SQL Interview Questions and Answers for .NET Developers (2026)

Welcome to the our .NET Interview Questions and Answers series exploring the ins and outs of C# and .NET! This chapter explores SQL Database questions that .NET engineers should be able to answer in an interview.
The Answers are split into sections: What 👼 Junior, 🎓 Middle, and 👑 Senior .NET engineers should know about a particular topic.
Also, please take a look at other articles in the series: C# / .NET Interview Questions and Answers
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum
🧠 Core Concepts
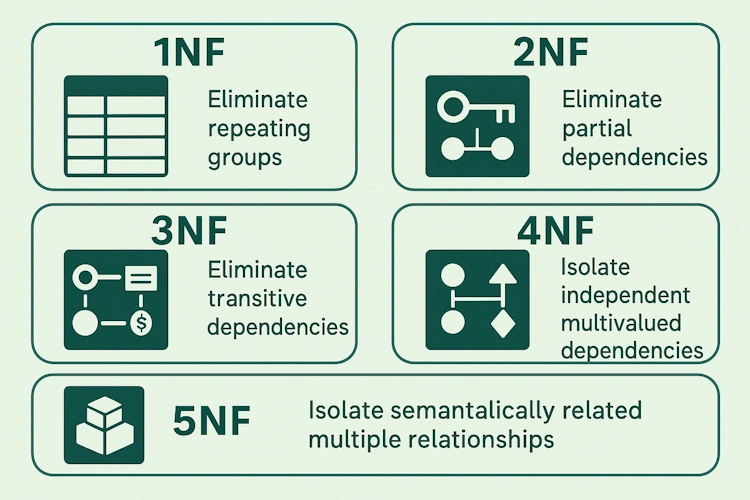
❓ What is normalization, and when would you denormalize your schema?
Database normalization organizes data into related tables to reduce duplication and maintain consistency.
Each fact is stored once, and relationships define how data connects.
Normalization occurs in stages: Normal Forms (1NF to 5NF), each with stricter design rules that eliminate redundancy.
When to denormalize?
Normalization improves consistency, but it can slow down reads because it requires joins.
Sometimes you denormalize for performance, for example:
- Reporting dashboards that repeatedly join multiple large tables.
- E-commerce product listings where you store the category name inside the Products table to avoid joins.
- Analytics systems where query speed matters more than storage efficiency.
In modern systems, normalization is primarily a logical design principle, while denormalization is often implemented physically via materialized views, caching, or summary tables rather than manual duplication.
What .NET engineers should know about normalization:
- 👼 Junior: Know normalization avoids duplicate data and organizes tables by rules (1NF, 2NF, 3NF…).
- 🎓 Middle: Understand trade-offs: normalized data is consistent, but denormalized data is faster to query, with the risk of duplication.
- 👑 Senior: Decide where to denormalize (e.g., caching, read models, reporting) and design hybrid models that balance performance and maintainability.
📚 Resources: 5 Database Normalization Forms
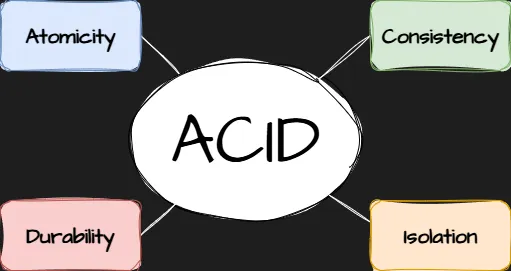
❓ How would you explain the ACID properties to a junior developer, and why are they important?
ACID defines the guarantees that a transactional database provides to ensure data correctness and reliability.
It stands for:
- Atomicity — a transaction is all-or-nothing. Example: when transferring money, either both debit and credit succeed or neither does.
- Consistency — every transaction maintains the database's validity in accordance with rules and constraints (no orphan records, no negative balances).
- Isolation — transactions running at the same time behave as if they were executed sequentially.
- Durability — once a transaction is committed, its changes survive crashes or power loss.
Without ACID, data could be lost or duplicated, e.g., charging a user twice or creating inconsistent order records.
What .NET engineers should know:
- 👼 Junior: Know that ACID keeps database operations safe and consistent.
- 🎓 Middle: Understand how transactions enforce atomicity and isolation, and when to use them in business operations.
- 👑 Senior: Tune isolation levels, handle concurrency issues, and design systems that balance strict ACID with performance (e.g., when to use eventual consistency).
📚 Resources: ACID in Simple Terms
❓ What does SARGability mean in SQL?
SARGability (Search ARGument Able) describes whether a query condition can efficiently use an index.
A SARGable query allows the database engine to perform an Index Seek rather than scanning the entire table.
✅ SARGable example
SELECT * FROM Orders WHERE OrderDate >= '2024-01-01';❌ Non-SARGable example:
SELECT * FROM Orders WHERE YEAR(OrderDate) = 2024;In the second query, the YEAR() function blocks the use of the index on OrderDate, forcing a full scan.
The idea is to write conditions so that the column stands alone on one side of the comparison - no functions or complex expressions applied to it.
I usually check execution plans for “Index Seek” vs “Index Scan” to spot non-SARGable patterns.
What .NET engineers should know:
- 👼 Junior: Understand that SARGability helps SQL use indexes efficiently instead of scanning all rows.
- 🎓 Middle: Avoid functions, calculations, or mismatched types in WHERE clauses that block index seeks.
- 👑 Senior: Analyze execution plans and ORM-generated SQL (e.g., EF Core LINQ queries) for non-SARGable patterns; design indexes and predicates together for high-performance queries.
📚 Resources: What Is Sargability in SQL
❓ What’s the difference between a WHERE clause and a HAVING clause? Can you give a practical example of when you’d need HAVING?
