Maria", "text": "Can you add keyset example?", "date": "2025-10-19" }
]
}Good when comments are small in number and always loaded with the post — it’s one read, fast and simple.
Example (referenced):
{
"_id": 1,
"title": "Pagination Strategies in Databases",
"content": "..."
}
{
"_id": 101,
"postId": 1,
"author": "Alex",
"text": "Nice read!",
"date": "2025-10-18"
}Better when you have many comments or need to query them independently (pagination, moderation, analytics, etc.).
Factors influencing the decision:
- Access pattern: If you always load comments with the post → embed. If comments are fetched separately or paginated → reference.
- Volume: Few comments per post → embed. Thousands per post → reference.
- Growth and updates: Frequent inserts or deletes → reference. Rarely updated → embed.
- Atomicity: If you want to update post + comments together → embed (one atomic document).
What .NET engineers should know:
- 👼 Junior: Should know how to embed stores that store data together, referencing stores that store it separately.
- 🎓 Middle: Should decide based on access patterns and data growth — embedding fits small, related data; referencing fits extensive or independent data.
- 👑 Senior: Should design hybrid models — e.g., embed the latest few comments for quick reads and keep the complete list in a separate collection for scalability and analytics.
📚 Resources: Embedded Data Versus References
❓ What are the trade-offs between MongoDB's flexible schema and the rigid schema of a relational database?
MongoDB’s flexible schema lets you store documents with different structures in the same collection. That’s powerful, but it comes with trade-offs in consistency, validation, and long-term maintainability.
Here’s how it compares:
| Aspect | MongoDB (Flexible Schema) | Relational DB (Rigid Schema) |
|---|---|---|
| Structure | Documents in a collection can have different fields and shapes. | Every table enforces a fixed structure — same columns for all rows. |
| Development speed | Fast to start — no migrations required when fields change. | Slower to evolve — requires schema migrations when altering structure. |
| Consistency | Depends on app logic; no strong schema validation by default. | Enforced by database schema — strong data integrity. |
| Querying | Flexible but can become complex if data is inconsistent. | Predictable and optimized with joins, constraints, and indexes. |
| Relationships | Embedded documents or manual references (no native joins). | Strong relational modeling — natural support for foreign keys. |
| Transactions | Supported but less efficient across multiple documents. | Native ACID transactions across tables. |
| Scalability | Easy horizontal scaling; data distributed by design. | Vertical scaling by default, sharding requires extra setup. |
| Use cases | Rapid prototyping, CMS, product catalogs, event data, logs. | Financial systems, reporting, ERP, structured business data. |
What .NET engineers should know:
- 👼 Junior: Should know MongoDB gives flexibility, while SQL enforces structure.
- 🎓 Middle: Should understand when each model fits — flexibility for evolving data, structure for reliable integrity.
- 👑 Senior: Should design hybrid systems combining both — flexible for dynamic parts, relational for critical core data.
📚 Resources:
❓ How does MongoDB handle transactions, and what are the differences between its approach and that of a relational database?
MongoDB initially supported atomic operations only at the single-document level. Starting from MongoDB 4.0, it introduced multi-document ACID transactions, making it behave more like a traditional relational database when needed, but with some key differences.
How MongoDB transactions work:
- Transactions group multiple read/write operations across one or more documents.
- They follow ACID guarantees (Atomicity, Consistency, Isolation, Durability).
- Internally, MongoDB implements a two-phase commit across affected documents and shards.
When to use MongoDB transactions:
- Financial or order systems where multiple collections must stay consistent.
- Multi-step workflows (like moving funds or updating related records).
- Rarely, for every operation, they add latency and reduce scalability.
Example:
using var session = await client.StartSessionAsync();
session.StartTransaction();
try
{
await usersCollection.UpdateOneAsync(session,
u => u.Id == "u1", Builders<User>.Update.Inc(u => u.Points, 10));
await ordersCollection.InsertOneAsync(session,
new Order { UserId = "u1", Amount = 99 });
await session.CommitTransactionAsync();
}
catch
{
await session.AbortTransactionAsync();
}What .NET engineers should know:
- 👼 Junior: Should know MongoDB supports transactions similar to SQL, but with more overhead.
- 🎓 Middle: Should understand how to use sessions and commit/abort logic, and when it’s worth the cost.
- 👑 Senior: Should design systems to avoid unnecessary transactions — keeping most operations atomic per document and using transactions only where integrity is genuinely required.
📚 Resources: Transactions MongoDB
❓ How do you approach indexing in a document database like MongoDB compared to a relational database?
In both MongoDB and relational databases, indexes speed up queries — but the way you design and think about them is slightly different because of how data is stored and accessed.
MongoDB stores data as JSON-like documents rather than in rows and columns, so the indexing strategy must account for document structure, query patterns, and nested fields.
Here’s how the two compare:
| Aspect | MongoDB (Document DB) | Relational Database (SQL) |
|---|---|---|
| Data model | JSON documents with nested objects and arrays. | Tables with fixed columns and relationships. |
| Default index | _id field automatically indexed. | Primary key or clustered index by default. |
| Index types | Single field, compound, text, geospatial, hashed, wildcard. | Single column, composite, full-text, and unique indexes. |
| Nested fields | Can index fields deep inside documents (e.g., user.address.city). | Only flat table columns can be indexed. |
| Query optimization | Indexes should match query filters and sort patterns; compound indexes often used. | Relies on query planner, joins, and foreign key relationships. |
| Write performance | Too many indexes slow down writes — every insert/update must update multiple indexes. | Similar trade-off, but RDBMS engines often handle index updates more efficiently. |
| Indexing strategy | Index what you query most often — especially fields used in filters, sorts, and lookups. | Usually index primary keys, joins, and WHERE clause columns. |
| Schema changes | Adding or removing indexes doesn’t require schema migration. | Adding indexes may need table locks or schema changes. |
Example (MongoDB):
db.users.createIndex({ "email": 1 });
db.orders.createIndex({ "userId": 1, "createdAt": -1 });Example (SQL):
CREATE INDEX IX_Users_Email ON Users (Email);
CREATE INDEX IX_Orders_UserId_CreatedAt ON Orders (UserId, CreatedAt DESC);Key mindset difference:
- In MongoDB, design indexes based on actual query patterns, not just schema fields.
- In SQL, design indexes based on relationships and joins between normalized tables.
What .NET engineers should know:
- 👼 Junior: Should know that indexes improve read performance but slow down writes.
- 🎓 Middle: Should understand how to analyze query plans and build compound or nested indexes matching queries.
- 👑 Senior: Should design indexing strategies based on workload — balancing read vs write trade-offs, monitoring index usage, and pruning unused indexes for optimal performance.
📚 Resources:
❓ How does the aggregation pipeline work, and when would you use it?
The aggregation pipeline is MongoDB’s way of processing data step by step, like a mini-ETL inside the database.
Each stage transforms the documents: filter, group, sort, join, reshape, compute fields, and more, as needed.
You use it when simple find() queries aren’t enough, and you need server-side data processing.
How it works:
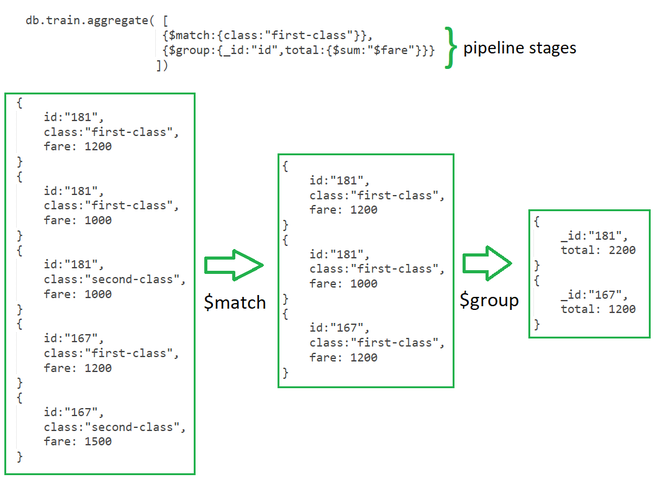
Each stage modifies or filters them.
The final result is returned as transformed documents.
Common use cases:
- Reporting and analytics
- Grouping, sums, counts, averages
- Filtering + projections + sorting in one go
- Joining collections with $lookup
- Preparing read models for APIs
What .NET engineers should know:
- 👼 Junior: It’s a step-by-step processing pipeline for filtering, grouping, and transforming MongoDB data.
- 🎓 Middle: Use it for reporting, joins, analytics, and complex server-side transformations.
- 👑 Senior: Optimize pipelines, understand index usage, push filtering early, avoid unnecessary stages, and design collections that aggregate efficiently.
📚 Resources: Aggregation in MongoDB
❓ What’s the difference between replica sets and sharded clusters?
Replica Set
A Replica Set consists of multiple MongoDB instances that mirror each other's data. A replica-set consists of one "Primary" and one or more "Secondaries".
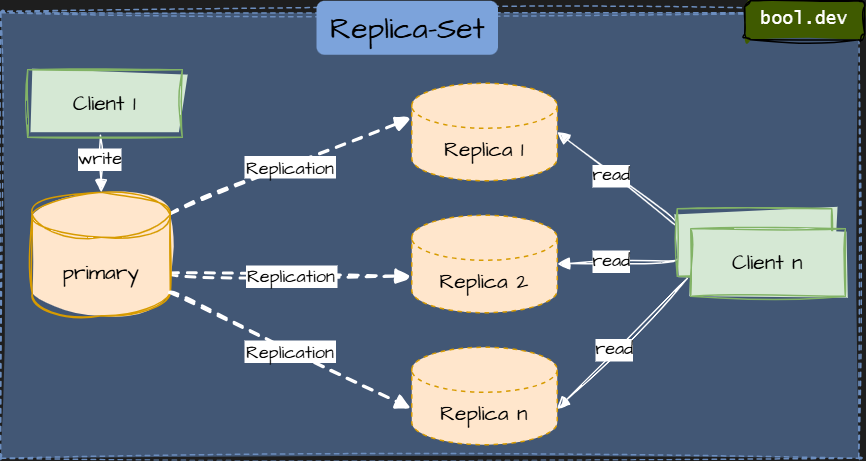
All write operations are directed to the primary, which then replicates them to the secondaries. So writes won't get faster when you add more secondaries.
Read operations, on the other hand, can be served by any secondary replica. When you have a high volume of read requests, you can increase read performance by adding more secondaries to the replica set and having your clients distribute their requests to different members of the replica set.
Replica-sets also offer fault-tolerance. When a member of the replica set goes down, the others take over. When the primary goes down, the secondaries will elect a new primary. For that reason, it is recommended for productive deployment to always use MongoDB as a replica set of at least three servers, with at least two of them holding data. In that scenario, the third option is a data-less "arbiter" that serves no purpose other than electing the remaining secondary as the new primary when the actual primary fails.
Sharded Cluster
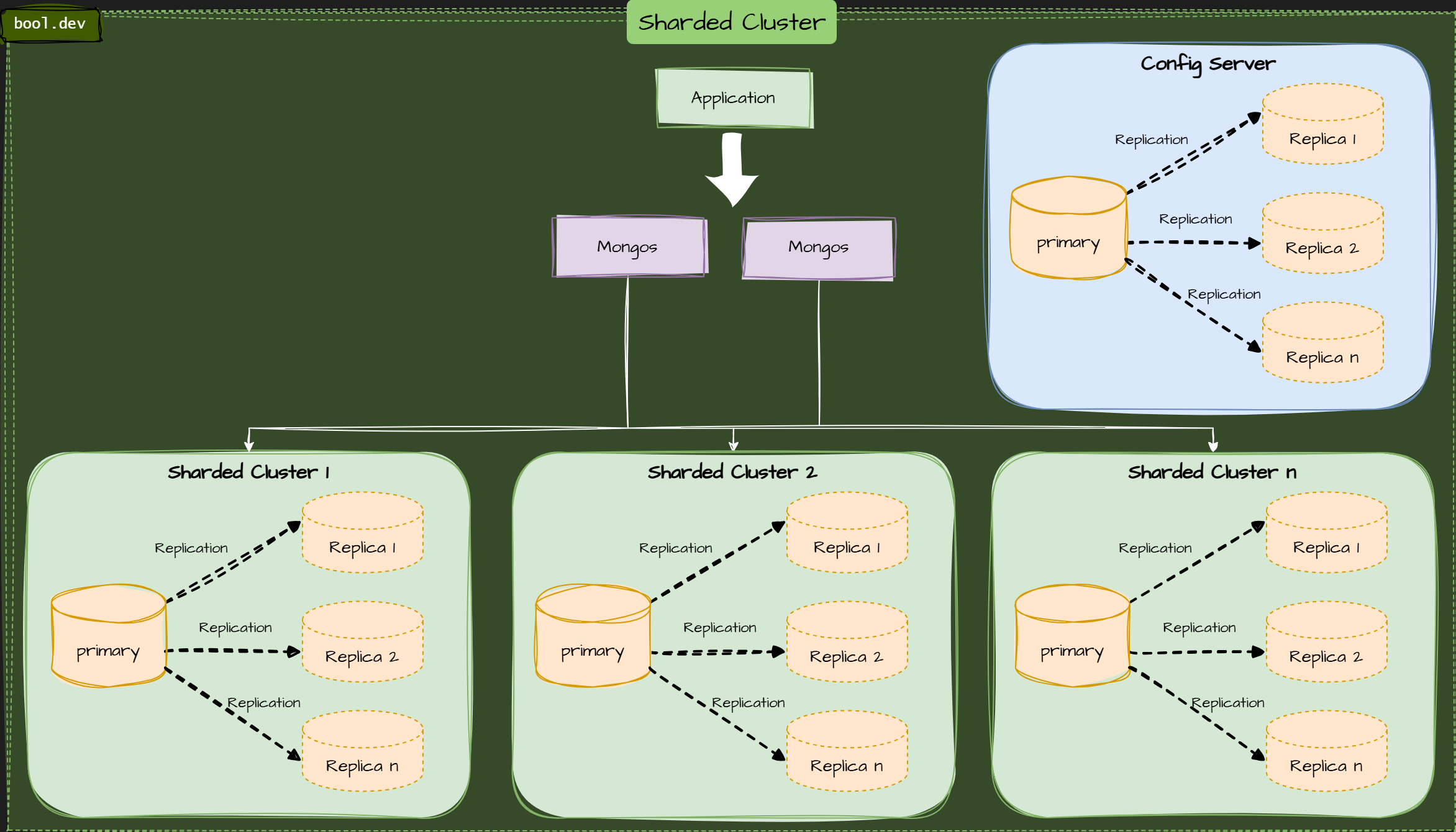
A Sharded Cluster means that each shard (which can also be a replica set) handles a portion of the data. Each request, whether read or write, is served by the cluster where the data resides. This means that both read and write performance can be increased by adding more shards to a cluster. Which document resides on which shard depends on each collection's shard key. It should be chosen in a way that the data can be evenly distributed on all clusters, and so that it is clear for the most common queries where the shard-key resides (example: when you frequently query by user_name, your shard key should include the field user_name So each query can be delegated only to the shard that contains that document.
The drawback is that the fault-tolerance suffers. When a shard in the cluster goes down, any data on it becomes inaccessible. For this reason, each member of the cluster should also be a member of the replica set. This is not required.
What .NET engineers should know:
- 👼 Junior: Replica sets = copies of data for failover. Sharding = split data for scaling.
- 🎓 Middle: Use replica sets for HA, and sharding when collections become too large or queries get too heavy.
- 👑 Senior: Know shard keys, balancing strategies, query routing, and how replication + sharding interact under heavy load.
❓ How does MongoDB achieve horizontal scalability?
MongoDB scales horizontally through sharding. Sharding splits a big collection into smaller chunks and spreads them across multiple machines. A routing layer (mongos) decides which shard should handle each query based on the shard key. As data grows, MongoDB automatically balances chunks between shards to keep the load even.

How it works in MongoDB:
- Mongo: Pick a shard key. The field that defines how documents are distributed.