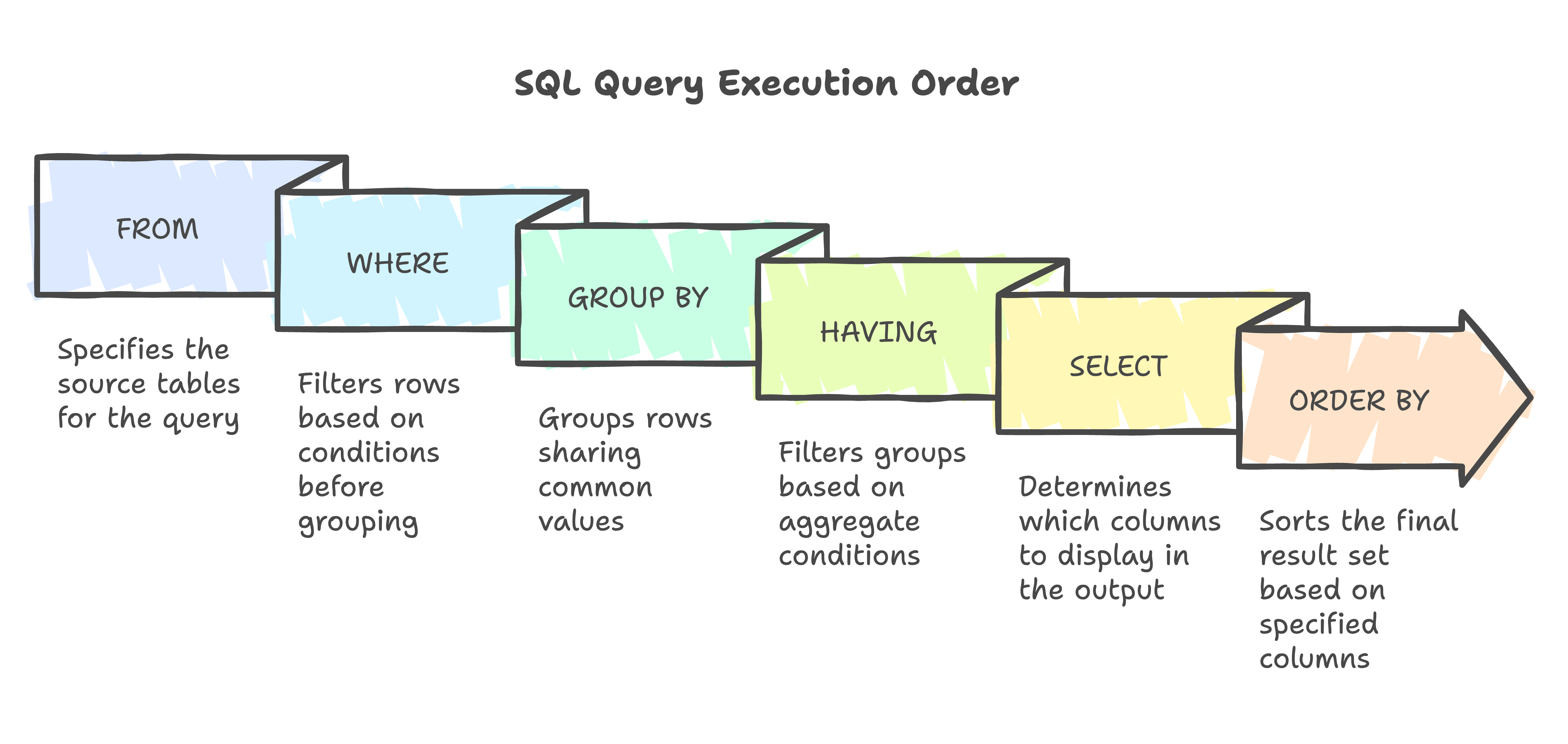
The difference lies in when each filter runs during query execution:
WHEREfilters rows before grouping/aggregation. “Give me all orders placed in 2025.”HAVINGfilters groups after aggregation. “Give me all customers who placed more than five orders in 2025.”
So if you’re working with raw rows, use WHERE. If you’re filtering based on an aggregate like COUNT(), SUM(), AVG(), you need HAVING.
Example: find customers with more than five orders.
-- Wrong (WHERE doesn’t see aggregated COUNT)
SELECT CustomerId, COUNT(*) AS OrderCount
FROM Orders
WHERE COUNT(*) > 5 -- ❌ invalid
GROUP BY CustomerId;
-- Correct (HAVING filters on aggregated result)
SELECT CustomerId, COUNT(*) AS OrderCount
FROM Orders
WHERE OrderDate >= '2025-01-01' AND OrderDate < '2026-01-01' -- ✅ Filter by year first
GROUP BY CustomerId
HAVING COUNT(*) > 5;Best practice:
- Use
WHEREfirst to reduce the data volume before grouping, it’s faster. - Only use
HAVINGfor aggregate conditions. - Some databases (e.g., PostgreSQL) may internally optimize
HAVINGwithout aggregates into aWHERE.
In EF Core, this maps to:
var result = db.Orders
.Where(o => o.OrderDate.Year == 2025)
.GroupBy(o => o.CustomerId)
.Where(g => g.Count() > 5)
.Select(g => new { CustomerId = g.Key, OrderCount = g.Count() });EF translates the second Where after the GroupBy into a SQL HAVING clause.
What .NET engineers should know:
- 👼 Junior: Know
WHEREfilters rows before grouping,HAVINGfilters after aggregation. - 🎓 Middle: Understand query execution order (
FROM → WHERE → GROUP BY → HAVING → SELECT) and filter early for performance. - 👑 Senior: Optimize aggregates and grouping operations, ensure correct index usage, and review generated SQL from LINQ group queries to avoid performance pitfalls.
📚 Resources:
❓ What's the difference between INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL OUTER JOIN?
Joins define how rows from two tables are combined. They determine which rows are included when there’s no matching data between the tables.
- INNER JOIN — returns only matching rows from both tables.
- LEFT JOIN — returns all rows from the left table and matching rows from the right; unmatched ones show
NULLon the right side. - RIGHT JOIN — the opposite of LEFT JOIN; all rows from the right, plus matching rows from the left.
- FULL OUTER JOIN — returns all rows from both tables, filling
NULLfor missing matches.
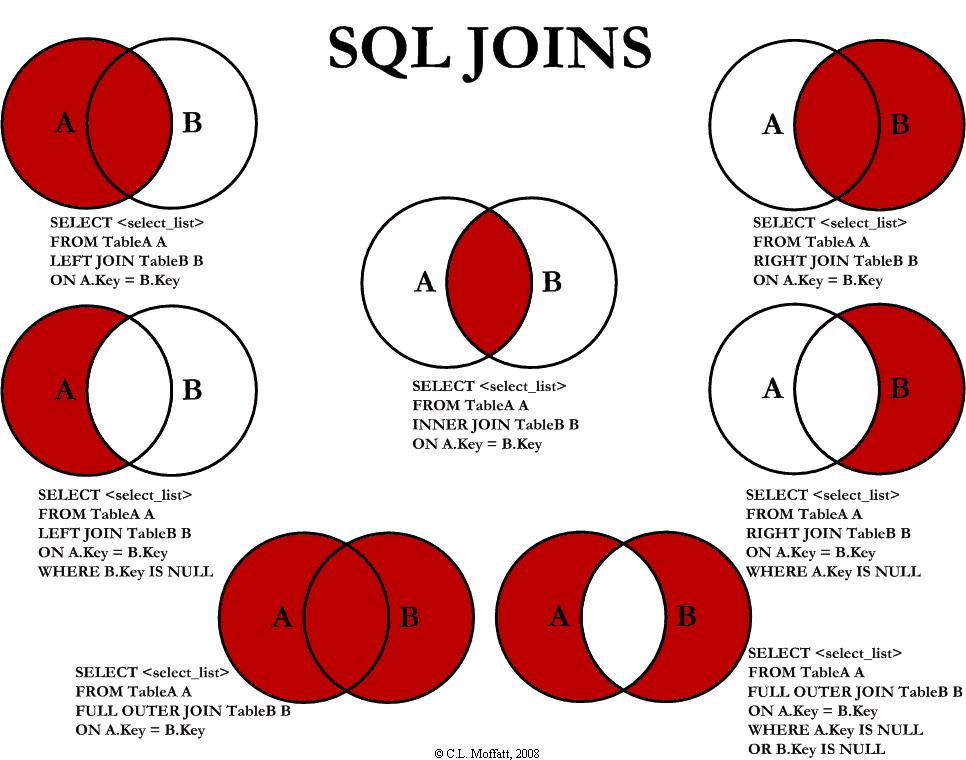
Example:
-- Tables: Users and Orders
-- INNER JOIN: only users who have orders
SELECT u.UserName, o.OrderDate
FROM Users u
INNER JOIN Orders o ON u.UserId = o.UserId;
-- LEFT JOIN: all users, even if no orders
SELECT u.UserName, o.OrderDate
FROM Users u
LEFT JOIN Orders o ON u.UserId = o.UserId;
-- RIGHT JOIN: all orders, even if user missing
SELECT u.UserName, o.OrderDate
FROM Users u
RIGHT JOIN Orders o ON u.UserId = o.UserId;
-- FULL OUTER JOIN: everything from both tables
SELECT u.UserName, o.OrderDate
FROM Users u
FULL OUTER JOIN Orders o ON u.UserId = o.UserId;💡 Best practices:
- Prefer
LEFT JOINinstead ofRIGHT JOIN— It’s clearer and more widely supported. - Use explicit
JOINsyntax (not comma joins). - Always filter joined data explicitly to avoid Cartesian products (huge cross-multiplication of rows).