- Data gets partitioned into ranges or hashed buckets. Each chunk belongs to a shard.
- Queries go through mongos. It routes to the correct shard or, if needed, to all shards.
- Balancer moves a chunk. If shards become unbalanced, MongoDB redistributes data.
What .NET engineers should know:
- 👼 Junior: MongoDB scales by sharding, splitting data across many machines.
- 🎓 Middle: Understand shard keys, routing through mongos, and chunk balancing.
- 👑 Senior: Choose stable shard keys, design query patterns around them, avoid scatter-gather queries, and plan for rebalancing under real traffic.
📚 Resources: Sharding MongoDB
❓ How do you identify and fix slow queries?
You start by checking what MongoDB is actually doing under the hood. Slow queries almost always come from missing indexes, bad filters, or scatter-gather queries in sharded setups.
How to identify slow queries:
- Profiler / slow query log. MongoDB logs slow operations. You inspect them to see which queries are problematic.
- Run
.explain("executionStats")to see if the query uses an index or scans the whole collection. - indexStats / dbStats. Check index usage and collection size to spot inefficient lookups.
- Performance dashboards. Atlas or self-hosted monitoring shows spikes, latency, and hot collections.
How to fix slow queries:
- Add the right index. Most slow queries disappear after adding a proper index on the filter or sort fields.
- Use compound indexes. Order of fields matters: equality > sort > range.
- Avoid unbounded queries. Limit scans, use pagination, and avoid regex without a prefix.
- Rewrite queries. Push filtering earlier, remove unnecessary projections, avoid $where and heavy JS ops.
- Fix sharding issues. Choose a shard key that avoids scatter-gather queries.
Simple example:
db.users.find({ email: "a@b.com" }).explain("executionStats")What .NET engineers should know:
- 👼 Junior: Use explain() and add missing indexes.
- 🎓 Middle: Tune queries, use compound indexes, and understand how MongoDB executes filters and sorts.
- 👑 Senior: Diagnose shard-level issues, avoid scatter queries, analyze profiler output, and design schemas that query efficiently at scale.
📚 Resources:
❓ How do you enforce schema validation with JSON Schema?
We enforce schema validation at the collection level using the $jsonSchema operator. While MongoDB is fundamentally schema-less, this feature allows us to apply database-side rules that reject documents failing validation, preventing garbage data from entering the system.
The validation is applied via the validator field when you create or modify a collection (db.createCollection or db.runCommand({ collMod: ... })).
MongoDB Shell Example:
db.createCollection("products", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["name", "price", "sku"],
properties: {
price: {
bsonType: "decimal",
minimum: 0.01
},
sku: {
bsonType: "string",
// Use regex for pattern matching (e.g., must be 8 digits)
pattern: "^[0-9]{8}$"
}
}
}
},
validationAction: "error",
validationLevel: "strict"
});- What .NET engineers should know:
- 👼 Junior: Understands that while C# models help, we use
$jsonSchemato enforce structure directly in MongoDB. - 🎓 Middle: Knows the basic
$jsonSchemasyntax and can usecollModto apply validation rules to an existing production collection. - 👑 Senior: Understands the performance trade-off (validation adds overhead) and strategically uses
validationAction: "warn"orvalidationLevel: "moderate"during data migration or when dealing with legacy documents.
❓ What’s your approach to managing extensive collections or time-series data?
For extensive collections, the architectural core is Sharding. We distribute data across multiple servers/shards to scale writes and manage the working set size. The most critical decision is choosing a Sharding Key that ensures even distribution and prevents "hot shards" (avoiding a key like CreatedAt, which is monotonically increasing).
For time-series data, we use the dedicated Time Series Collections (available since Mongo 5.0).
- Optimization: This feature automatically organizes and compresses time-stamped data, similar to a columnar store, yielding significantly lower disk usage and faster time-range queries than manual "bucketing" patterns.
- Maintenance: We set up TTL (Time To Live) indexes on the timestamp field to automatically expire and delete historical data that falls outside our retention policy (e.g., keeping only 90 days of raw sensor data).
MongoDB Shell Example (Time Series & TTL):
// 1. Create a native Time Series Collection
db.createCollection("telemetry", {
timeseries: {
timeField: "ts",
metaField: "deviceId",
granularity: "hours"
}
});
// 2. Add a TTL index for 90-day retention
db.telemetry.createIndex(
{ "ts": 1 },
{ expireAfterSeconds: 90 * 24 * 60 * 60 }
);What .NET engineers should know:
- 👼 Junior: Understands that extensive data is split across servers (sharding) and old data can be auto-deleted (TTL).
- 🎓 Middle: Knows that manual time bucketing was once necessary but that we now prefer native Time Series Collections for performance and storage efficiency.
- 👑 Senior: Mandates the use of native Time Series Collections for any new workload and can design a compound sharding key that balances query isolation with write distribution.
📚 Resources: MongoDB Sharding
Cosmos DB Interview Questions and Answers
❓ How does Azure Cosmos DB differ from MongoDB and DynamoDB?
- Cosmos DB is a multi-model, globally distributed database with turnkey replication, SLAs, and multiple APIs (Core SQL, MongoDB API, Cassandra API, Gremlin, Table).
- MongoDB is a document database you run or manage yourself.
- DynamoDB is AWS’s key-value/document store optimized for single-table design and massive scale.
What .NET engineers should know:
- 👼 Junior: Cosmos is global + multi-model; MongoDB is document; DynamoDB is key-value/document with partition keys.
- 🎓 Middle: Cosmos offers tunable consistency, auto-indexing, and RUs; DynamoDB requires careful key design; MongoDB offers rich queries but needs index tuning.
- 👑 Senior: Choose based on workload:
❓ What is a partition key in Cosmos DB, and what happens if you pick a bad one?
In Cosmos DB, the partition key determines how data is distributed across physical partitions. Each unique key value group relates items together. This helps Cosmos DB scale horizontally, distributing data and requests evenly across multiple servers.
If you choose a poor partition key, you risk creating hot partitions — those that receive the majority of traffic or data. This causes slow queries, throttling, and uneven performance, even when the overall system still has capacity.
Good partition key qualities:
- High cardinality (many unique values).
- Even distribution of reads and writes.
- Supports ordinary query filters (
WHERE customerId = ...).
What .NET engineers should know:
- 👼 Junior: Should know the partition key decides how data is spread across servers.
- 🎓 Middle: Should understand how partition keys affect query performance and scalability, and recognize symptoms of a “hot” partition.
- 👑 Senior: Should design data models with partition keys aligned to workload patterns, test distribution early, and consider synthetic keys (like
region#customerId) for better balance.
📚 Resources: Partitioning and horizontal scaling in Azure Cosmos DB
❓ What is the change feed in Cosmos DB, and what are some cool things you can build with it?
The change feed in Cosmos DB is akin to a real-time event log of everything that occurs in your container. Whenever a document is created or updated, the change feed captures the change in order, so your app can respond to it rather than constantly polling the database.

It’s basically a built-in event stream for your data.
How it works:
- Every insert or update is appended to the change feed.
- You can read these changes in order, by partition key range.
- It’s available through the SDK, Azure Functions trigger, or Change Feed Processor library.
- Deletes aren’t included by default (but can be tracked using soft-delete markers).
Example:
Imagine an e-commerce system:
- A new order is written toCosmos DB.
- The change feed picks it up.
- A background processor updates analytics, sends a confirmation email, and triggers fulfillment — all asynchronously.
Usage:
var processor = container
.GetChangeFeedProcessorBuilder<Order>("orderProcessor", async (changes, token) =>
{
foreach (var order in changes)
Console.WriteLine($"New order received: {order.Id}");
})
.WithInstanceName("Worker1")
.WithLeaseContainer(leaseContainer)
.Build();
await processor.StartAsync();What you can build using this approach:
- Event-driven pipelines: Trigger downstream services when data changes.
- Real-time analytics: Stream updates to dashboards or Azure Synapse.
- Search indexing: Automatically sync new data to Elasticsearch.
- Caching and projections: Keep Redis or read models up to date without polling.
- Audit logs: Track document changes for compliance and debugging purposes.
What .NET engineers should know:
- 👼 Junior: Should see the change feed tracks, inserts, and updates in Cosmos DB.
- 🎓 Middle: Should understand how to use the Change Feed Processor and Azure Functions trigger to handle events.
- 👑 Senior: Should design complete event-driven systems using the change feed — integrating it with queues, search indexes, or analytics pipelines, ensuring idempotency and scalability.
📚 Resources: Change feed in Azure Cosmos DB
❓ How would you explain the different consistency levels in Cosmos DB, and when would you choose one over another?
Cosmos DB offers five consistency levels, giving you a trade-off between performance, latency, and data freshness:
| Level | Guarantees | When to use |
|---|---|---|
| Strong | Always latest data | Financial transactions, order confirmations |
| Bounded staleness | Slight delay allowed | Real-time dashboards, collaboration |
| Session | Read-your-own-writes | Most web/mobile apps |
| Consistent prefix | Ordered but possibly stale | Messaging feeds |
| Eventual | Eventually consistent | Analytics, activity streams |
What .NET engineers should know:
- 👼 Junior: Should know consistency defines how “fresh” the data you read is after a write.
- 🎓 Middle: Should understand the five levels, trade-offs between accuracy and latency, and why Session is the default.
- 👑 Senior: Should design multi-region and high-scale systems choosing consistency per scenario, possibly mixing levels (e.g., Strong for payments, Eventual for logs).
📚 Resources: Consistency levels in Azure Cosmos DB
❓ How does Cosmos DB charge based on Request Units (RUs), and how can you optimize costs?
Cosmos DB uses Request Units (RUs) as a unified performance and pricing currency. They abstract the underlying system resources—CPU, memory, and IOPS—consumed by any database operation.
A baseline Point Read (fetching a single 1 KB item by ID and Partition Key) costs 1 RU. All other operations (writes, complex queries, indexing) incur proportional costs.
Cost Optimization Strategies
Optimization is focused on reducing RU consumption and efficiently managing provisioned throughput.
1. Optimize RU Consumption (The Code/Design)
- Avoid Cross-Partition Queries: The single biggest RU killer. Always include the Partition Key in your query filters to ensure the query hits only one logical partition.
- Tune Indexing Policy: By default, Cosmos DB indexes everything, which increases write and storage RU costs. Exclude properties you never query on or filter against.
- Use Point Reads: Always fetch items by ID and Partition Key (costing ~1 RU) instead of running a
SELECT * WHERE id = 'x'query (which costs more). - Right-size Items: For large documents (e.g., 100 KB+), consider storing large binaries (like images) in Azure Blob Storage and saving only the reference URL in Cosmos DB.
- Weaker Consistency: Using
SessionorEventualconsistency costs significantly fewer RUs for read operations thanStrongconsistency. Use the lowest level your application can tolerate.
2. Optimize Provisioned Throughput (The Configuration)
- Choose the Right Mode: Use Serverless for dev/test environments. Use Autoscale for production unless you have a perfectly flat, predictable workload (in which case use standard Provisioned).
- Use TTL (Time To Live): Automatically delete old, irrelevant data (such as logs or session history) to reduce storage costs and keep your indexes smaller, thereby lowering write RUs.
- Reserved Capacity: For large, long-term workloads with a stable RU requirement, purchase Reserved Capacity (1 or 3 years) for a significant discount on the provisioned RU/s rate.
- Measure and Adjust: Monitor the Max Consumed RU/s and the Throttled Request Count daily using Azure Monitor. Set alerts for throttling (
429errors) to know when you need to scale up, and review consumption to scale down during quiet periods (especially for standard Provisioned throughput)
❓ How do you design for multi-region writes and geo-replication?
It's a two-part approach: Enabling Replication and designing for Conflict Resolution.
Replication & Latency
- Geo-Replication: Add multiple regions to your account for low-latency reads and disaster recovery. Cosmos DB handles the replication automatically.
- Multi-Region Writes: Set the account property to allow writes in all regions. This achieves the lowest possible global write latency.
Conflict Resolution
Multi-write introduces write conflicts (when two regions update the same document). We must choose a policy:
| Policy | Mechanism | Use Case |
|---|---|---|
| Last Write Wins (LWW) | Default. The write with the highest system timestamp (_ts) is accepted; the other is discarded. | Simple, high-volume, non-critical data (e.g., IoT, logging). |
| Custom Stored Procedure | You define JavaScript logic that runs on conflict detection to merge or resolve changes based on business rules. | Critical business logic (e.g., merging shopping carts, complex transactions). |
What .NET engineers should know:
- 👼 Junior: Geo-replication is for global speed/safety; multi-write means faster writes but requires conflict handling.
- 🎓 Middle: Knows clients must specify the preferred region and that LWW is the default way conflicts are resolved.
- 👑 Senior: Can implement and debug a Custom Conflict Resolution Stored Procedure for complex business requirements.
❓ How would you model time-series data in Cosmos DB?
Since Cosmos DB doesn't have native time-series collections, we use the Bucketing (or Binning) Pattern to optimize for high-speed sequential writes and efficient time-range queries.
C# Example (Bucket Document):
public class DeviceTimeBucket
{
// Partition Key: e.g., "S101"
public string deviceId { get; set; }
// Document ID: e.g., "S101_20251125"
public string id { get; set; }
// Array of small reading objects.
public List<Reading> Readings { get; set; }
}What .NET engineers should know:
- 👼 Junior: Understands that you must batch readings into a bigger document to reduce RU consumption.
- 🎓 Middle: Knows the Entity ID should be the Partition Key to prevent expensive cross-partition queries for device history.
- 👑 Senior: Designs the Bucket ID (
idproperty) strategically to control the bucket size, and mandates the use of Patch Operations for appending data to minimize write RUs
📚 Resources:
DynamoDB Interview Questions and Answers
❓ What is DynamoDB, and how is it different from MongoDB?
DynamoDB is AWS’s fully managed, key-value/document store built for predictable performance at massive scale. MongoDB is a flexible document database that you model like traditional collections. DynamoDB forces you into a single-table, access-pattern-first design; MongoDB lets you structure documents more freely.
Key differences:
Data modeling
- DynamoDB: single-table design, everything shaped around partition key + sort key and access patterns.
- MongoDB: multiple collections, flexible schema, deep document structure.
Indexing
- DynamoDB: you choose PK/SK; add GSIs/LSIs for alternate query paths.
- MongoDB: rich secondary indexes, compound indexes, text search.
Scalability model
- DynamoDB: strict provisioned or on-demand read/write capacity; throughput tied to partition distribution.
- MongoDB: scales via replica sets + sharding, but you manage more complexity.
Write/read behavior
- DynamoDB: predictable low latency, requires careful key design (avoid hot partitions).
- MongoDB: more flexible queries but less predictable at extreme scale.
Event-driven patterns
- DynamoDB Streams: built-in change feed to trigger Lambda functions.
- MongoDB: Change Streams: exist but require replica sets/sharded clusters.
What .NET engineers should know:
- 👼 Junior: DynamoDB uses PK/SK and a single-table approach; MongoDB is flexible document storage.
- 🎓 Middle: Use GSIs/LSIs, manage read/write capacity, and avoid hot partitions; MongoDB relies on indexes and collections.
- 👑 Senior: Build event-driven systems with Streams, design access-pattern maps, tune partition keys, and use GSIs strategically for scalable reads.
❓ What is the primary key structure in DynamoDB (partition key vs. sort key)?
The DynamoDB primary key (PK) is the core mechanism for both data distribution and querying. It must be unique and is composed of one or two attributes: the Partition Key and the optional Sort Key.
Partition Key (Hash Key)
- Determines the physical location (partition) where the item is stored. DynamoDB hashes this value, and the result directs read and write requests to a specific machine.
- Uniqueness: If you only use a Partition Key, its value must be unique across the entire table.
- Querying: All highly efficient
GetItem(single item lookup) andQueryoperations must include the Partition Key value.
Sort Key (Range Key)
- Function: Defines the storage order of items that share the same Partition Key. All items within a partition are stored in sequential order by the Sort Key value.
- Uniqueness: The Sort Key does not have to be unique across the table, but the combination of Partition Key + Sort Key must be unique. This allows for one-to-many relationships (e.g.,
User IDas Partition Key,Order IDas Sort Key). - Querying: Allows for efficient range queries and sorting within a single partition (e.g., fetch all orders for a user where the
Order Dateis between X and Y, or where theOrder IDbegins with 'Invoice').
What .NET engineers should know:
- 👼 Junior: The primary key is either a single Partition Key (PK) or a composite of PK + Sort Key (SK).
- 🎓 Middle: The PK determines the data distribution, and the SK orders the items within each partition, enabling efficient range queries.
- 👑 Senior: Design keys for access patterns first, and use composite PK/SK values to consolidate different entity types into a single item collection.
📚 Resources:
- 📽️ AWS DynamoDB Schema Design
- Everything you need to know about DynamoDB Partitions
- 📽️ Amazon DynamoDB Fundamentals: Understanding Tables, Items, and Attributes for Effective NoSQL Database Design
❓ How do Global Secondary Indexes (GSI) and Local Secondary Indexes (LSI) differ?
The primary difference is that Local Secondary Indexes (LSI) share the same Partition Key as the main table, while Global Secondary Indexes (GSI) use a completely independent Partition Key. This affects everything from data distribution to capacity.
| Feature | Local Secondary Index (LSI) | Global Secondary Index (GSI) |
|---|---|---|
| Partition Key | Must match the base table. | Independent of the base table. |
| Sort Key | Must be different from the base table's Sort Key. | Can be any attribute (even the same as the base table). |
| Uniqueness | The combination of Base PK + LSI SK must be unique. | The combination of GSI PK + GSI SK must be unique within the GSI. |
| Capacity | Inherits Read/Write Capacity from the base table. | Has its own independent Read/Write Capacity provisioned. |
| Availability | Created only when the table is created; cannot be added/modified later. | Can be created, modified, or deleted at any time after the table is created. |
| Data Scope | Queries are limited to items that share the same Partition Key (local scope). | Queries can span all data in the base table (global scope). |
| Impact on Writes | Writes consume base table capacity only. | Writes consume base table capacity PLUS GSI capacity (replication cost). |
When to use each?
- Use LSI: when you have an existing primary access pattern (PK) but need a secondary way to query within that partition (e.g., to retrieve all customer orders by date, where the customer ID is the Partition Key).
- Use GSI: When you need an entirely new access pattern that requires a different Partition Key (e.g., querying orders by
StatusorZipCodeinstead of byCustomerID). This is the most flexible and common secondary index.
What .NET engineers should know:
- 👼 Junior: LSI is for querying inside the leading data group; GSI is for querying across the entire dataset using a different key.
- 🎓 Middle: Knows that LSI cannot be added later, which is a significant design constraint, and GSI requires provisioning its own dedicated RUs.
- 👑 Senior: Understands that GSI writes are eventually consistent, impacting fresh reads, and manages the GSI's separate capacity units to avoid throttling the primary table on heavy write load.
📚 Resources: General guidelines for secondary indexes in DynamoDB
❓ What are best practices for choosing a partition key in DynamoDB?
The partition key decides how DynamoDB spreads your data and load. If it’s bad, one hot partition will kill your performance. If it’s good, DynamoDB scales almost linearly.
What actually works:
- High cardinality. Many unique values, so data spreads evenly across partitions.
- Even traffic distribution. No “celebrity keys” that get 99% of traffic.
Avoid userId = 1 for everything. - Stable key. Shouldn’t change during the item’s lifetime.
- Access patterns first. DynamoDB is read-pattern driven. Choose a key that matches your most common Get/Query operations.
- Use composite keys when needed. A partition key and a sort key let you group related items without overloading a single partition.
- Avoid timestamps as PK. They create hot partitions. Use them as sort keys instead.
- When in doubt: hash something. If natural keys are uneven, hash them. Same logical grouping, better distribution.
For example:
- PK = UserId
- SK = OrderDate
Let's you query all orders for one user efficiently without hot partitions.
What .NET engineers should know:
- 👼 Junior: The Partition key must be unique enough and spread the load evenly.
- 🎓 Middle: Design PK/SK based on read patterns and avoid hot keys; use composite keys smartly.
- 👑 Senior: Model full access patterns, predict traffic hotspots, use sharding/hashing when needed, and test distribution under load.
📚 Resources:
- Partitions and data distribution in DynamoDB
- 📽️ AWS re:Invent 2018: Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB (DAT401)
- NoSQL design for DynamoDB
❓ How would you design a one-to-many or many-to-many relationship in DynamoDB?
In DynamoDB, you do not join. You design keys so that one query returns the slice of data you need.
Relationships are modeled by how you group items by partition keys and how you use sort keys and Global Secondary Indexes (GSIs).
One-to-many
Option 1: separate items, same partition
- Put parents and children in the same partition, distinguished by the sort key.
- Pattern: PK = ParentId, SK = TYPE#Id.
Example: a user and their orders.
Item 1 (user):
PK = USER#123
SK = USER#123Item 2 (order):
PK = USER#123
SK = ORDER#2024_0001To get all orders for user 123:
Query PK = USER#123 and SK begins_with("ORDER#").Option 2: embed children
If there are a few children and they are small and stable, store them as an array in the parent item.
Simple, but bad if the list grows large or you update children often.
Many-to-many
Use a link (junction) table pattern.
Example: users and groups.
Link items:
PK = USER#123, SK = GROUP#10
PK = USER#123, SK = GROUP#20
PK = USER#456, SK = GROUP#10Now:
To get all groups for a user:
Query PK = USER#123.To get all users in a group: create a GSI with GSI1PK = GROUP#10, GSI1SK = USER#123 etc, and query by group.
Item shape for link:
PK = USER#123
SK = GROUP#10
GSI1PK = GROUP#10
GSI1SK = USER#123What .NET engineers should know:
- 👼 Junior: Know that you model relationships with partition and sort keys, not joins; one-to-many often shares the same PK.
- 🎓 Middle: Use patterns like PK = parent, SK = child type, and a junction table with GSIs for many-to-many.
- 👑 Senior: Design access patterns first, choose between embedding vs separate items, and use GSIs and prefixes to keep queries fast and scalable.
📚 Resources: Using Global Secondary Indexes in DynamoDB
❓ How do you model access patterns before designing your tables in DynamoDB?
We use Access Pattern Driven Design, which is the inverse of relational modeling. We prioritize query performance over storage normalization, focusing on eliminating expensive Scan operations.
The Modeling Process
- List All Queries: Define every single
read,write,update, anddeletequery the application will ever need (e.g., "Get User by Email," "List open orders for customer," "Update inventory stock"). - Map to Keys: For each query, determine the required Partition Key (PK) and Sort Key (SK). The PK must be known to execute the query efficiently.
- Identify Bottlenecks: Look for queries that cannot be satisfied by the main table's PK/SK. These necessitate Global Secondary Indexes (GSIs), each optimized for a specific secondary query pattern.
- Single Table Design: Finally, consolidate all entities (Users, Orders, Items) into a single table definition. The PK/SK values become composite/prefixed strings (e.g.,
USER#123,ORDER#456) to differentiate item types within the partition.
Example:
Access patterns
- Get user
- Get the user’s orders
- Find user by email
Query
- PK = USER#123
- SK = USER#123 or ORDER#timestamp
- GSI1PK = EMAIL#foo@bar.com
What .NET engineers should know:
- 👼 Junior: DynamoDB design starts from access patterns, not tables.
- 🎓 Middle: Derive PK/SK and GSIs from the exact queries the app needs.
- 👑 Senior: Build a full access-pattern map, validate each query path, avoid scans, and design keys that stay scalable under real traffic.
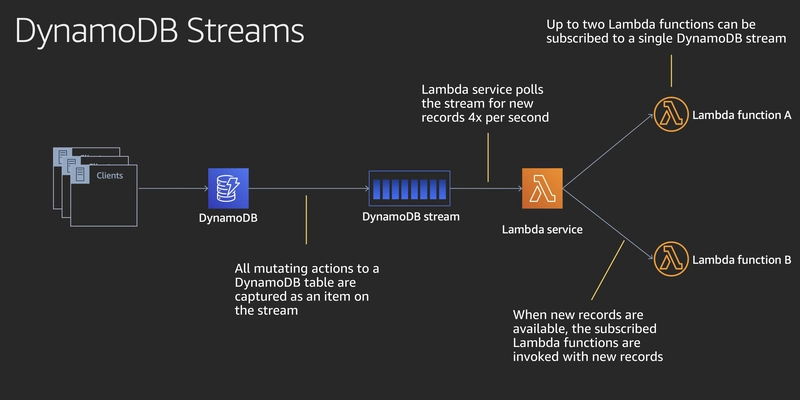
❓ What is DynamoDB Streams, and how can it be used with AWS Lambda?
DynamoDB Streams is a time-ordered sequence of changes (a log) to the data in a DynamoDB table. It captures every Create, Update, and Delete operation in near real-time.
How it works:
- You enable Streams on a table.
- Every item-level change (INSERT, MODIFY, REMOVE) is captured.
- Lambda is triggered with batches of these changes.
- Your Lambda code handles each record: sync, transform, audit, notify, and so on.
Common use cases:
- Event-driven updates (sync DynamoDB to Elasticsearch/Opensearch)
- Audit logging
- Cache invalidation (Redis, CloudFront)
- Sending notifications
- Materialized views/read models
- Triggering workflows after writes
What .NET engineers should know:
- 👼 Junior: DynamoDB Streams is a log of all changes; Lambda uses it to run code immediately when data changes.
- 🎓 Middle: Understands that Lambda automatically handles batching, ordering, and checkpointing, ensuring changes are processed exactly once (if processing is idempotent).
- 👑 Senior: Focuses on optimizing the stream record view (e.g., using
KEYS_ONLYif possible) to reduce the stream's payload size and lower Lambda's invocation cost.
📚 Resources:
❓ How do you handle pagination and query filters efficiently in DynamoDB?
Efficient pagination and filtering in DynamoDB are handled using Query with Limit and ExclusiveStartKey for paging, and by optimizing the Sort Key for filtering. So, we need to minimize the use of non-key filters.
Efficient pagination:
- Use Query, not Scan. Query reads only one partition. Scan reads the whole table. Scans don’t scale.
- Use
LastEvaluatedKey. The API returns a pointer to the next page. You pass it back on the subsequent request. No offsets, no skips. - Sort with
SK. If you want recent items first, buildSK = TYPE#timestamp. DynamoDB automatically returns items in SK order.
What .NET engineers should know:
- 👼 Junior: Pagination uses a token (
LastEvaluatedKey), not page numbers. Filters should use the Sort Key. - 🎓 Middle: Understands that using
FilterExpressionconsumes RUs for all scanned data before filtering, making it expensive for large datasets. - 👑 Senior: Designs the Sort Key intentionally as a composite string (e.g.,
STATUS#DATE) to support multiple filtering access patterns efficiently within a singleQuerycall.
📚 Resources: Paginating table query results in DynamoDB
❓ How would you implement optimistic concurrency control in DynamoDB?
I would implement optimistic concurrency control (OCC) in DynamoDB using a Version Number attribute and Conditional Writes. This ensures that an update succeeds only if no other client has changed the item's version since it was last read.
Implementation Steps
- Version Attribute: Add a numeric or counter attribute (e.g.,
version) to every item in the table. Initialize it to1on creation. - Read: When a client reads an item, they retrieve both the item data and the current
versionnumber. - Update: When the client attempts to write the item back (using
UpdateItemorPutItem): - They increment the version number by one in the item payload.
- They include the Conditional Expression
version = :current_version(where:current_versionis the original version they read in Step 2).
What .NET engineers should know:
- 👼 Junior: OCC uses a
versionnumber and makes the update conditional to prevent accidental overwrites. - 🎓 Middle: Knows that the
ConditionExpressionis the mechanism, and that failure results in aConditionalCheckFailedExceptionthat must be caught and handled. - 👑 Senior: Understands that conditional writes consume RUs even if they fail, and designs the retry logic carefully (with backoff) to prevent unnecessarily stressing the table.
📚 Resources: Condition and filter expressions, operators, and functions in DynamoDB
❓ What are the limitations of transactions in DynamoDB?
DynamoDB's transaction model (TransactWriteItems and TransactGetItems) provides full ACID properties, but it has several limitations that impact scale, cost, and design flexibility compared to standard single-item operations.
Key Limitations
- Item Limit: A single transaction is limited to 10 distinct items. This restricts transactions to narrow, fine-grained operations.
- Size Limit: The total size of the transaction request (the sum of all item payloads) cannot exceed 4 MB.
- Cross-Region Limit: Transactions are only supported within a single AWS region. You cannot execute a transaction across tables in different regions.
- Cost: Transactions consume double the standard Read/Write Capacity Units (RUs). A transactional write operation consumes two write RUs: one for the prepare phase and one for the commit phase. This means a higher cost for low-latency operations.
- Latency: Transactional operations inherently introduce additional network round-trip time and coordination overhead, resulting in higher latency and lower overall throughput.
- No Support for GSIs/LSIs: Transactions can only target base table items. You cannot include operations on Global Secondary Indexes (GSIs) or Local Secondary Indexes (LSIs) directly within a transaction.
Because of these limitations, DynamoDB's primary design philosophy is to avoid transactions whenever possible. You should favor single-item operations, use Conditional Expressions for optimistic concurrency (which is cheaper), or model the data via Single Table Design to make the necessary related updates fall within a single item, avoiding transactions entirely.
What .NET engineers should know:
- 👼 Junior: Transactions are limited and slower; they’re not like SQL transactions.
- 🎓 Middle: Know the 25-item and 4 MB limits, higher latency, and retry behavior.
- 👑 Senior: Design systems that avoid large transactions, use idempotent writes, handle contention, and choose event-driven patterns instead of heavy cross-item atomicity.
📚 Resources: Amazon DynamoDB Transactions: How it works
Redis Interview Questions and Answers

❓ Let's talk about caching. How would you use Redis in a .NET app to take load off your primary database?
Redis is ideal for reducing database load by caching frequently accessed or computationally expensive data in memory. Instead of hitting your SQL or Cosmos DB every time, you can read data directly from Redis
In a .NET app, the standard approach is to cache query results, API responses, or session data using the Microsoft.Extensions.Caching.StackExchangeRedis package.
Example:
var cacheKey = $"user:{userId}";
var user = await cache.GetStringAsync(cacheKey);
if (user == null)
{
// Cache miss — fetch from DB
user = await dbContext.Users.FindAsync(userId);
// Save to Redis for 10 minutes
await cache.SetStringAsync(cacheKey,
JsonSerializer.Serialize(user),
new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(10)
});
}
else
{
user = JsonSerializer.Deserialize<User>(user);
}Here, Redis acts as a read-through cache — your app first checks the cache; if the data isn’t there, it falls back to the database and stores the result.
What .NET engineers should know:
- 👼 Junior: Should understand Redis stores data in memory and can reduce database queries by caching hot data.
- 🎓 Middle: Should know how to implement
IDistributedCachein .NET, choose proper expiration policies and handle cache invalidation. - 👑 Senior: Should design layered caching (in-memory + Redis), handle cache stampede scenarios, and measure hit ratios to balance freshness vs performance.
📚 Resources: Caching in .NET
❓ What are strategies for data synchronization between Redis and the primary data source?