In EF Core:
// INNER JOIN
var result = from u in db.Users
join o in db.Orders on u.UserId equals o.UserId
select new { u.UserName, o.OrderDate };
// LEFT JOIN
var leftJoin = from u in db.Users
join o in db.Orders on u.UserId equals o.UserId into userOrders
from o in userOrders.DefaultIfEmpty()
select new { u.UserName, o?.OrderDate };EF Core automatically translates LINQ joins to SQL INNER JOIN or LEFT JOIN.
What .NET engineers should know:
- 👼 Junior: Know INNER JOIN shows only matching rows, LEFT/RIGHT keep all rows from one side.
- 🎓 Middle: Understand when to use each join, and how NULL values appear in results.
- 👑 Senior: Optimize joins on large datasets (indexes, query plans), avoid Cartesian products, and design schemas that minimize unnecessary joins.
📚 Resources:
❓ Let's say you have a table for Posts and Comments. How would you model the database to retrieve a post along with all its associated comments efficiently?
The classic way is a one-to-many relationship:
- A
Poststable with a primary key (PostId). - A
Commentstable with a foreign key (PostId) pointing toPosts.
Schema:
CREATE TABLE Posts (
PostId INT PRIMARY KEY,
Title NVARCHAR(200),
Content NVARCHAR(MAX),
CreatedAt DATETIME2
);
CREATE TABLE Comments (
CommentId INT PRIMARY KEY,
PostId INT NOT NULL,
Author NVARCHAR(100),
Text NVARCHAR(MAX),
CreatedAt DATETIME2,
FOREIGN KEY (PostId) REFERENCES Posts(PostId)
);Query to fetch a post with its comments:
SELECT p.PostId, p.Title, p.Content, c.CommentId, c.Author, c.Text, c.CreatedAt
FROM Posts p
LEFT JOIN Comments c ON p.PostId = c.PostId
WHERE p.PostId = @postId
ORDER BY c.CreatedAt;Efficiency considerations:
- Index
Comments.PostIdfor fast lookups. - Use pagination if a post can have thousands of comments (
OFFSET ... FETCH). - In ORMs like EF Core, you can use eager loading:
// Eager loading (loads post + all comments)
var post = await db.Posts
.Include(p => p.Comments)
.FirstOrDefaultAsync(p => p.PostId == id);
// Lazy loading alternative (loads comments only when accessed)
db.ChangeTracker.LazyLoadingEnabled = true;
var post = await db.Posts.FindAsync(id);
var comments = post.Comments; // triggers lazy loadWhat .NET engineers should know:
- 👼 Junior: Know a post has many comments, linked by a foreign key.
- 🎓 Middle: Know how to query one-to-many related items using
JOINor EF Core.Include(). Handle pagination for extensive collections. - 👑 Senior: Optimize read-heavy scenarios by using caching, denormalized read models, or projections; tune EF loading strategies (eager, lazy, explicit) for scalability.
❓ How would you model a "self-referencing" relationship, like an employee-manager hierarchy, in a SQL table?
A self-referencing relationship means a table’s rows relate to other rows in the same table.
In an employee–manager hierarchy, both employees and managers are stored in a single table — a manager is simply another employee.
Table design
You add a column that references the same table’s primary key.
CREATE TABLE Employees (
EmployeeId INT PRIMARY KEY,
Name NVARCHAR(100) NOT NULL,
ManagerId INT NULL,
FOREIGN KEY (ManagerId) REFERENCES Employees(EmployeeId)
);EmployeeId- uniquely identifies each employee.ManagerId- points to another employee (their manager).- Top-level managers (like CEOs) have
NULLasManagerId.
Example data:
| EmployeeId | Name | ManagerId |
|---|---|---|
| 1 | Alice (CEO) | NULL |
| 2 | Bob | 1 |
| 3 | Carol | 2 |
| 4 | Dave | 2 |
This creates a simple hierarchy: Alice → Bob → Carol/Dave
Querying the hierarchy
Find direct reports:
SELECT * FROM Emloyees WHERE ManagerId = 2; -- Bob’s teamFind employee + manager name (self-join):
SELECT e.Name AS Employee, m.Name AS Manager
FROM Employees e
LEFT JOIN Employees m ON e.ManagerId = m.EmployeeId;Find complete hierarchy (recursive CTE):
WITH OrgChart AS (
SELECT EmployeeId, Name, ManagerId, 0 AS Level
FROM Employees
WHERE ManagerId IS NULL
UNION ALL
SELECT e.EmployeeId, e.Name, e.ManagerId, Level + 1
FROM Employees e
JOIN OrgChart o ON e.ManagerId = o.EmployeeId
)
SELECT * FROM OrgChart;Design considerations
- Add indexes on ManagerId for faster lookups.
- Use recursive CTEs for reporting and hierarchy queries.
- Prevent circular references (e.g., an employee managing themselves) with constraints or triggers.
What .NET engineers should know:
- 👼 Junior: Know
ManagerIdreferencesEmployeeIdin the same table. - 🎓 Middle: Understand how to query hierarchies using self-joins or recursive CTEs.
- 👑 Senior: Design for large org charts to use indexes, detect cycles, and consider hierarchyid (SQL Server) or closure tables for complex trees.
📚 Resources:
❓ What’s the difference between a Primary Key, Unique Key, and Foreign Key?
These three types of constraints define how data relate to and remain consistent in a relational database.
| Key Type | Purpose | Allows NULLs | Can have duplicates? | Example Use |
|---|---|---|---|---|
| Primary Key | Uniquely identifies each row in a table. | No | No | Id column in Users table |
| Unique Key | Ensures all values in a column (or combination) are unique. | Yes (one in SQL Server, multiple in PostgreSQL/MySQL) | No | Email in Users table |
| Foreign Key | Links a row to another table’s primary key to maintain referential integrity. | Yes | Yes | UserId in Orders table referencing Users.Id |
Example:
CREATE TABLE Users (
Id INT PRIMARY KEY,
Email NVARCHAR(100) UNIQUE,
Name NVARCHAR(100)
);
CREATE TABLE Orders (
Id INT PRIMARY KEY,
UserId INT,
FOREIGN KEY (UserId) REFERENCES Users(Id)
);- The Primary Key (
Users.Id) uniquely identifies each user. - The Unique Key (
Email) ensures no two users share the same email. - The Foreign Key (
Orders.UserId) ensures each order belongs to an existing user.
Best practices:
- Define indexes on foreign keys to improve join performance.
- Use composite keys when a single column doesn’t uniquely identify a record (e.g.,
(OrderId, ProductId)). - Avoid natural keys such as email addresses or usernames for PKs to use surrogate keys (INT or GUID).