Here are common cache strategies used in real-world .NET systems:
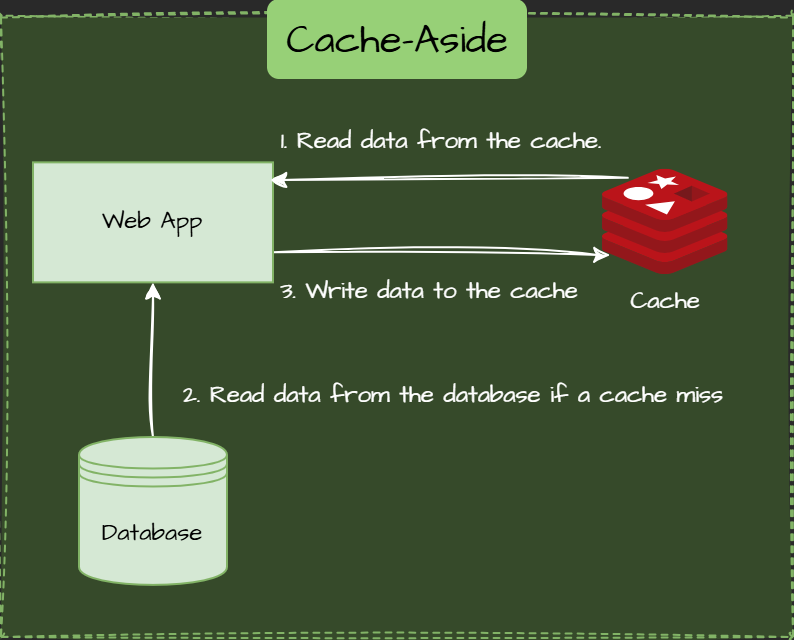
Cache-Aside (Lazy Loading) Pattern
Cache-aside loads data into the cache on demand. If the data isn't in the cache (a cache miss), the application fetches it from the database, stores it in the cache, and returns it.
Read-Through Pattern
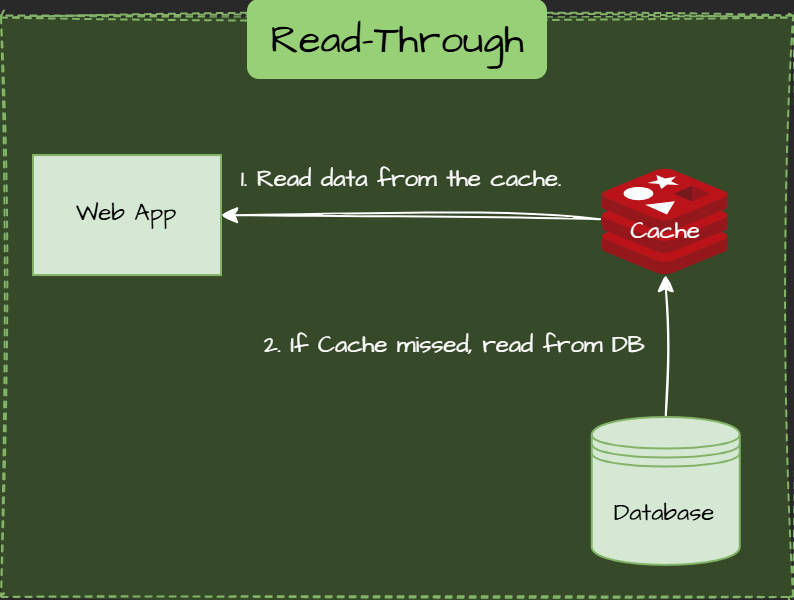
Similar to Cache-Aside, but the app doesn't interact with the database. The cache does.
Write-Through Pattern
Data is written to the cache and the database simultaneously, ensuring consistency but slightly increasing latency.
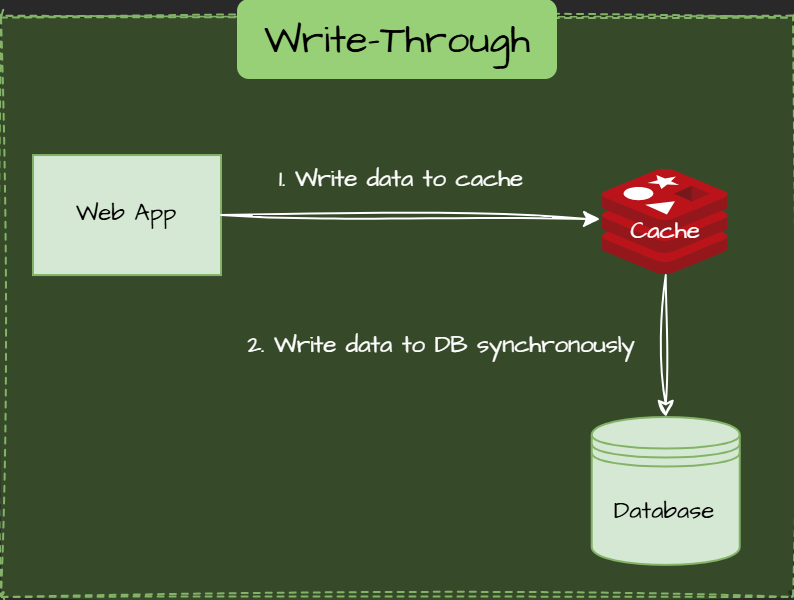
Write-Behind / Write-Back Pattern
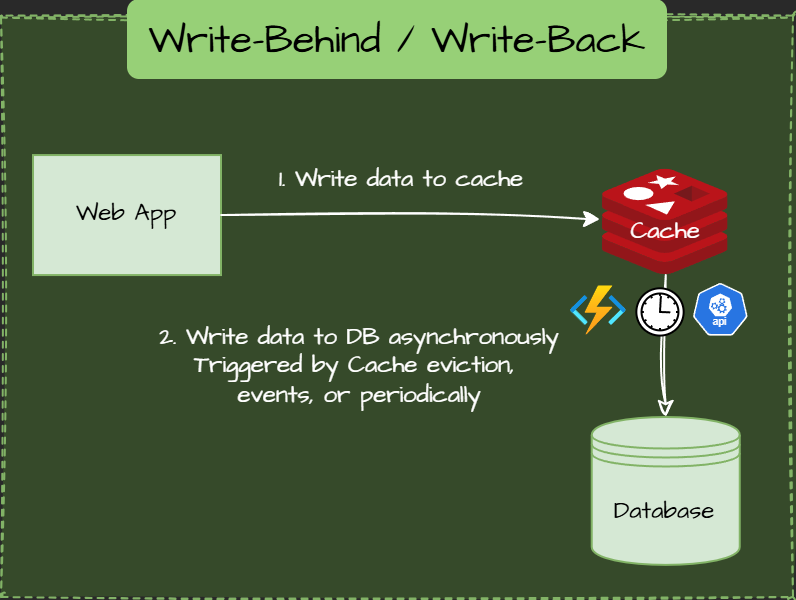
Data is written to the cache first, then asynchronously persisted to the database.
Async action is triggered periodically by cache eviction or other events.
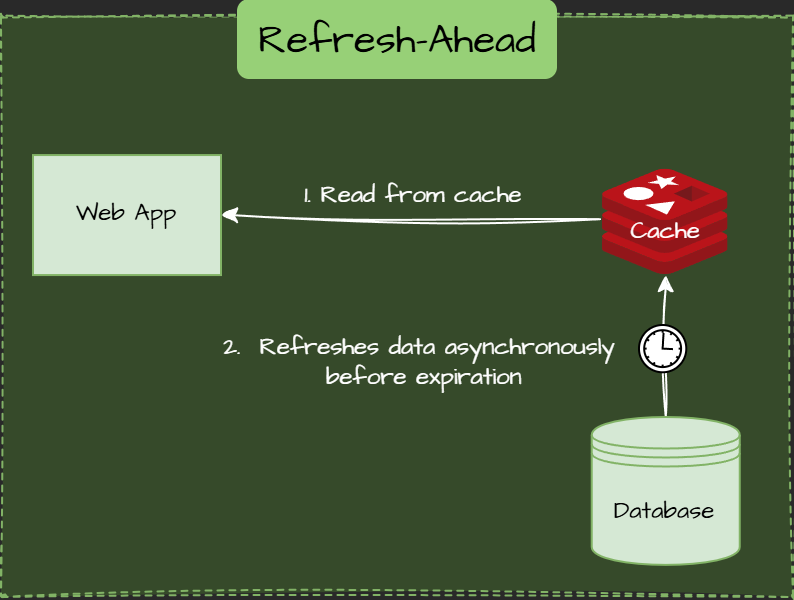
Refresh-Ahead Pattern
Cache proactively refreshes data asynchronously before expiration.
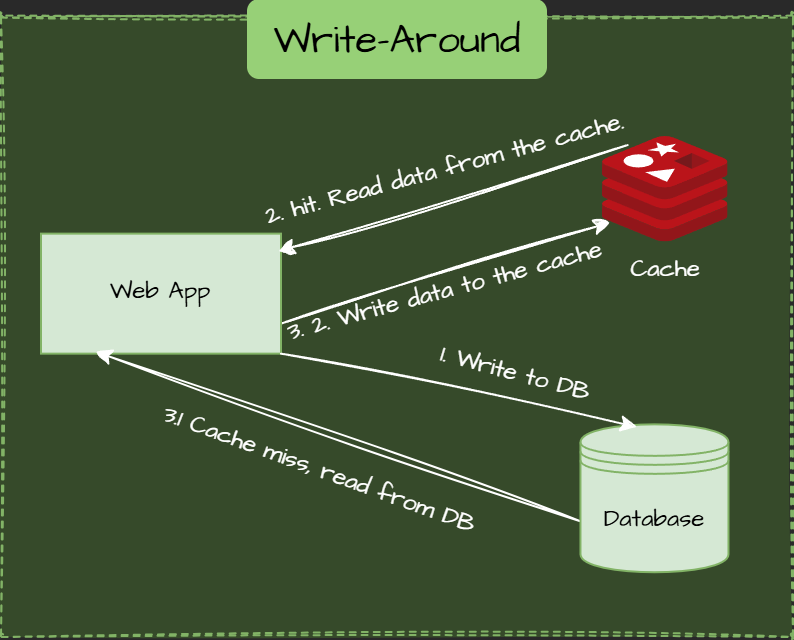
Write-Around Pattern
Write only to the database. The cache is updated only on a subsequent read (if at all).
What .NET engineers should know:
- 👼 Junior: Should know cache can get stale and must be refreshed or invalidated when data changes.
- 🎓 Middle: Should understand cache-aside pattern, TTLs, and when to use Pub/Sub for multi-instance apps.
- 👑 Senior: Should design resilient sync strategies — combining event-driven invalidation, distributed locks, and observability (e.g., cache hit ratio, stale read metrics).
📚 Resources: Mastering Caching: Strategies, Patterns & Pitfalls
❓ What is the Redis data type you'd use to implement a leaderboard, and why?
For a leaderboard — where you rank players by score — the best Redis data type is a Sorted Set (ZSET).
Sorted sets store unique elements ordered by a score. Redis automatically keeps them sorted, so you can efficiently get top players, ranks, or score ranges without extra logic in your app.
Example:
// Add or update player scores
await db.SortedSetAddAsync("leaderboard", "Alice", 1200);
await db.SortedSetAddAsync("leaderboard", "Bob", 950);
await db.SortedSetAddAsync("leaderboard", "Charlie", 1800);
// Get top 3 players
var topPlayers = await db.SortedSetRangeByRankWithScoresAsync("leaderboard", 0, 2, Order.Descending);Redis will return players sorted by their score — no manual sorting or SQL queries needed.
Why it works well:
- Sorted automatically: Rankings are maintained as scores change.
- Fast lookups: Constant-time inserts and ordered reads.
- Range queries: Easily fetch top N or players in a score range.
- Atomic updates: Updating a score automatically reorders the set.
What .NET engineers should know:
- 👼 Junior: Should know that Sorted Sets can store values with scores and keep them sorted automatically.
- 🎓 Middle: Should understand how to add/update scores with
SortedSetAddAsync()and retrieve rankings efficiently. - 👑 Senior: Should design leaderboards that handle large datasets, use pipelining or batching for updates, and combine Redis with background sync to persist scores periodically in SQL for durability.
📚 Resources: Redis sorted sets
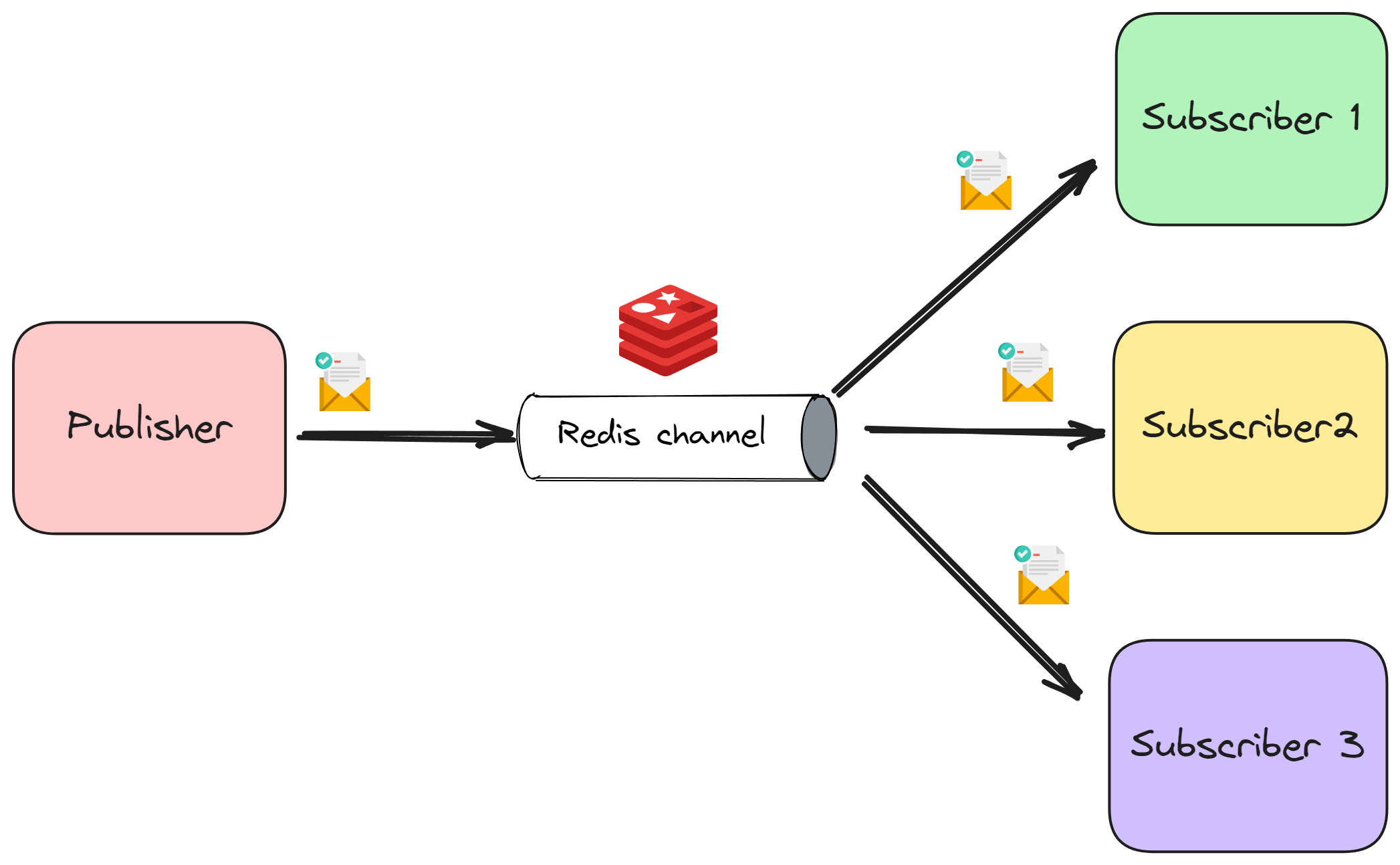
❓ Can you describe a scenario where you would use Redis Pub/Sub?
Redis Pub/Sub (Publish/Subscribe) lets services publish and subscribe to real-time messages via Redis channels. It’s perfect for lightweight, event-driven communication — when you want multiple subscribers to react instantly to something happening in another part of the system.
Common use cases:
- Real-time notifications or chat systems.
- Broadcasting cache invalidation messages across app instances.
- Coordinating background workers (e.g., trigger data refresh).
- Simple event streaming without the need for full message brokers like Kafka.