In EF Core:
public class User
{
[Key] public int Id { get; set; }
[Index(IsUnique = true)] public string Email { get; set; } = null!;
public ICollection<Order> Orders { get; set; } = new List<Order>();
}
public class Order
{
[Key] public int Id { get; set; }
[ForeignKey(nameof(User))] public int UserId { get; set; }
public User User { get; set; } = null!;
}What .NET engineers should know:
- 👼 Junior: Understand that a Primary Key uniquely identifies a record, a Unique Key prevents duplicates, and a Foreign Key links related tables.
- 🎓 Middle: Know how these constraints enforce integrity in SQL and how EF Core represents them with
[Key],[Index(IsUnique=true)], and[ForeignKey]. - 👑 Senior: Design schemas with composite keys, cascade behaviors, and indexed foreign keys. Balance normalization with query performance.
📚 Resources:
❓ How do foreign keys affect data integrity and performance?
A foreign key enforces a relationship between two tables. It ensures that the value in one table (the child) matches an existing value in another (the parent), thereby maintaining referential integrity. But this integrity comes with a performance cost: every insert, update, or delete must be validated by the database.
Example:
CREATE TABLE Orders (
Id INT PRIMARY KEY,
CustomerId INT,
FOREIGN KEY (CustomerId) REFERENCES Customers(Id)
);This guarantees that every CustomerId in Orders exists in Customers.
Impact on performance:
- Every
INSERT,UPDATE, orDELETEmust check the parent table: adding a small validation cost. - Foreign keys can improve query plans when properly indexed (e.g., faster joins).
- Use
ON DELETE CASCADEorON UPDATE CASCADEcarefully convenient, but can cause large chained deletions.
When high-throughput writes are required (e.g., ETL, event ingestion), you may temporarily disable constraints or defer them until batch completion, but only when the application guarantees consistency.
In EF Core, foreign keys are automatically created for navigation properties unless configured otherwise:
modelBuilder.Entity<Order>()
.HasOne(o => o.Customer)
.WithMany(c => c.Orders)
.HasForeignKey(o => o.CustomerId)
.OnDelete(DeleteBehavior.Restrict);This maps directly to a SQL foreign key constraint.
What .NET engineers should know:
- 👼 Junior: Understand that foreign keys ensure data consistency. Every child row must reference an existing parent.
- 🎓 Middle: Know foreign keys add validation overhead on writes, but help query optimization when indexed.
- 👑 Senior: Design trade-offs when to use cascading deletes, when to disable or defer constraints for bulk inserts, and how to manage integrity in distributed or event-driven systems.
❓ When would you use a junction table in a many-to-many relationship?
A junction table (or bridge table) links two tables in a many-to-many relationship. Each record in one table can relate to many in the other, and vice versa. The junction table breaks this into two one-to-many relationships.
Example:
CREATE TABLE Students (
Id INT PRIMARY KEY,
Name NVARCHAR(100)
);
CREATE TABLE Courses (
Id INT PRIMARY KEY,
Title NVARCHAR(100)
);
CREATE TABLE StudentCourses (
StudentId INT,
CourseId INT,
PRIMARY KEY (StudentId, CourseId),
FOREIGN KEY (StudentId) REFERENCES Students(Id),
FOREIGN KEY (CourseId) REFERENCES Courses(Id)
);Here, StudentCourses connects students and courses. A student can enroll in many classes, and each course can have many students.
If the link itself has attributes (e.g., EnrollmentDate, Grade), the junction table becomes a fully modeled entity rather than just a connector.
In EF Core:
Implicit many-to-many (no explicit join entity):
modelBuilder.Entity<Student>()
.HasMany(s => s.Courses)
.WithMany(c => c.Students);Explicit junction entity (when you need extra fields):
public class StudentCourse
{
public int StudentId { get; set; }
public int CourseId { get; set; }
public DateTime EnrolledOn { get; set; }
}What .NET engineers should know:
- 👼 Junior: Understand that a junction table connects two tables when many-to-many relationships are required.
- 🎓 Middle: Know how to define and query many-to-many relationships and avoid storing lists of IDs in a single column.
- 👑 Senior: Choose between implicit EF Core many-to-many mappings and explicit junction entities. Optimize for large datasets by using proper indexes and handling cascade rules carefully.
🔍 Querying

❓ How would you return all users and their last order date, even if some users have no orders
You’d join the Users table with the Orders table using a LEFT JOIN, so users without orders still appear.
To get the last order date, use MAX(order_date) and group by the user.
Example:
SELECT
u.UserId,
u.UserName,
MAX(o.OrderDate) AS LastOrderDate
FROM Users u
LEFT JOIN Orders o
ON u.UserId = o.UserId
GROUP BY u.UserId, u.UserName
ORDER BY LastOrderDate DESC;This ensures:
- Users with orders display their most recent order date.
- Users with no orders still appear, but
LastOrderDatewill beNULL.
💡 Performance tip:
For large datasets, use a window function instead of grouping:
SELECT UserId, UserName, OrderDate
FROM (
SELECT
u.UserId, u.UserName, o.OrderDate,
ROW_NUMBER() OVER (PARTITION BY u.UserId ORDER BY o.OrderDate DESC) AS rn
FROM Users u
LEFT JOIN Orders o ON u.UserId = o.UserId
) AS ranked
WHERE rn = 1;
This avoids complete aggregation when you only need the most recent row per user.
What .NET engineers should know:
- 👼 Junior: Know how to join tables and why to use
LEFT JOINto keep all users. - 🎓 Middle: Understand grouping and aggregation (
MAX,GROUP BY), and how to handleNULLresults safely. - 👑 Senior: Optimize for scale use indexes on
UserIdandOrderDate, consider window functions for efficiency, and avoid unnecessary sorting in ORM queries.
📚 Resources:
❓ How does a subquery differ from a JOIN?
A JOIN combines data from multiple tables into one result set by linking rows that share a related key. A subquery runs a nested query first, then uses its result in the outer query often as a filter or computed value.
Both return similar results, but the JOIN is usually faster and more readable for multi-table queries.
Example (JOIN):
SELECT o.OrderId, u.UserName
FROM Orders o
JOIN Users u ON o.UserId = u.UserId;Example (Subquery):
SELECT OrderId
FROM Orders
WHERE UserId IN (SELECT UserId FROM Users WHERE IsActive = 1);When to use each:
- Use a JOIN when you need data from multiple tables displayed side by side.
- Use a subquery when you only need to reference another table’s value (like filtering or aggregation).
💡 Performance note: Modern SQL optimizers often rewrite subqueries as joins; however, correlated subqueries (those that reference the outer query) can be slower, as they may execute once per row. Prefer CTEs or JOINs for clarity and optimization hints in complex logic.
What .NET engineers should know:
- 👼 Junior: Understand that JOIN merges tables, while a subquery runs a query inside another query.
- 🎓 Middle: Know that JOINs are typically more efficient, but subqueries can simplify logic when you only need a single value or aggregate (like
MAX(),COUNT(), etc.). - 👑 Senior: Use subqueries carefully; they can hurt performance if executed per row. Replace with JOINs or CTEs whenever possible for clarity and to provide optimizer hints. Understand that some databases internally rewrite subqueries into joins.
📚 Resources: Joins SQL Server
❓ What is a Common Table Expression (CTE) and how does it differ from a temporary table?
A Common Table Expression (CTE) is a temporary, named result set defined within a query.
A temporary table is a physical object created in the temp database that can be reused within the same session.
Example scenario
We needed to find customers who placed multiple orders in the last 30 days and spent more than 10% above their average purchase value.
The original query had several nested subqueries and was hard to maintain, so it was refactored using a CTE:
CTE
WITH RecentOrders AS (
SELECT CustomerId, SUM(Amount) AS TotalSpent
FROM Orders
WHERE OrderDate >= DATEADD(DAY, -30, GETDATE())
GROUP BY CustomerId
),
AverageSpending AS (
SELECT CustomerId, AVG(Amount) AS AvgSpent
FROM Orders
GROUP BY CustomerId
)
SELECT r.CustomerId, r.TotalSpent, a.AvgSpent
FROM RecentOrders r
JOIN AverageSpending a ON r.CustomerId = a.CustomerId
WHERE r.TotalSpent > a.AvgSpent * 1.1;CTEs enhance readability by breaking down complex queries into logical components. They exist only during query execution.
Example with a temporary table:
SELECT * INTO #RecentOrders
FROM Orders WHERE OrderDate >= DATEADD(DAY, -30, GETDATE());
CREATE INDEX IX_RecentOrders_CustomerId ON #RecentOrders(CustomerId);Temporary tables persist for the duration of the session, can be indexed, and are helpful when the same data is reused multiple times.
When should you use a CTE vs. a temporary table?
| Technique | Use When | Advantages | Limitations |
|---|---|---|---|
| CTE | Query needs multiple logical steps or recursion | Improves readability; no cleanup needed | Re-evaluated on each reference |
| Temp Table | Data reused or needs indexing | Can persist and be optimized | Extra I/O and storage overhead |
CTEs can also be recursive, ideal for hierarchical data (e.g., employee trees, folder structures).
What .NET engineers should know:
- 👼 Junior: Know what CTEs and temp tables are and how they simplify complex queries.
- 🎓 Middle: Understand performance trade-offs, CTEs are inline, temp tables can be indexed and reused.
- 👑 Senior: Choose based on workload, use temp tables for large intermediate datasets and CTEs for clarity or recursion. In ORMs like EF Core, CTEs often appear in generated SQL for LINQ groupings or projections.
📚 Resources:
❓ What are window functions (ROW_NUMBER, RANK, DENSE_RANK, etc.), and where are they useful?
Window functions perform calculations across a set of rows related to the current row without collapsing them like GROUP BY does. They’re used for ranking, running totals, moving averages, and comparing rows within partitions.
Example:
SELECT
EmployeeId,
DepartmentId,
Salary,
ROW_NUMBER() OVER (PARTITION BY DepartmentId ORDER BY Salary DESC) AS RowNum,
RANK() OVER (PARTITION BY DepartmentId ORDER BY Salary DESC) AS RankNum,
DENSE_RANK() OVER (PARTITION BY DepartmentId ORDER BY Salary DESC) AS DenseRankNum
FROM Employees;ROW_NUMBER()gives unique sequential numbers.RANK()skips numbers when there are ties.DENSE_RANK()doesn’t skip numbers on relations.
Other common window functions:
SUM()/AVG()withOVER()running totals and moving averages.LAG()/LEAD()compare current and previous/next rows (e.g., change since last month).
💡 Performance tips:
- Index partition and order columns used in the window definition.
- Avoid sorting giant unindexed sets the
ORDER BYin a window function, as it can be expensive. - Prefer window functions over self-joins or correlated subqueries they’re more efficient and readable.
In EF Core, window functions can be written via raw SQL or newer LINQ support for RowNumber and pagination:
var employees = db.Employees
.OrderByDescending(e => e.Salary)
.Select((e, i) => new { e.Name, RowNumber = i + 1 })
.Take(10);What .NET engineers should know:
- 👼 Junior: Know that window functions let you number or compare rows without grouping them.
- 🎓 Middle: Use them for pagination, top-N queries, or comparisons. Know the differences between
ROW_NUMBER,RANK, andDENSE_RANK. - 👑 Senior: Optimize partitioning and ordering; apply window functions to replace self-joins or nested queries for better performance. Ensure indexing aligns with partition keys on large datasets.
📚 Resources: Introduction to T-SQL Window Functions
❓ You have a query that needs to filter on a column that can contain NULL values. What are some pitfalls to avoid?
In SQL, NULL means unknown, not “empty,” which affects comparisons, filters, and even indexes. SQL uses three-valued logic: TRUE, FALSE, and UNKNOWN. That’s why queries involving NULL behave differently than expected.
1. Comparisons with NULL
Comparing with = or != never returns TRUE:
SELECT * FROM Users WHERE Email = NULL; -- ❌ Always returns 0 rows✅ Correct way:
SELECT * FROM Users WHERE Email IS NULL;
SELECT * FROM Users WHERE Email IS NOT NULL;2. Beware of NOT IN with NULLs
If the subquery or list contains a NULL, your entire comparison fails because of SQL’s three-valued logic.
-- Suppose one of these Ids is NULL
SELECT * FROM Users WHERE Id NOT IN (SELECT UserId FROM BannedUsers);
-- ❌ Returns 0 rows if any UserId is NULL✅ Use NOT EXISTS instead:
SELECT * FROM Users u
WHERE NOT EXISTS (
SELECT 1 FROM BannedUsers b WHERE b.UserId = u.Id
);3. Indexes and NULLs
- Most databases include
NULLs in indexes, but their handling can differ. - SQL Server and PostgreSQLinclude them by default; PostgreSQL also allows partial indexes:
Example (exclude NULLs from index):
CREATE INDEX IX_Users_Email_NotNull
ON Users(Email)
WHERE Email IS NOT NULL;4. Aggregations skip NULLs
- Functions like
COUNT(column)ignore NULLs. - If you want to count all rows, use
COUNT(*).
-- Counts only non-null emails
SELECT COUNT(Email) FROM Users;
-- Counts all users
SELECT COUNT(*) FROM Users;5. Handle NULLs explicitly
Use COALESCE or ISNULL to replace unknowns:
SELECT COALESCE(Phone, 'N/A') FROM Users;Note:
In C#, null is not the same as SQL NULL. When using ADO.NET or EF Core, DBNull.Value represents a SQL null, ensure proper conversion when reading or writing nullable columns.
What .NET engineers should know:
- 👼 Junior: Understand
NULLmeans “unknown,” not empty. UseIS NULLandIS NOT NULL. - 🎓 Middle: Know pitfalls like
NOT INwithNULLs, and that aggregations skip nulls. Learn how indexing treats null values. - 👑 Senior: Design schema and defaults to minimize
NULLissues. Handle conversions properly in code (DBNullvsnull), and ensure queries, constraints, and ORM mappings behave consistently.
📚 Resources:
❓ How do you decide between using a JOIN in the database versus handling the relationship in your application code?
Whether to JOIN in SQL or in application code depends on where it’s cheaper and cleaner to combine the data.
Use a JOIN in the database when:
- Tables have a clear relational link (
Orders → Customers). - The database can perform filtering, aggregation, or sorting more efficiently.
- You want to minimize round-trips between the app and DB.
- Data volumes are moderate and join operations are well-indexed.
Example (JOIN in DB is usually better):
SELECT o.OrderId, u.UserName
FROM Orders o
JOIN Users u ON o.UserId = u.UserId;Handle in application code when:
- Data comes from multiple sources (SQL, external APIs, caches, or services).