Example scenario:
Imagine a multi-instance web app that sends live notifications when someone comments on their post. When a new comment is saved, your app publishes an event to the comments channel.
All connected web servers subscribe to that channel. They receive the event and push it to online users via SignalR or WebSocket.
Example
Producer
public class Producer(ILogger<Producer> logger) : BackgroundService
{
private static readonly string ConnectionString = "localhost:5050";
private static readonly ConnectionMultiplexer Connection =
ConnectionMultiplexer.Connect(ConnectionString);
private const string Channel = "messages";
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
var subscriber = Connection.GetSubscriber();
while (!stoppingToken.IsCancellationRequested)
{
var message = new Message(Guid.NewGuid(), DateTime.UtcNow);
var json = JsonSerializer.Serialize(message);
await subscriber.PublishAsync(Channel, json);
logger.LogInformation(
"Sending message: {Channel} - {@Message}",
message);
await Task.Delay(5000, stoppingToken);
}
}
}Consumer:
public class Consumer(ILogger<Consumer> logger) : BackgroundService
{
private static readonly string ConnectionString = "localhost:5050";
private static readonly ConnectionMultiplexer Connection =
ConnectionMultiplexer.Connect(ConnectionString);
private const string Channel = "messages";
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
var subscriber = Connection.GetSubscriber();
await subscriber.SubscribeAsync(Channel, (channel, message) =>
{
var message = JsonSerializer.Deserialize<Message>(message);
logger.LogInformation(
"Received message: {Channel} - {@Message}",
channel,
message);
});
}
}Redis instantly delivers that message to all subscribers, no polling, no extra database calls.
What .NET engineers should know:
- 👼 Junior: Should know Pub/Sub allows apps to send messages instantly to all subscribers.
- 🎓 Middle: Should understand how to use
PublishAsync()andSubscribeAsync()and when to prefer it over polling or queues. - 👑 Senior: Should know Pub/Sub is fire-and-forget (no persistence) and design around that — e.g., use Redis Streams or message queues for guaranteed delivery and replay.
📚 Resources:
❓ How do you choose between RDB and AOF persistence?
The choice between RDB (Redis Database Snapshotting) and AOF (Append-Only File) depends entirely on the acceptable level of data loss and the desired recovery speed.

RDB (snapshot):
- Best for backups and fast restarts.
- Low write overhead.
- Risk: you lose anything written after the last snapshot.
AOF (append-only log):
- Replays every write; minimal data loss.
- Heavier on disk and CPU.
- Needs rewrite/compaction over time.
Recommendation
For most production systems, the best practice is to use both:
- RDB for fast full-state backups and quick disaster recovery.
- AOF is configured with
fsyncset toeverysecto achieve minimal (one-second) data loss on failure.
What .NET engineers should know:
- 👼 Junior: RDB is a snapshot (faster recovery, more loss); AOF is a command log with slower recovery, less loss.
- 🎓 Middle: Knows that AOF set to
everysecis the typical trade-off between performance and data safety - . 👑 Senior: Understands that using both mitigates the downsides: use AOF for durability and RDB for efficient remote backups, and can explain the I/O blocking risk of RDB's
fork()operation.
📚 Resources: Redis persistence
❓ What’s the difference between Redis Cluster and Sentinel?
The difference is their scope and function: Sentinel provides high availability for a single master-replica setup, whereas Redis Cluster provides scaling, partitioning, and high availability for an entire sharded dataset.

| Feature | Redis Sentinel | Redis Cluster |
|---|---|---|
| Primary Goal | High Availability (HA) / Automatic Failover. | Scalability (horizontal partitioning) and HA. |
| Data Distribution | No Sharding. All data is duplicated across all nodes (master/replicas). | Sharding (Data Partitioning). Data is split into 16384 hash slots distributed across master nodes. |
| Topology | Multiple Sentinel processes monitor one master and its replicas. | Multiple master nodes, each with zero or more replicas, all communicating via a cluster bus. |
| Client Handling | Client connects to Sentinels to discover the current master's address after a failover. | Client is aware of the entire cluster topology and routes requests directly to the correct master node based on the key's hash slot. |
| Complexity | Simpler to set up. | More complex setup; requires smart clients for routing. |
What .NET engineers should know:
- 👼 Junior: Sentinel gives failover for one server; Cluster splits data across many servers.
- 🎓 Middle: Knows that Sentinel is for HA (small to medium data), while Cluster is mandatory for large datasets that exceed a single machine's capacity.
- 👑 Senior: Understands that Cluster requires a cluster-aware client (like the
StackExchange.Redislibrary when configured for cluster) to correctly calculate the hash slot and route the request to the correct master.
📚 Resources: Understanding Redis High Availability: Cluster vs. Sentinel
❓ Can you describe use cases when Redis will be a bad choice?
Redis is speedy, but its primary nature as an in-memory, single-threaded key-value store creates specific anti-patterns, making it a poor architectural fit compared to a dedicated database or message broker.
Here are the key use cases where Redis is a bad choice:
Primary Data Storage Needing Durability
- Problem: If the primary source of truth is the Redis instance, and you need zero data loss, Redis persistence mechanisms (RDB/AOF) are inadequate on their own.
- Reasoning: Even with AOF configured for every second, you accept a risk of one second of data loss upon failure. If the application requires true durability and ACID properties, a relational database (such as PostgreSQL or SQL Server) or a durable NoSQL system (such as DynamoDB or MongoDB) is required.
2. Storing Massive Datasets Cost-Effectively
- Problem: Storing terabytes of data where cost is a significant constraint.
- Reasoning: Since Redis is an in-memory store, RAM is significantly more expensive than persistent SSD storage used by disk-backed databases. For extensive archives, analytical data, or long-term history where retrieval latency can tolerate tens of milliseconds, a cheaper, disk-based solution (such as S3, Snowflake, or a large relational database) is preferable.
3. Complex Queries or Relational Lookups
- Problem: Requiring complex joins, grouping, aggregation, or indexing across multiple data points (the core functionality of SQL).
- Reasoning: Redis is not a query engine. While the RediSearch module offers some indexing, complex, arbitrary SQL-like queries require scanning data outside the primary key, which is inefficient or impossible. If you need complex querying, use a relational database.
4. Complex Distributed Locking Logic
- Problem: Implementing highly reliable, multi-resource transactional locking that requires coordinating across multiple independent services or databases.
- Reasoning: While Redis is excellent for simple distributed locking using the Redlock principles, its locks are fundamentally advisory and time-based (TTL). For true transactional integrity across multiple systems (e.g., two-phase commit), you need a dedicated transaction coordinator or a system with native ACID support spanning the resources.
5. Large Binary Objects (BLOBs)
- Problem: Storing large files, images, or documents (e.g., 10MB+).
- Reasoning: Storing large objects quickly consumes valuable RAM, hindering Redis's ability to serve its primary function (low-latency access to frequently used keys). Large BLOBs should be stored in dedicated object stores (like Azure Blob Storage or S3), with only a reference URL stored in Redis.
What .NET engineers should know:
- 👼 Junior: Redis is bad for massive datasets, long-term storage, or strong durability.
- 🎓 Middle: Avoid Redis when you need complex queries, analytics, ACID, or cheap storage at scale.
- 👑 Senior: Evaluate workload patterns, memory footprint, failover guarantees, and choose Redis only for hot paths, caching, queues, and ephemeral state—never as your system of record.
Elasticsearch Interview Questions and Answers

❓ How does Elasticsearch differ from a traditional database in structure and purpose?
Elasticsearch is a search engine, not a general-purpose database. It’s built for fast full-text search, relevance ranking, and analytics over extensive semi-structured data.
Traditional databases focus on correctness, transactions, and structured queries; Elasticsearch focuses on speed, scoring, and distributed search.
What .NET engineers should know:
- 👼 Junior: Elasticsearch is a search engine optimized for text search, not a transactional database.
- 🎓 Middle: It uses inverted indexes, scales horizontally, and stores JSON documents.
- 👑 Senior: Know its consistency model, shard/replica design, when to use aggregations vs DB queries, and why ES should never be your primary system of record.
❓ What’s the role of index, shard, and replica in Elasticsearch?
Index
- A logical namespace, like a table.
- Holds JSON documents and mappings.
- You query an index, not individual shards.
Shard
- A physical partition of the index.
- Each shard is a Lucene engine running in the background.
- Shards let Elasticsearch scale horizontally and search in parallel.
Replica
- A copy of a primary shard.
- Used for high availability and load-balanced reads.
- If a node dies, a replica becomes the new primary.
What .NET engineers should know:
- 👼 Junior: Index is a logical collection; shards split data; replicas provide copies for failover.
- 🎓 Middle: Understand shard sizing, parallel search, and how replicas improve read throughput.
- 👑 Senior: Tune shard count, manage hot/warm architecture, handle reindexing, and plan replicas for both HA and search performance.
📚 Resources: Elasticsearch shards and replicas: A practical guide
❓ How does Elasticsearch achieve near real-time search?
Elasticsearch is “near real-time” because writes don’t become instantly searchable. Documents are written to a transaction log and an in-memory buffer, then refreshed into a Lucene segment. Search sees data only after this refresh happens. By default, ES refreshes every ~1 second.
What .NET engineers should know:
- 👼 Junior: New documents become searchable after a short delay because ES refreshes segments every second.
- 🎓 Middle: Writes go to a translog + memory buffer, then a refresh exposes them to search.
- 👑 Senior: Tune refresh intervals, avoid forced refresh, manage indexing throughput vs query freshness, and understand the cost of segment merging.
📚 Resources: Near real-time search
❓ What are analyzers, tokenizers, and filters, and why are they important?
Analyzers, tokenizers, and filters are the components of the analysis process in Elasticsearch. This process converts unstructured text into the structured format (tokens) needed to build the Inverted Index, enabling fast, relevant search.
Analyzer
- A pipeline that processes text during indexing and querying.
- It contains one tokenizer and zero or more filters.
Example: lowercase + remove stopwords + stem words.
Tokenizer
- Splits text into individual tokens (words).
Example: “New York Times” > ["new", "york", "times"].
Filters (token filters)
- Modify tokens after tokenization.
- Lowercasing, removing stopwords, stemming (“working” to “work”), and synonyms.
What .NET engineers should know:
- 👼 Junior: Analyzers break text into searchable tokens; tokenizers split text; filters clean/transform tokens.
- 🎓 Middle: Choose analyzers based on language needs, apply stemming, stopwords, and synonyms for better relevance.
- 👑 Senior: Design custom analyzers, tune them per field, control index quality, and understand how analysis affects scoring, highlighting, and multilingual search.
📚 Resources: Text analysis components
❓ What’s the difference between term and match queries?
The difference is fundamental: term queries are for exact matching on structured data, while match queries are for full-text searching on analyzed data.
Note:
You should never use a term query on a standard text field unless you fully understand its analyzed tokens, which are usually unpredictable. If you need exact matching, you must either query the field's corresponding keyword sub-field (e.g., product_name.keyword) or ensure the original field type is set to keyword.
What .NET engineers should know:
- 👼 Junior: term = exact match; match = full-text search with analysis.
- 🎓 Middle: Use
termfor keywords/IDs and match for user text; understand how analyzers affect results. - 👑 Senior: Tune analyzers, choose the right field type (keyword vs text), avoid accidental analysis on exact fields, and design queries for relevance scoring.
📚 Resources:
❓ How do you troubleshoot shard imbalance and optimize query latency?
Shard imbalance happens when some nodes carry more shard data or traffic than others. This leads to slow queries, hot nodes, and unpredictable latency. You fix it by redistributing shards, tuning the shard count, and optimizing query routing to the cluster.
How to identify shard imbalance:
- Check shard distribution. Use
_cat/shardsto see if some nodes have more/larger shard segments. - Look for hot nodes. CPU spikes, long GC pauses, or high I/O on specific nodes.
- Monitor indexing vs search load. Heavy indexing on a node that also serves queries causes latency.
- Check skewed data. If some shards contain many more documents (due to bad routing/shard key), queries will be slower on those shards.
How to fix the imbalance:
- Reroute shards
Use_cluster/rerouteor manual allocation to evenly spread shards. - Increase or decrease shard count
Too many shards = overhead.
Too few shards = no parallelism.
Aim for shard sizes of ~20–40 GB, depending on the workload. - Use shard allocation filtering
Separate hot indexes from warm/cold nodes. - Improve routing
If you use custom routing, ensure keys distribute data evenly. - Move heavy aggregation queries to dedicated nodes.
E.g., coordinate-only nodes or hot/warm architecture.
How to optimize query latency:
- Use filters before full-text queries. Filters are cached; match queries aren’t.
- Avoid heavy aggregations on huge indexes. Pre-aggregate or use rollups.
- Reduce the number of shards queried. Use routing to target specific shards when possible.
- Tune indexing/refresh rates. High refresh rates slow queries and indexing.
- Disable or reduce scoring when not needed. Use
match_bool_prefix,constant_score, orfilterqueries to skip scoring.
What .NET engineers should know:
- 👼 Junior: Too many or uneven shards slow Elasticsearch; distribute shards and reduce query load.
- 🎓 Middle: Tune shard count, fix skewed routing, apply filters, and reduce scoring to speed up queries.
- 👑 Senior: Design shard strategies, hot/warm clusters, query routing, index lifecycle policies, and proactively balance shards to avoid hot nodes.
📚 Resources:
❓ What’s the typical architecture of an ELK (Elasticsearch + Logstash + Kibana) stack?
ELK is a pipeline: Logstash ingests and transforms data, Elasticsearch stores and indexes it, and Kibana visualizes it.
You use it when you need centralized logs, search, dashboards, and alerting.
Sources > Logstash
- Apps, servers, containers, Beats agents, Kafka — all send logs to Logstash.
- Logstash parses, enriches, transforms (grok, JSON, geoip, etc.), and outputs to Elasticsearch.
Logstash > Elasticsearch
- Elasticsearch indexes structured data, making it searchable.
- Cluster has multiple nodes, shards, and replicas.
Kibana > Elasticsearch
Kibana reads from Elasticsearch and provides dashboards, visualizations, queries, alerts, and exploration tools.
What .NET engineers should know:
- 👼 Junior: Logs go into Logstash, are stored in Elasticsearch, and are visualized in Kibana.
- 🎓 Middle: Understand parsing pipelines, ingest nodes, shard/replica layout, and dashboard/query basics.
- 👑 Senior: Design full ingestion pipelines, tune shards, manage ILM, integrate Kafka, scale clusters, and optimize indexing/search latency for large log volumes.
Parquet / Databricks Interview Questions and Answers

❓ What is a Parquet file, and why is it efficient for analytical workloads?
Parquet is a columnar storage format. Instead of storing data row-by-row, it stores it column-by-column.
Analytics often read only a few columns, so Parquet lets engines skip everything else and scan much less data. It also compresses extremely well because each column contains similar values.
What .NET engineers should know:
- 👼 Junior: Parquet stores data by columns, so analytical queries read less and run faster.
- 🎓 Middle: It supports compression, encoding, and predicate pushdown to skip irrelevant data.
- 👑 Senior: Tune row group sizes, use Parquet for large analytical workloads, integrate with Spark/Presto/Athena, and avoid it for transactional use cases.
📚 Resources: Parquet overview
❓ How do columnar storage formats improve query performance?
The primary way columnar storage formats improve query performance is by enabling data engines to read less data from disk, which translates directly into lower I/O costs and faster processing, especially for analytical workloads (OLAP).
Columnar layout
- Analytical queries read specific fields (e.g., date, amount).
- Parquet reads only those columns, not entire rows.
Encoding and compression
- Parquet uses dictionary encoding, RLE, bit-packing, and page compression.
- Similar column values compress far better than row-based formats.
Predicate pushdown
- Engines like Spark, Trino, BigQuery, and Athena can skip entire row groups based on column statistics (min/max values).
- Huge speed boost.
Schematized + typed
- Parquet enforces a schema and stores types, making it efficient for analytics engines.
Optimized for big data
- Distributed systems can process Parquet in parallel by splitting files into row groups.
What .NET engineers should know:
- 👼 Junior: Columnar formats store data by columns, so queries read less and run faster.
- 🎓 Middle: They improve compression, push filters down, and support vectorized execution.
- 👑 Senior: Tune row group sizes, leverage pushdown, optimize analytical pipelines, and pick columnar formats (Parquet/ORC) for big read-heavy workloads.
❓ What’s the difference between Parquet, Avro, and ORC?
The main difference between Parquet, Avro, and ORC is their storage structure (row-based vs. columnar), which fundamentally dictates whether they are optimized for fast analytical reads (OLAP) or fast data serialization/writes (ETL).
Parquet
- Columnar
- Best for analytical queries (Spark, Trino, Athena)
- Significant compression + predicate pushdown
Very common in data lakes
Avro
- Row-based
- deal for Kafka, event streams, and RPC
- Fast serialization/deserialization
- Strong schema evolution support (backward/forward compatible)
ORC
- Columnar, optimized for Hadoop ecosystems
- Heavier but very efficient for large scans
- Significant compression + indexes + bloom filters
- Often faster than Parquet in Hive-like workloads
Here is a comparison table between Parquet, Arvo, and ORC:
| Feature | Parquet | Avro | ORC |
|---|---|---|---|
| Storage Model | Columnar (Data stored by column). | Row-Based (Data stored by record). | Columnar (Striped) (Similar to Parquet, data stored in stripes). |
| Primary Use Case | Analytical Queries (OLAP), Data Warehousing, Read Speed. | Data Serialization, ETL Pipelines, High Write Speed, Kafka Integration. | Analytical Queries (OLAP), Highly integrated with Hive/Spark. |
| Read Efficiency | Highest (via Column Pruning). | Lowest (must read entire row). | Very High. |
| Write Efficiency | Moderate (requires internal buffering). | Highest (simple sequential writes). | Moderate. |
| Schema Evolution | Good (easy to add columns). | Excellent (best support for robust schema changes). | Good. |
What .NET engineers should know:
- 👼 Junior: Parquet/ORC are columnar for analytics; Avro is row-based for streaming and schema evolution.
- 🎓 Middle: Use Parquet/ORC for big reads and aggregations; Avro for serialization, events, and contracts.
- 👑 Senior: Choose format based on workload (batch vs streaming), schema evolution needs, pushdown performance, and compatibility with engine ecosystems.
❓ How do you handle schema evolution in Parquet?
- Parquet supports schema evolution, but only in additive and compatible ways.
- You can add new columns or change optional fields, and the engines will read both old and new files together.
- You can’t safely remove or rename columns without breaking readers unless your query engine has special rules.
What .NET engineers should know:
- 👼 Junior: Parquet allows adding new columns; missing fields become null.
- 🎓 Middle: Ensure type compatibility, avoid renames, and understand how readers merge schemas.
- 👑 Senior: Use table formats (Iceberg/Delta) for complex evolution, apply expand–contract patterns, and plan data migrations to avoid schema fragmentation.
❓ What is Delta Lake, and how does it enhance Parquet?
Delta Lake is a storage layer built on top of Parquet that adds ACID transactions, versioning, schema enforcement, and time travel.
Parquet by itself is just files on disk. Delta Lake turns those files into a reliable table format you can safely update, merge, and query at scale.
What it adds on top of raw Parquet:
- ACID transactions
Multiple writers can update the table safely.
No partial files, no corrupted states, no race conditions. - Time travel/versioning
You can query the table as of any version or timestamp.
Great for debugging, ML reproducibility, and rollbacks. - Schema enforcement + evolution
Delta prevents incompatible schema changes and safely tracks schema evolution (e.g., adding columns, updating types). - Upserts and deletes
MERGE, UPDATE, DELETE — things Parquet cannot do natively.
Delta rewrites affected Parquet files and maintains metadata in the transaction log. - Data skipping and indexing
Delta stores column stats to skip entire files during reads, improving query performance. - Reliable streaming
Batch + streaming over the same table becomes consistent — useful for Spark, Databricks, and large pipelines.
What .NET engineers should know:
- 👼 Junior: Delta Lake adds transactions, schema control, and time travel to Parquet.
- 🎓 Middle: Use Delta for safe updates (MERGE/UPDATE/DELETE) and reliable pipelines.
- 👑 Senior: Plan table layout, partitioning, vacuum/retention policies, optimize metadata, and design pipelines that mix batch + streaming without corruption.
📚 Resources: Delta Lake documentation
❓ How would you optimize data partitioning in Parquet for large-scale queries?
Good Parquet partitioning means fewer files scanned, fewer I/O operations, and much faster queries.
Bad partitioning means tiny files, too many folders, and engines scanning everything anyway.
You choose partition keys based on how data is filtered and how often partitions change.
Best practices:
- Partition by high-selectivity fields
Pick columns your queries commonly filter on: date, country, and category.
If 90% of queries areWHERE date = …, partitioned by date. - Don’t over-partition
Avoid day/hour/minute-level partitions unless traffic is enormous.
Too many small folders/files create a metadata explosion. - Prefer stable, low-cardinality keys
Good: year, month, country
Bad: userId, transactionId, productId (millions of folders) - Use partition pruning
Engines like Spark/Trino/Athena skip entire folders if partition filters match.
That’s where the real performance gains come from. - Keep row groups large enough
Parquet is fastest with row groups ~64–512 MB, depending on workload.
Small row groups kill scan and compression efficiency. - Coalesce small files
Tiny files create overhead. Use compaction to merge them regularly. - Avoid partition keys that change often.
If each write changes the partition path, you’ll create thousands of tiny partitions. - Hybrid approach
Partition by date, cluster/sort within partitions by another column for even better skipping.
What .NET engineers should know:
- 👼 Junior: Partition by columns used for filtering (e.g., date) to skip unnecessary files.
- 🎓 Middle: Avoid too many small partitions, manage row group sizes, and compact small files.
- 👑 Senior: Design partition strategies based on query patterns, storage costs, engine behavior (Spark/Trino/Athena), and long-term data growth.
📚 Resources:
Graph Databases Interview Questions and Answers
❓ What is a graph database, and how is it different from other NoSQL databases?
A graph database stores data as nodes and relationships instead of rows, documents, or key-value pairs. Nodes represent entities (users, products, accounts), and edges represent how those entities connect. This makes graph databases efficient for data where relationships are first-class citizens rather than secondary lookup data.

For example, in a social network model:
(User: Artem) --[FRIEND_OF]--> (User: John)
(User: Artem) --[WORKS_AT]--> (Company: OpenAI)The main difference from other NoSQL databases is how relationships are modeled and queried:
- Document DBs (e.g., MongoDB) store nested/aggregate data well, but relationship traversal often requires manual joins or multiple queries
- Key-value stores (e.g., Redis) optimize for direct lookup by key
- Wide-column stores optimize for large-scale partitioned data
- Graph DBs optimize for traversing connected data across many hops
A graph query can naturally express relationship traversal:
MATCH (u:User)-[:FRIEND_OF]->(friend)
WHERE u.Name = 'Artem'
RETURN friendGraph databases are commonly used for recommendation engines, fraud detection, knowledge graphs, network topology, access-control systems, and dependency analysis, anywhere the connections between entities matter as much as the entities themselves.
What .NET engineers should know:
- 👼 Junior: Graph databases store entities as nodes and relationships as edges instead of tables or documents.
- 🎓 Middle: They are best suited for highly connected data where traversing relationships is a core access pattern.
- 👑 Senior: Graph databases are powerful but specialized—using one for ordinary CRUD workloads often adds complexity without benefit; adopt them when relationship traversal is a primary domain concern.
❓ When should you use a graph database over SQL or document databases?
A graph database makes sense when relationships are central to the domain, and the application frequently traverses many connected entities. If the main business questions sound like “find friends of friends,” “detect suspicious account chains,” “recommend similar products based on user behavior,” or “analyze dependencies across systems,” graph storage is often a better fit than SQL or document databases.
SQL databases can model relationships with joins, and document databases can embed related data, but both become awkward when queries require deep or dynamic traversal across many hops. Graph databases store relationships explicitly, so traversing connected data remains efficient even as the relationship depth increases
SQL Example Problem:
Find users connected within 4 degrees through friendships,
shared groups, and common purchases.
→ Multiple joins / recursive CTEs / complex query logicHow it can be solved by Cypher:
MATCH (u:User)-[:FRIEND_OF|MEMBER_OF|PURCHASED*1..4]-(related)
WHERE u.Id = $userId
RETURN relatedGraph databases are not general-purpose replacements for SQL or document stores. If the data is mostly aggregate-based, document-centric, or simple CRUD with occasional joins, a graph database usually adds complexity without meaningful benefit.
What .NET engineers should know:
- 👼 Junior: Use graph databases when relationships between records matter as much as the records themselves.
- 🎓 Middle: They shine when the app performs multi-hop traversal, recommendation, dependency, or network-style queries frequently.
- 👑 Senior: Choosing graph DBs is about access patterns, not hype—if relationship traversal is not a primary workload, SQL or document stores are usually simpler and cheaper to operate.
❓ What is Cypher, and how does it work in Neo4j?
Cipher is Neo4j’s declarative query language for working with graph data. It plays a role similar to SQL in relational databases, but instead of querying tables and joins, it queries nodes, relationships, and patterns in the graph.
The core idea is pattern matching: developers describe the graph shape they want, and Neo4j finds matching nodes/edges. For example, this query finds all friends of a user:
MATCH (u:User)-[:FRIEND_OF]->(friend)
WHERE u.Name = 'Artem'
RETURN friendCypher syntax is intentionally visual:
()represents a node[]represents a relationship-->/<--represent direction
It can also create and update graph data:
CREATE (u:User {Name: 'Artem'})
CREATE (c:Company {Name: 'OpenAI'})
CREATE (u)-[:WORKS_AT]->(c)Because Cypher is declarative, the query describes what relationship pattern to match, not how to traverse the graph manually. Neo4j handles traversal planning and optimization internally.
What .NET engineers should know:
- 👼 Junior: Cypher is Neo4j’s query language for reading and writing graph data.
- 🎓 Middle: It uses pattern-matching syntax to express graph traversal more naturally than SQL joins or recursive queries.
- 👑 Senior: Strong Cypher design requires understanding graph modeling poor node/edge design leads to awkward queries even if the language itself is expressive.
📚 Resources:
❓ What is Gremlin, and how is it different from Cypher?
Gremlin and Cipher are both graph database query languages, but come from different ecosystems with different design philosophies. Gremlin is a graph traversal language from the Apache TinkerPop framework it's imperative, describing the exact steps to traverse a graph. Cypher is Neo4j's declarative query language — it describes the pattern you want to match and lets the engine figure out how to find it. The difference is similar to SQL vs. a stored procedure: Cypher tells the database what you want, Gremlin tells it how to walk the graph to get it.
Gremlin works across any TinkerPop-compatible graph database — Amazon Neptune, Azure Cosmos DB (Gremlin API), JanusGraph, and others. Cypher is primarily Neo4j's language, though openCypher has brought it to other databases. If portability across graph backends matters, Gremlin is the more universal choice.
Example of the same query in both languages find friends of friends:
Gremlin — imperative traversal
g.V().has('Person', 'name', 'Alice')
.out('FRIENDS_WITH')
.out('FRIENDS_WITH')
.values('name')Cypher — declarative pattern matching
MATCH (alice:Person {name: 'Alice'})-[:FRIENDS_WITH*2]->(fof:Person)
RETURN fof.nameExample of creating vertices and edges in Gremlin:
// Gremlin — add vertices and edge
g.addV('Person').property('name', 'Alice').property('age', 30).as('a')
.addV('Person').property('name', 'Bob').property('age', 25).as('b')
.addE('FRIENDS_WITH').from('a').to('b')
.iterate()// Cypher equivalent
CREATE (a:Person {name: 'Alice', age: 30})
CREATE (b:Person {name: 'Bob', age: 25})
CREATE (a)-[:FRIENDS_WITH]->(b)The readability gap is the most practical difference — Cypher's ASCII-art pattern syntax (-[:FRIENDS_WITH]->) reads naturally to anyone familiar with graph concepts. Gremlin's chained step syntax is more powerful for complex traversals but has a steeper learning curve and is harder to read at a glance.
What engineers should know:
- 👼 Junior: Gremlin is imperative — you describe the traversal steps. Cypher is declarative — you describe the pattern to match. Gremlin works across multiple graph databases via TinkerPop; Cypher is primarily Neo4j.
- 🎓 Middle: Understand when Gremlin's step-by-step traversal gives you more control — complex conditional paths, dynamic traversal logic, and multi-hop filtering are often cleaner in Gremlin than equivalent Cypher. Know that
.iterate()is required for Gremlin mutations to actually execute — omitting it is a common silent bug. - 👑 Senior: Choose between them based on database portability requirements and team familiarity — Gremlin's TinkerPop compatibility is a genuine advantage in multi-cloud or vendor-agnostic architectures, but Cypher's readability reduces onboarding time and review friction for teams without graph database backgrounds. openCypher adoption is expanding Cypher's reach beyond Neo4j, narrowing the portability argument.
❓ How do you model 1:1, 1:N, and N:N relationships in Graph DB?
In graph databases, all relationships are modeled the same fundamental way: nodes connected by edges. Unlike SQL, there is no separate concept of foreign keys, join tables, or special syntax for one-to-one vs many-to-many. Cardinality is defined by the number of relationships between nodes, not by the schema structure.
A 1:1 relationship means one node is expected to connect to exactly one other node of that type:
(User)-[:HAS_PROFILE]->(Profile)A 1:N relationship means one node can connect to many others:
(Customer)-[:PLACED]->(Order)An N:N relationship means both sides can connect to many nodes:
(Student)-[:ENROLLED_IN]->(Course)Creating these relationships looks the same regardless of cardinality:
CREATE (u:User {Name: 'Artem'})
CREATE (p:Profile {Bio: 'Architect'})
CREATE (u)-[:HAS_PROFILE]->(p)
CREATE (c:Customer {Name: 'Alice'})
CREATE (o:Order {Id: 123})
CREATE (c)-[:PLACED]->(o)The key difference from relational databases is that graph databases typically do not enforce cardinality automatically unless additional constraints or application logic are added. The model expresses relationships naturally, but business rules still need to be enforced where required.
What .NET engineers should know:
- 👼 Junior: In graph DBs, all relationships are edges between nodes—1:1, 1:N, and N:N use the same modeling approach.
- 🎓 Middle: Cardinality is determined by how many edges exist, not by schema constructs like join tables or foreign keys.
- 👑 Senior: Graph modeling focuses less on normalization and more on traversal efficiency; relationship design should reflect query patterns, not relational habits.
❓ How do you handle query performance in graph databases?
Graph database performance depends heavily on starting traversal efficiently and limiting traversal scope. Graph engines are optimized for walking relationships, but they still perform poorly when queries start from large, unfiltered node sets or traverse too many hops without constraints.
The first optimization is to index frequently searched properties so the engine can locate the starting node quickly rather than scanning the graph.
CREATE INDEX user_name_index
FOR (u:User)
ON (u.Name)Then queries should start from indexed nodes and traverse outward:
MATCH (u:User {Name: 'Artem'})-[:FRIEND_OF*1..2]->(friend)
RETURN friendBounding traversal depth is critical. Unbounded traversals can explode combinatorially on dense graphs:
-- Dangerous on large graphs
MATCH (u:User)-[:CONNECTED_TO*]->(x)
RETURN xOther common performance techniques include:
- Designing relationship directions and labels intentionally
- Avoiding supernodes (nodes connected to millions of others) when possible
- Profiling queries with execution plans (
PROFILE,EXPLAIN) - Denormalizing selective data if traversal patterns become too expensive
Graph DB performance is less about “join optimization” and more about graph shape + traversal design.
What .NET engineers should know:
- 👼 Junior: Index properties used to find starting nodes before traversing the graph.
- 🎓 Middle: Keep traversals bounded and avoid queries that explore unlimited relationship depth.