- Joins would require complex logic that cannot be expressed in SQL (e.g., custom business rules, ML scoring, etc.)
- You’re batching or caching data to improve performance across requests.
- You need loose coupling (e.g., in microservices, separate read models per service).
If Users were in SQL, but order details came from a third-party API, you’d fetch them separately in C# and merge in memory.
In EF Core:
var orders = db.Orders
.Include(o => o.User) // Executes a JOIN
.ToList();Use .Include() or .ThenInclude() when data lives in the same DB. If the data comes from another source (e.g., an API), load it separately and merge it in memory.
What .NET engineers should know:
- 👼 Junior: Understand that
JOINcombines related tables, while app-side joins merge data after retrieval. - 🎓 Middle: Know when DB joins are more efficient and when app-side composition makes sense (e.g., combining SQL + API results).
- 👑 Senior: Decide on a join strategy based on latency, data ownership, and scalability. Avoid chatty queries; favor server-side joins for local data and app joins for distributed systems.
📚 Resources:
❓ What is the difference between COUNT(*) and COUNT(column_name)?
COUNT(*) counts all rows in the result set — including those with NULL values. COUNT(column_name) counts only rows where the column is not NULL.
Example:
SELECT
COUNT(*) AS TotalUsers, -- Counts all rows
COUNT(Email) AS UsersWithEmail -- Counts only rows where Email IS NOT NULL
FROM Users;In most databases (SQL Server, PostgreSQL, MySQL),
COUNT(*)does not read all columns; it’s internally optimized to count rows from metadata or index statistics.COUNT(1)behaves identically toCOUNT(*); it’s a common myth that it’s faster.
In EF Core:
var total = await db.Users.CountAsync();
var withEmail = await db.Users.CountAsync(u => u.Email != null);
Both queries translate directly to the correct SQL form (COUNT(*) vs COUNT(column)).
What .NET engineers should know:
- 👼 Junior: Remember that
COUNT(*)counts every row, whileCOUNT(column)skipsNULLs. - 🎓 Middle: Use
COUNT(column)when checking for filled fields; understand thatCOUNT(1)is not faster thanCOUNT(*). - 👑 Senior: Know how COUNT is optimized by the DB engine (metadata or index scans) and ensure correct semantic intent when using ORM predicates (
!= null).
❓ How can you pivot or unpivot data in SQL?
Pivoting converts rows into columns, summarizing data (e.g., totals by quarter).
Unpivoting does the opposite, it converts columns into rows, useful for normalizing wide tables.
Example (Pivot):
SELECT *
FROM (
SELECT Year, Quarter, Revenue
FROM Sales
) AS Source
PIVOT (
SUM(Revenue) FOR Quarter IN ([Q1], [Q2], [Q3], [Q4])
) AS PivotTable;Example (Unpivot):
SELECT Year, Quarter, Revenue
FROM SalesPivoted
UNPIVOT (
Revenue FOR Quarter IN ([Q1], [Q2], [Q3], [Q4])
) AS Unpivoted;Alternative (Cross-platform):
Not all databases support PIVOT syntax (e.g., MySQL).
You can achieve the same result with conditional aggregation:
SELECT
Year,
SUM(CASE WHEN Quarter = 'Q1' THEN Revenue END) AS Q1,
SUM(CASE WHEN Quarter = 'Q2' THEN Revenue END) AS Q2
FROM Sales
GROUP BY Year;
💡 Performance note:
- Always aggregate before pivoting large datasets.
- Ensure the pivot key (e.g.,
Quarter) has limited distinct values. - Avoid pivoting extremely wide datasets in OLTP systems, better to handle such reshaping in ETL or reporting layers.
What .NET engineers should know:
- 👼 Junior: Know that PIVOT turns rows into columns for summaries; UNPIVOT does the reverse.
- 🎓 Middle: Understand PIVOT syntax and how to emulate it using
CASE+GROUP BYwhen native syntax isn’t supported - 👑 Senior: Understand that
PIVOTcan be replaced with conditional aggregation usingCASE+GROUP BYfor flexibility and performance. Always validate indexing and memory usage when transforming large datasets.
📚 Resources: Using PIVOT and UNPIVOT
❓ How do you find duplicates in a table?
To find duplicates, group rows by the columns that define “uniqueness” and filter with HAVING COUNT(*) > 1.
Example:
SELECT Email, COUNT(*) AS Count
FROM Users
GROUP BY Email
HAVING COUNT(*) > 1;What .NET engineers should know:
- 👼 Junior: Learn to use
GROUP BYwithHAVING COUNT(*) > 1to detect duplicate values. - 🎓 Middle: Can join this result back to the original table to inspect complete duplicate rows or use
ROW_NUMBER()to keep only one instance and remove others. - 👑 Senior: Understand root causes (missing constraints, concurrent inserts, ETL logic). Prevent duplicates via unique indexes, transactions, and data validation, not just cleanup queries.
❓ What’s the difference between UNION and UNION ALL?
UNIONcombines results from multiple queries and removes duplicates.UNION ALLalso combines results but keeps all rows, including duplicates — it’s faster because it skips the distinct check.
In EF Core:
var query = db.Customers
.Select(c => new { c.Name, c.Email })
.Union(db.Subscribers.Select(s => new { s.Name, s.Email })); // UNION by default
var all = db.Customers
.Select(c => new { c.Name, c.Email })
.Concat(db.Subscribers.Select(s => new { s.Name, s.Email })); // UNION ALL equivalent
In LINQ, Union() performs DISTINCT behavior, while Concat() keeps duplicates.
What .NET engineers should know:
- 👼 Junior: Remember —
UNIONremoves duplicates,UNION ALLdoesn’t. - 🎓 Middle: Know
UNIONadds sorting overhead; preferUNION ALLfor large or non-overlapping datasets. - 👑 Senior: Understand that
UNIONrequires a sort or hash operation to eliminate duplicates. On large datasets, this can be costly — chooseUNION ALLwith downstream deduplication if performance matters more than strict uniqueness.
📚 Resources: Set Operators - UNION
📚 Indexing and Query Optimization

❓ What’s the difference between a clustered and a non-clustered index?
- A clustered index defines the physical order of data in a table — the table’s rows are stored directly in that index.
- A non-clustered index is a separate structure that stores key values and pointers (row locators) to the actual data.
Key difference between Clustered and non-clustered index:
| Feature | Clustered Index | Non-Clustered Index |
|---|---|---|
| Physical data order | Yes | No |
| Number per table | 1 | Many |
| Storage | Data pages are the index | Separate structure |
| Best for | Range scans, sorting | Targeted lookups, filters |
| Lookup cost | Direct (data is in index) | Requires key lookup to table |
Clustered index
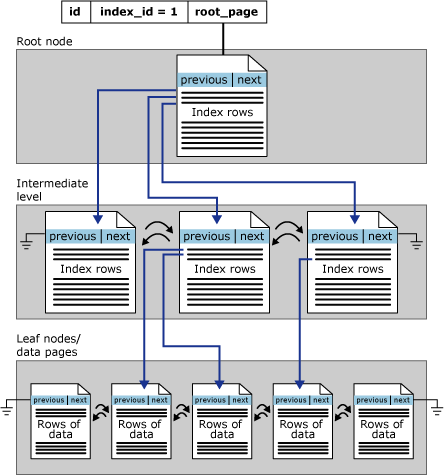
- A table can have only one clustered index.
- The data rows themselves are stored in that order.
- The clustered index key is automatically part of every non-clustered index.
Example:
CREATE CLUSTERED INDEX IX_Orders_OrderId
ON Orders(OrderId);This makes the table physically sorted by OrderId.
When to use: Primary key or frequently range-filtered column (e.g., OrderDate, Id).
Non-clustered index
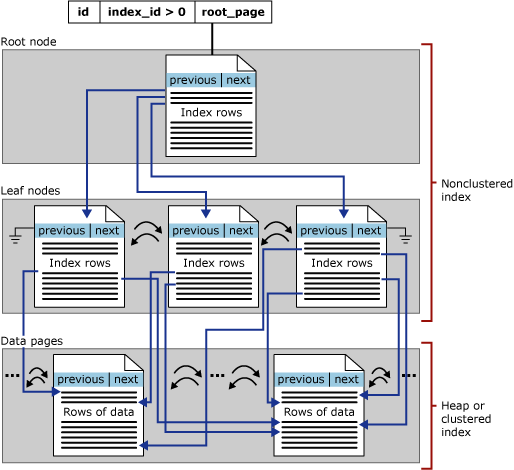
- Doesn’t change the data order, it’s a lookup table pointing to rows.
- You can have many non-clustered indexes.
- Useful for search-heavy queries on non-key columns.
Example:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerId
ON Orders(CustomerId);💡 Tip:
- Every table should have a clustered index, usually on the primary key.
- Add non-clustered indexes for frequent filters, joins, or sorts.
- Keep indexes lean; too many slow down inserts/updates.
What .NET engineers should know:
- 👼 Junior: Know clustered = main data order, non-clustered = secondary index.
- 🎓 Middle: Understand performance trade-offs and how SQL uses indexes for lookups and sorting.
- 👑 Senior: Design index strategies based on workload; balance reads vs writes, monitor fragmentation, and tune composite or covering indexes based on query patterns.
📚 Resources: Clustered and nonclustered indexes
❓ Can you explain what a composite index is and why the order of columns in it matters?
A composite index (or multi-column index) is built on two or more columns of a table.
It helps speed up queries that filter or sort by the same column combinations.
Example
CREATE INDEX IX_Orders_CustomerId_OrderDate
ON Orders(CustomerId, OrderDate);This index works efficiently for:
-- Uses both columns in the index
SELECT * FROM Orders
WHERE CustomerId = 42 AND OrderDate > '2025-01-01';…but not this one:
-- Only filters by OrderDate won't use the composite index efficiently
SELECT * FROM Orders
WHERE OrderDate > '2025-01-01';That’s because the index is sorted first by CustomerId, then by OrderDate. The column order defines which filters can use the index efficiently. The database can use the index for the leftmost prefix of the defined order.
💡 Best practices:
- Put the most selective column first, the one that filters out the most rows.
- Match column order to your most frequent query patterns.
- Avoid redundant indexes
(A, B)already covers(A)in most databases. - Use INCLUDE columns (SQL Server) for extra fields used in
SELECTto create a covering index.
In EF Core, the same logic applies queries must align with index column order:
// Uses both parts of the composite index
var orders = await db.Orders
.Where(o => o.CustomerId == 42 &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp; o.OrderDate > new DateTime(2025, 1, 1))
.ToListAsync();If you filter only by OrderDate, the database may perform an index scan instead of a seek.
What .NET engineers should know:
- 👼 Junior: Know that composite indexes combine multiple columns for faster lookups.
- 🎓 Middle: Understand that column order affects which queries can use the index.
- 👑 Senior: Design composite indexes based on query selectivity and workload patterns; avoid redundant indexes and use covering or filtered variants for critical queries.
📚 Resources:
❓ What are the different types of indexes available in SQL databases?
Indexes come in several flavors, each optimized for a different kind of query or storage strategy. Think of them like various kinds of maps; each one helps you find data faster, but in its own way.
1. Clustered Index
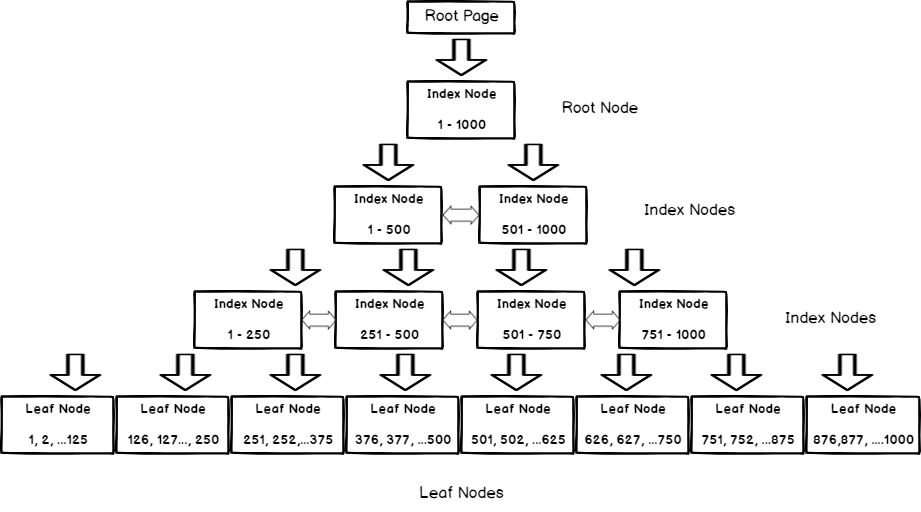
- Defines the physical order of table data.
Each table can have only one clustered index; the table is the index.
✅ Best for range queries, sorting, or primary key lookups.
CREATE CLUSTERED INDEX IX_Orders_OrderId ON Orders(OrderId);2. Non-Clustered Index
- Separate the structure from the table.
- Points to data rows (like a book index).
- You can have many per table.
- Supports quick lookups for frequently filtered columns.
✅ Great for frequent filters and lookups on non-key columns.
CREATE NONCLUSTERED INDEX IX_Orders_CustomerId ON Orders(CustomerId);3. Composite (Multicolumn) Index
Combines multiple columns into one index.
- ✅ Useful when queries filter or sort by a combination of columns.
- ⚠️ Column order matters —
(A, B)≠(B, A).
CREATE INDEX IX_Orders_CustomerId_OrderDate ON Orders(CustomerId, OrderDate);4. Covering Index (with Included Columns)
Includes all columns needed by a query so that the database can serve results without table lookups.
- ✅ Improves read performance, especially for frequent, read-heavy queries.
- ⚠️ Increases index size and slows writes.
CREATE NONCLUSTERED INDEX IX_Orders_CustomerId
ON Orders(CustomerId)
INCLUDE (OrderDate, Total);5. Unique Index
Ensures all indexed values are distinct often created automatically by PRIMARY KEY or UNIQUE constraints.
CREATE UNIQUE INDEX IX_Users_Email ON Users(Email);6. Filtered / Partial Index
Indexes only a subset of rows based on a condition.
- ✅ Saves space and speeds up targeted queries.
- ⚠️ Limited to databases that support it (e.g., SQL Server, PostgreSQL).