- 👑 Senior: Graph performance is largely a data-modeling concern—poor graph shape, supernodes, and bad traversal patterns can defeat even well-indexed systems.
📚 Resources:
- https://neo4j.com/docs/cypher-manual/current/indexes/
- https://neo4j.com/docs/cypher-manual/current/query-tuning/
❓ What’s the difference between property graphs and RDF?
Property Graphs (PG) and the Resource Description Framework (RDF) are the two primary models used to represent and store connected graph data. While they both express network structures, they originate from different paradigms and serve distinct needs.
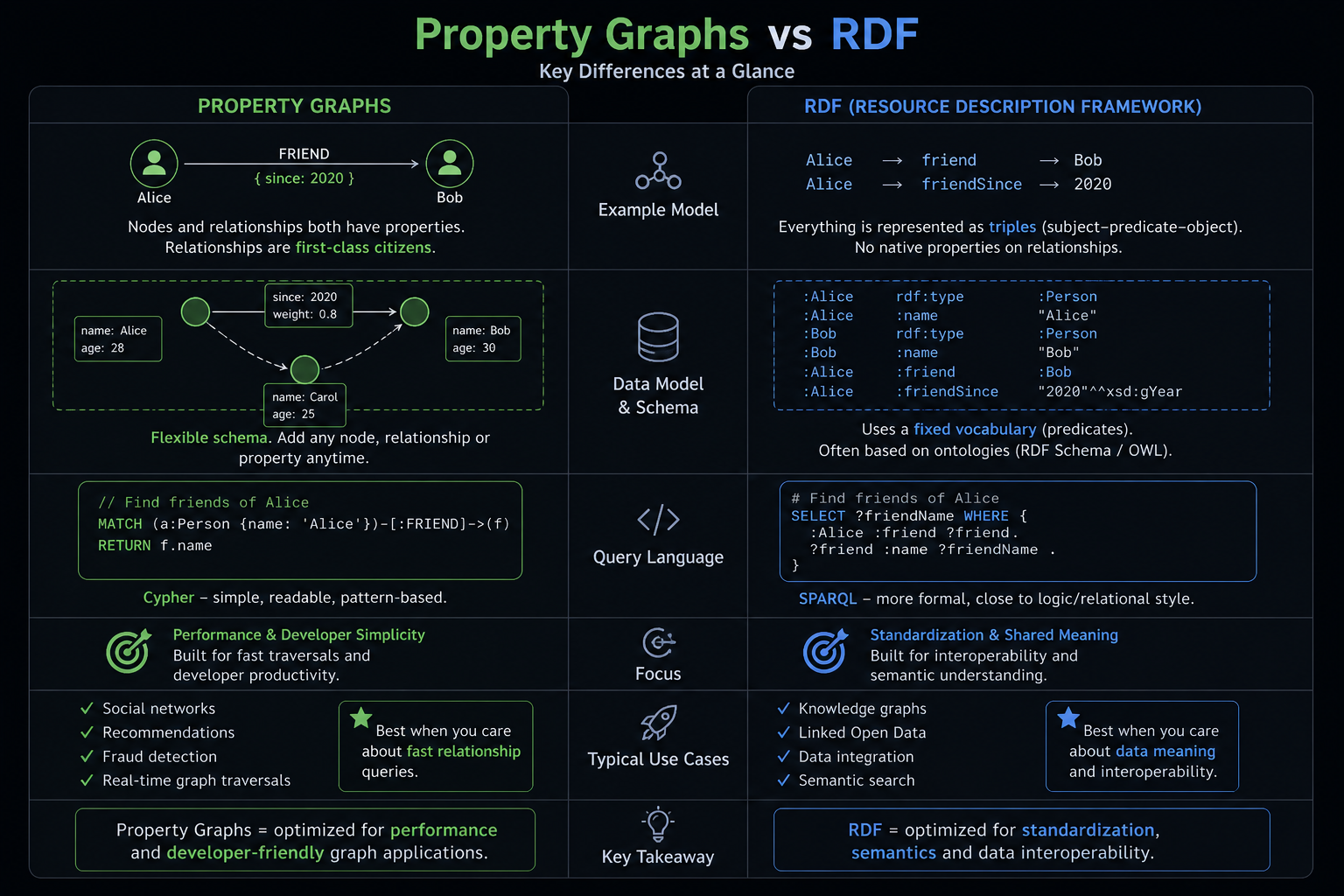
- Property Graph: Designed for operational performance and analytical speed. Data is modeled exactly how you would draw it on a whiteboard—nodes and edges contain their own descriptive key-value properties natively.
- RDF: A W3C standard designed for data exchange, federation, and global interoperability. Information is modeled as a collection of atomic subject–predicate–object statements called "triples."
What .NET Engineers Should Know
- 👼 Junior: To query Property Graphs, use
Neo4j.DriverorGremlin.Netwith matching pattern-based queries (Cypher), while for RDF stores use thedotNetRDFNuGet package to write SPARQL queries. - 🎓 Middle: Implement
dotNetRDF 3.xto map RDF-star directly into your C# models, and usedotNetRDF.Dynamicto interact with RDF graphs via .NET's dynamic type binding without writing manual boilerplate. - 👑 Senior: Architect enterprise data platforms that combine both models: use an RDF triple store to maintain strict, regulated domain ontologies and a Property Graph to execute massive multi-hop traversal and AI context retrieval.
❓ What are common anti-patterns of Graph databases?
The most common graph database anti-pattern is using a graph database when the problem is not graph-shaped. If the workload is mostly CRUD, aggregate reads, simple filtering, or document retrieval, a graph database often adds operational and modeling complexity without delivering meaningful benefit.
Bad Graph Modeling:
(User)-[:HAS_FIRST_NAME]->(FirstName)
(User)-[:HAS_LAST_NAME]->(LastName)
Better:
(User { FirstName: "Artem", LastName: "Polishchuk" })Another frequent mistake is modeling the graph like a relational database. Teams new to graph DBs often recreate join-table thinking, over-normalize everything into tiny nodes, or create unnecessary intermediate entities. Graph models should optimize for traversal patterns, not mimic SQL schemas.
A major performance anti-pattern is creating supernodes with extremely high relationship counts, which can make traversals expensive and skew query performance.
Example Supernode:
(Tag: "Popular")
connected to 50 million PostsOther common issues include:
- Unbounded traversals (
*..) that explore massive graph portions - Missing indexes on lookup properties
- Overusing graph DBs for analytics/aggregation workloads is better suited to columnar/OLAP systems
- Ignoring graph-specific query profiling tools and assuming “graph is always fast.”
Graph databases are powerful, but they punish poor modeling decisions more visibly than many relational systems.
What .NET engineers should know:
- 👼 Junior: Do not use a graph database unless relationships and traversal are core to the problem.
- 🎓 Middle: Avoid modeling graphs like normalized SQL schemas; store simple scalar properties directly on nodes when appropriate.
- 👑 Senior: Most graph DB failures come from wrong use-case selection or poor graph design, not from the database engine itself.
❓ How do you manage the scaling of Graph databases?
What .NET Engineers Should Know
- 👼 Junior: When connecting to a graph cluster in .NET, always use the cluster-aware routing URI scheme (e.g.,
neo4j+s://instead ofbolt://) in your driver configuration to automatically route read and write traffic correctly. - 🎓 Middle: Use the explicit Read/Write transaction functions provided by the driver (e.g.,
ExecuteReadAsyncorExecuteWriteAsyncin Neo4j) to let the driver intelligently balance queries across cluster replicas. - 👑 Senior: Architect a multi-tier caching strategy in ASP.NET Core that offloads frequent traversal queries to a high-speed distributed cache like Redis to avoid over-utilizing the graph cluster.
❓ How do you secure data in a graph database?
- Use node/edge metadata (roles, ACLs)
- Filter access in application logic
- RBAC in Neo4j Enterprise
What .NET engineers should know:
- 👼 Junior: Security is handled by your service.
- 🎓 Middle: Add ACL metadata and filter at query time.
- 👑 Senior: Combine RBAC, scoped traversal, and metadata redaction.
❓ What is a knowledge graph?
A graph that uses ontologies, schemas, and reasoning (often RDF-based). Popular in search, NLP, and identity resolution.
What .NET engineers should know:
- 👼 Junior: Knowledge graphs add meaning to relationships.
- 🎓 Middle: Use RDF triples and SPARQL.
- 👑 Senior: Integrate ontologies and semantic reasoning.
❓ How do you benchmark graph query performance?
- Use synthetic datasets (LDBC, Graph500)
- Profile depth, fan-out, and latency
- Simulate real traffic
What .NET engineers should know:
- 👼 Junior: Know queries can be expensive.
- 🎓 Middle: Measure cardinality, index use.
- 👑 Senior: Model worst-case scenarios and monitor traversal costs.
❓ What are the limitations of graph databases?
- Not ideal for tabular analytics
- Schema-less can lead to messy data
- Limited ACID support in some engines
What .NET engineers should know:
- 👼 Junior: Graphs aren’t general-purpose.
- 🎓 Middle: Know their boundaries.
- 👑 Senior: Pair graphs with OLAP or SQL systems where needed.
Vector Databases Interview Questions and Answers
❓ What is a vector database, and how does it differ from traditional databases?
A vector database stores embeddings (float arrays) and performs similarity search on them. Instead of looking for exact matches, it finds “closest” vectors — meaning the most semantically similar items.
Traditional databases index structured fields; vector DBs index high-dimensional numeric spaces.
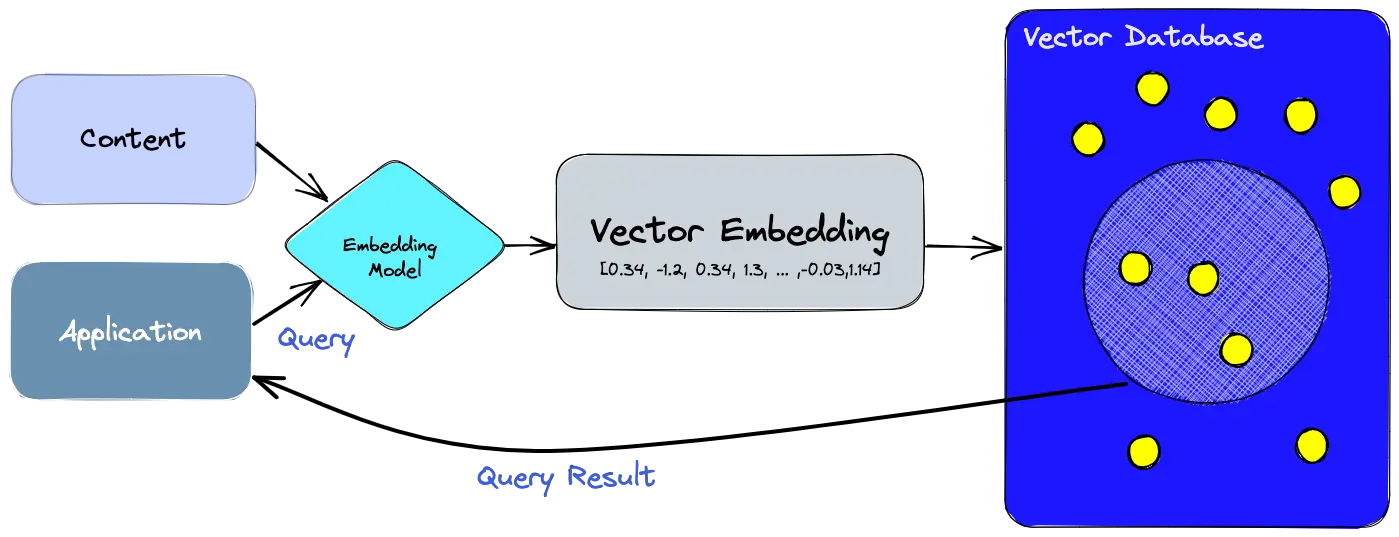
Core differences:
| Feature | Vector Database | Traditional Databases (RDBMS/NoSQL) |
|---|---|---|
| Data Stored | Vector Embeddings (Arrays of floating-point numbers), usually alongside associated metadata. | Structured text, numbers, dates (RDBMS); JSON documents (NoSQL). |
| Primary Indexing | Approximate Nearest Neighbor (ANN) algorithms (e.g., HNSW, IVFFlat). | B-Tree (RDBMS); Hash Table/B+Tree (NoSQL keys). |
| Primary Query | Similarity Search (Nearest Neighbor) based on distance (Cosine, Euclidean/L2). | Exact match (WHERE ID = X), Range queries, Complex joins. |
| Optimization Goal | Recall (Finding the most relevant, similar items quickly). | Consistency (ACID) and Exactness. |
| Use Case | Generative AI (RAG), Semantic Search, Recommendations, Image/Video Recognition. | Transaction processing (OLTP), Inventory management, Financial records. |
What .NET engineers should know:
- 👼 Junior: Vector DBs store embeddings and find similar items; traditional DBs match exact values.
- 🎓 Middle: Use vector indexes (HNSW/IVF) and similarity metrics (cosine/L2) for semantic search.
- 👑 Senior: Combine vector + metadata filters, tune ANN indexes, manage batch-upserts, and design RAG/recommendation pipelines around vector search.
📚 Resources:
- What is a Vector Database & How Does it Work? Use Cases + Examples
- Vector Databases Explained: Key Features, AI Integration, and Use Cases
❓ How do vector databases store and search vectors?
Vector databases store and search vectors using specialized indexing structures, primarily Approximate Nearest Neighbor (ANN) algorithms, which optimize for speed rather than perfect accuracy in high-dimensional space.
How storage works:
- Store vectors + metadata
Each record = embedding + ID + optional metadata/filters. - Normalize or quantize
Vectors are often normalized (for cosine similarity) or compressed (PQ) to reduce memory usage and speed up search. - Build an ANN index
The index organizes vectors so that nearest-neighbor queries avoid scanning the entire dataset.
How search works:
- Convert input (text/image/audio) → embedding
- Query embedding goes into the ANN index
- Index navigates to likely neighbors
- Return top-K similar vectors by cosine/L2/dot product
Common ANN index types:
- HNSW (graph-based)
A multi-layer graph where search walks from coarse nodes to fine ones.
Very fast, very accurate, widely used (Pinecone, Milvus, Redis).