CREATE UNIQUE INDEX IX_Subscriptions_Active
ON Subscriptions(UserId)
WHERE IsActive = 1;7. Full-Text Index
Specialized for searching inside long text fields or documents. Supports CONTAINS / FREETEXT queries.
CREATE FULLTEXT INDEX ON Articles(Title, Body)
KEY INDEX PK_Articles;8. Spatial Index
Optimized for geolocation or geometric data (e.g., points, polygons).
Enables queries like “find locations within 10 km.”
CREATE SPATIAL INDEX SIDX_Locations_Geo ON Locations(Geo);9. Columnstore Index
Stores data in a columnar format rather than in rows.
Ideal for analytics and aggregation-heavy workloads (OLAP).
✅ Massive compression, optimized for SUM, COUNT, and AVG queries.
⚠️ Slower for frequent single-row lookups.
CREATE CLUSTERED COLUMNSTORE INDEX IX_Sales_ColumnStore ON Sales;10. Hash Index (Memory-Optimized Tables)
Used in in-memory database tables for constant-time lookups.
Available in SQL Server (In-Memory OLTP) and PostgreSQL hash indexes.
Summary
| Type | Stores Data | Unique | Best For | Trade-off |
|---|---|---|---|---|
| Clustered | Yes | Yes | Range scans, sorting | Only one per table |
| Non-Clustered | No | Optional | Filters and lookups | Extra lookups |
| Composite | No | Optional | Multi-column filters | Column order matters |
| Covering | No | Optional | Read-heavy queries | Larger index size |
| Unique | No | Yes | Data integrity | None |
| Filtered | No | Optional | Partial data sets | Limited support |
| Full-Text | No | Optional | Text search | Storage-heavy |
| Spatial | No | Optional | Geo queries | Complex setup |
| Columnstore | Columnar | Optional | Analytics workloads | Slow single-row ops |
EF Core
Doesn’t automatically create indexes, except for primary and foreign keys. You can define custom ones using the Fluent API:
modelBuilder.Entity<Order>()
.HasIndex(o => new { o.CustomerId, o.OrderDate })
.HasDatabaseName("IX_Orders_CustomerId_OrderDate");
What .NET engineers should know:
- 👼 Junior: Know basic index types (clustered, non-clustered, unique).
- 🎓 Middle: Understand composite, covering, and filtered indexes and their trade-offs.
- 👑 Senior: Design an overall indexing strategy, analyze query workloads, tune for selectivity, monitor index usage, and remove redundant or overlapping indexes.
📚 Resources: Index architecture and design guide
❓ How would you debug a slow query, and what tools would you use?
When a query is slow, start by verifying where the delay is coming from: app logic, the ORM, or the database itself.
Once it’s confirmed as a SQL issue, follow these steps:
1. Confirm the bottleneck
Before diving into SQL:
- Log timings at the app level (for example, EF Core logs SQL durations).
- Check whether the network, the ORM-generated SQL, or the database itself is causing the slowness.
Once you’re sure the query is the issue, it's time to go deeper.
2. Capture slow queries
| Database | Built-in Tools |
|---|---|
| SQL Server | Query Store, SQL Profiler, Extended Events |
| PostgreSQL | pg_stat_statements, log_min_duration_statement |
| MySQL / MariaDB | Slow Query Log, performance_schema, SHOW PROFILES |
| Oracle | Automatic Workload Repository (AWR) |
| SQLite | EXPLAIN QUERY PLAN |
3. Reproduce and measure
Run the query manually in your SQL tool (SSMS, pgAdmin, MySQL Workbench, etc.)
Note execution time, result size, and resource usage.
4. Check the execution plan
| Database | How to see plan | Example |
|---|---|---|
| SQL Server | Ctrl+M in SSMS > Include Actual Execution Plan | Identifies index scans, key lookups, bad joins. |
| PostgreSQL | EXPLAIN (ANALYZE, BUFFERS) | Shows real runtime and I/O cost. |
| MySQL | EXPLAIN ANALYZE (MySQL 8+) | Displays cost, row estimates, and actual timings. |
Look for:
- Table scans instead of index seeks.
- Large join loops or missing indexes.
- Misestimated row counts (outdated statistics).
5. Optimize
Common fixes:
- Add or tune indexes.
- Simplify joins and filters.
- Use selective
WHEREconditions. - Update statistics and ensure query parameters don’t trigger 'bad' plans (parameter sniffing).
- In MySQL/PostgreSQL, check buffer pool or work_mem settings for memory limits.
💡 In .NET / EF Core:
Use simple query logging or diagnostic interceptors:
optionsBuilder.LogTo(Console.WriteLine, LogLevel.Information);
You can also tag queries for easy tracking:
var query = db.Orders.TagWith("Top slow query: Orders Dashboard")
.Where(o => o.Status == "Pending");
What .NET engineers should know:
- 👼 Junior: Be able to identify slow queries via logs and EF Core timing; understand that database design affects performance.
- 🎓 Middle: Read execution plans, detect missing indexes or bad joins, and fix obvious inefficiencies.
- 👑 Senior: Diagnose advanced issues: parameter sniffing, plan cache reuse, or I/O bottlenecks; know when to recompile, refactor, or redesign data models.
📚 Resources:
❓ What is parameter sniffing, and how can it cause performance issues?
Parameter sniffing occurs when the database engine caches an execution plan for a query or stored procedure based on the first parameter values it receives and then reuses that plan for all subsequent executions, even when parameter values vary drastically.
Example of the problem
Let’s say you have a stored procedure:
CREATE PROCEDURE GetOrdersByCustomer
@CustomerId INT
AS
BEGIN
SELECT *
FROM Orders
WHERE CustomerId = @CustomerId;
END;- The first call might be for a small customer (10 orders).
- SQL builds a plan optimized for a few rows, likely using an Index Seek.
- The next call might be for a large customer (100,000 orders).
- The same cached plan runs, causing slow performance, perhaps a Nested Loop Join instead of a Hash Join.
That’s parameter sniffing a plan optimized for one scenario reused where it doesn’t fit.
🔍 Why parameter sniffing is happening
SQL Server and other databases cache query plans to save CPU time.
But if the data distribution is skewed (some customers have 10 rows, others 100k), the “sniffed” parameter can lead to inefficient plans for future calls.
✅ How to fix it
- If performance depends heavily on parameter values:
OPTIMIZE FOR UNKNOWNorRECOMPILE. - For predictable parameters, keep sniffing, as caching can improve overall performance.
Option 1 — Use local variables
This prevents the optimizer from “sniffing” the parameter value.
DECLARE @cid INT = @CustomerId;
SELECT * FROM Orders WHERE CustomerId = @cid;
Downside: the plan might not be fully optimized for any specific parameter, but it avoids extremes
Option 2 — Use OPTIMIZE FOR UNKNOWN
SELECT * FROM Orders
WHERE CustomerId = @CustomerId
OPTION (OPTIMIZE FOR UNKNOWN);Tell SQL Server to ignore the first parameter value and use general statistics instead.
Option 3 — Use RECOMPILE hint
SELECT * FROM Orders
WHERE CustomerId = @CustomerId
OPTION (RECOMPILE);Builds a new plan for each execution — always optimal, but more CPU-intensive.
✅ Always optimal for current parameters
⚠️ More CPU overhead — best for procedures run infrequently or with unpredictable data.
Option 4 — Manually clear or rebuild plans
- Clear cached plan:
DBCC FREEPROCCACHE