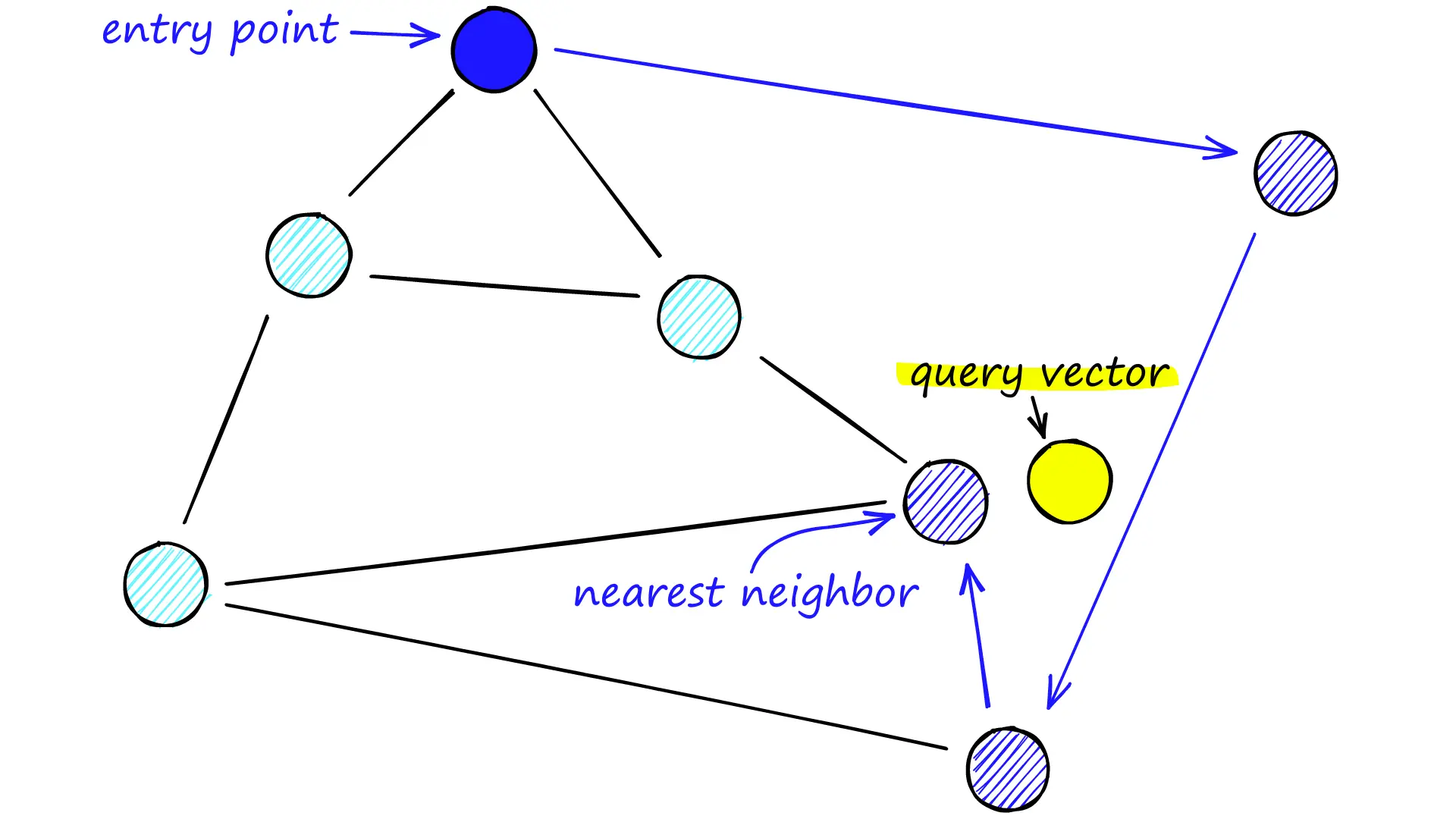
- IVF (cluster-based)
Vectors are grouped into clusters.
Search only scans the nearest clusters, not the whole dataset.
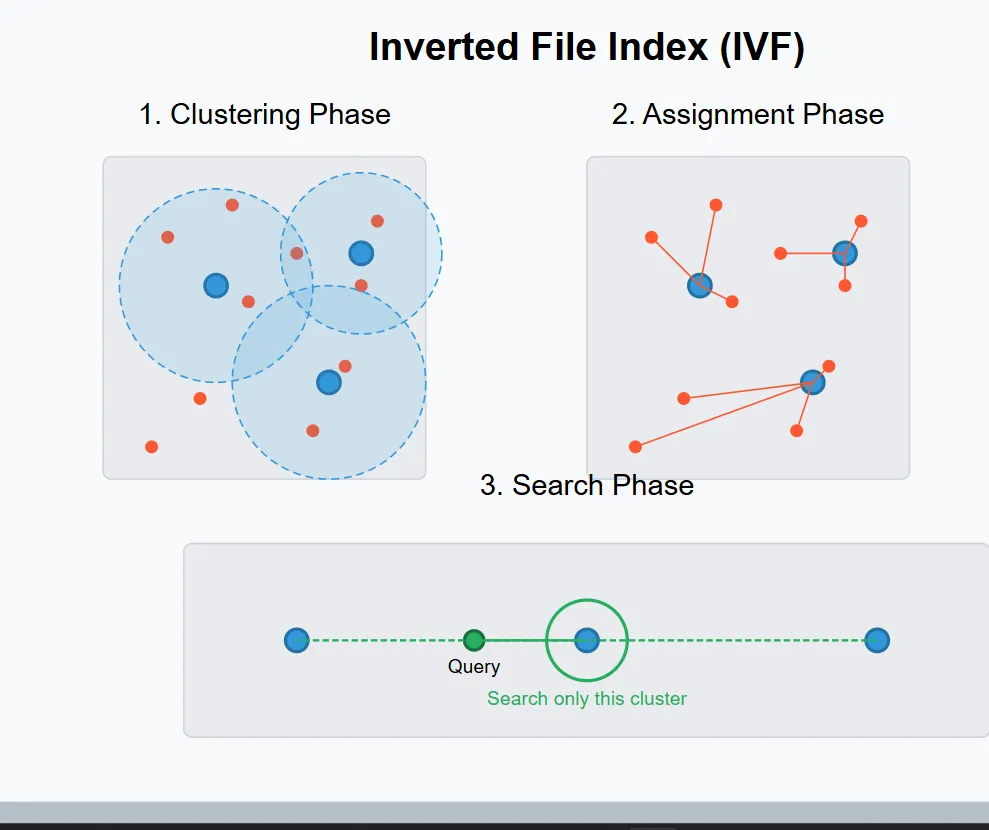
- PQ / OPQ (quantization)
Compress vectors into small codes.
Trades some accuracy for huge memory and speed gains.
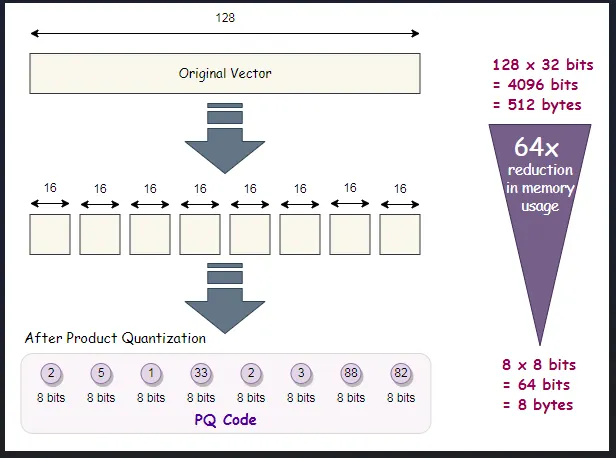
- FLAT search (brute force)
Exact but slow.
Used when datasets are small or accuracy must be perfect.
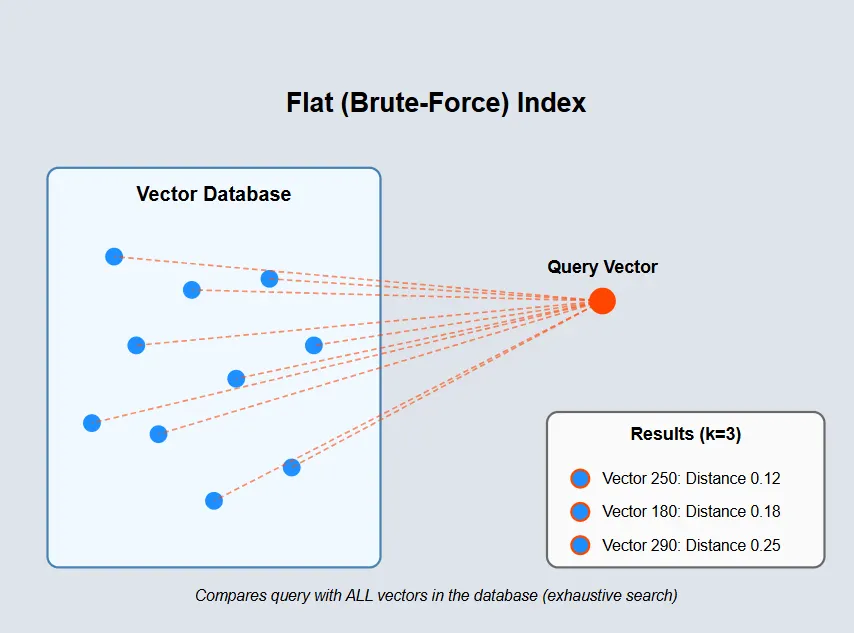
Why it’s useful: ANN lets you search millions of embeddings in milliseconds for semantic search, RAG, recommendations, and vision/audio similarity.
What .NET engineers should know:
- 👼 Junior: Vector DBs store embeddings and find similar vectors using ANN indexes.
- 🎓 Middle: Know HNSW/IVF/PQ and that ANN avoids scanning all vectors by searching smart neighborhoods.
- 👑 Senior: Tune index parameters (ef, nprobe), balance accuracy vs speed, mix ANN with metadata filtering, and design scalable vector ingestion pipelines.
📚 Resources: Different Types of Indexing- Vector Database
❓ When would you choose a Vector DB instead of Elasticsearch or SQL full-text?
Choose a Vector DB when you need semantic search or similarity — not exact keyword matching.
Elasticsearch and SQL full-text are great for literal text queries, but they can’t understand meaning or compare embeddings across text, images, or audio.
Use a Vector DB when:
- Semantic search
User searches “quiet laptop for travel”.
Keyword search fails — vector search understands intent. - Similarity search
Find items “closest” to an embedding: products, hotels, resumes, code snippets. - Multimodal search
Embeddings unify text, images, and audio into a single vector space.
E.g., “find images similar to this photo”. - Recommendation systems
“Users who liked X also liked Y” via vector proximity. - RAG (Retrieval-Augmented Generation)
You retrieve semantically relevant chunks, not keyword matches.
Cases where not to use a Vector DB:
- Exact matches
IDs, emails, SKUs > Elasticsearch or SQL keyword fields. - Structured filtering
WHERE price < 100 AND category = 'phone'
Elasticsearch / SQLwins here. - Complex aggregations
Counts, group-bys, dashboards > SQL or Elasticsearch aggregations. - Transactional workloads
Vector DBs aren’t built for ACID-heavy CRUD.
What .NET engineers should know:
- 👼 Junior: Use a Vector DB when you need semantic similarity, not keyword matching.
- 🎓 Middle: Great for search across text/images/audio, recommendations, and RAG workflows.
- 👑 Senior: Combine vector search + metadata filters, hybrid search (ANN + BM25), fallback strategies, and choose the right engine based on traffic, accuracy, and multimodal needs.
❓ What are the trade-offs between storing vectors inside your SQL/NoSQL database vs using a dedicated vector DB?
You can store embeddings in PostgreSQL with pgvector, SQL Server, MongoDB Atlas Vector Search, Elasticsearch, or Redis. It works fine until the scale or latency requirements grow. The trade-off is simple: one database gives you easy ops, a vector database gives you real performance.
Built-in DB vector search
- Simple architecture
- Easy to combine with metadata
- Enough for small–medium workloads
Slower ANN- Harder to scale horizontally
- Limited tuning
Dedicated vector DB
- Best latency and recall
- Distributed out of the box
- Rich ANN index choices
- Handles massive vector sets
- Extra infrastructure
- More ops work
What .NET engineers should know
- 👼 Junior: built-in search is simple, vector DBs are faster and scale better.
- 🎓 Middle: Databases handle filters well, but ANN slows them down; vector DBs exist to fix that.
- 👑 Senior: pick based on workload. If you need hybrid queries and simplicity, choose PostgreSQL, MongoDB, or Elasticsearch. If semantic search runs the product, use a dedicated vector DB and tune ANN properly.
❓ How do embeddings represent meaning in text, images, or audio?
Embeddings turn raw data into numbers that capture meaning, not just structure.

A model learns patterns of words that appear together, visual shapes, and audio frequencies, and maps them into a vector space where similar things are close together.
That’s why embeddings let us measure semantic similarity with math.
How it works:
- Text
Words, sentences, or documents become vectors based on context.
“king” − “man” + “woman” ≈ “queen”.
Similar words land near each other in vector space. - Images
A CNN/vision model extracts patterns like edges, textures, and objects.
Similar images → similar vectors. - Audio
Models capture pitch, tone, phonemes, and patterns over time.
Two clips of the exact phrase produce close embeddings. - Why it matters
You can search by meaning instead of keywords.
Example: search “tall mountain” → find “Himalayas”, even if the text never says “tall”. - Math intuition
Distance in vector space ≈ similarity.
Cosine similarity shows how close the vectors point.
What .NET engineers should know:
- 👼 Junior: Embeddings turn text/images/audio into vectors where similar items sit close together.
- 🎓 Middle: Use embeddings for semantic search, recommendations, and similarity scoring with cosine/L2 metrics.
- 👑 Senior: Choose embedding models carefully, normalize vectors, tune similarity metrics, combine vector + metadata filters, and build scalable vector pipelines.
❓ What is cosine similarity, and why is it used for semantic search?
Cosine Similarity measures the cosine of the angle between two non-zero vectors in an inner product space. It quantifies how similar the vectors are in direction, regardless of their magnitudes.
Similarity search involves finding items that are most similar to a given query based on their vector representations.
Real-World Example
Resume Matching: Comparing job descriptions and resumes to find the best candidate matches based on skill similarity.
Think of two arrows pointing in a similar direction. The smaller the angle between them, the more alike they are in meaning.
What .NET engineers should know:
- 👼 Junior: Cosine similarity checks how similar two vectors are by comparing their direction.
- 🎓 Middle: It’s used in semantic search because embeddings align in similar directions for related content.
- 👑 Senior: Normalize vectors, choose the right metric per model, optimize ANN indexes for cosine, and combine semantic scores with metadata filters.
📚 Resources: Understanding Semantic Meaning and Similarity Search: Cosine Similarity and Euclidean Distance
❓ What is the difference between ANN search and exact search, and when do you need exact search?
Exact search compares your query vector against every vector — perfect accuracy, terrible speed at scale.
ANN (Approximate Nearest Neighbor) skips most of the space using smart indexes like HNSW or IVF — much faster, but not 100% accurate.
You trade a tiny bit of precision for massive speed.
Exact search
- Brute-force comparison (O n)
- Always returns the actual nearest neighbors
- Slow for large datasets (millions or billions)
- Suitable for small collections or high-stakes results
ANN search
- Uses indexes (HNSW / IVF / PQ)
- Returns “close enough” neighbors with very high recall
- Milliseconds, even at a vast scale
- Ideal for semantic search, recommendations, RAG
What .NET engineers should know:
- 👼 Junior: ANN is fast but approximate; exact is slow but accurate.
- 🎓 Middle: Use exact search for small sets, critical accuracy, or re-ranking ANN outputs.
- 👑 Senior: Combine ANN + exact re-ranking, tune recall, and choose the right approach based on dataset size and risk profile.
❓ How do you scale vector databases (sharding, replication, partitioning)?
Vector databases scale using a combination of sharding and replication to handle both massive datasets and high query throughput. The core challenge is distributing the complex, graph-based Approximate Nearest Neighbor (ANN) index itself.
Sharding
Distribute vectors across multiple nodes (hash, range, or semantic).
Each shard runs the ANN locally > and the results are merged into the final top-K.
Replication
Each shard has replicas for failover and higher read throughput.
Index partitioning
Large ANN indexes (HNSW, IVF, PQ) are split so no node holds everything.
Distributed search
Query > broadcast to shards > partial results >merge.
What .NET engineers should know:
- 👼 Junior: Scale by sharding vectors across nodes and running ANN on each.
- 🎓 Middle: Replication and index partitioning improve reliability and performance.
- 👑 Senior: Tune shard strategy, ANN params, and merge logic for consistent top-K at scale.
❓ How do you secure a vector DB API (metadata leaks, embedding inference risks)?
Vector DBs look harmless, but embeddings can leak meaning and metadata if you expose them directly.
You secure them like any sensitive ML system: lock down access, strip metadata, and never return raw embeddings unless absolutely required.
- Never expose embeddings directly.
Embeddings can be inverted or probed to guess the original text/image.
Return ranked results, not vectors. - Auth + RBAC on every endpoint
Treat vector search like a database query: API keys, JWT, scopes, rate limits. - Metadata filtering rules
Apply row-level permissions so users can’t access documents they shouldn’t reach, even via semantic search. - Query auditing + rate limiting
Prevents brute-force probing or embedding inversion attacks. - Embedding normalization & clipping
Protects against poisoned vectors or adversarial inputs. - Segregate private vs public indexes
Don’t mix confidential embeddings with open-search spaces. - Encrypt at rest & in transit
Especially important for models stored alongside vectors.
📖 Future reading
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum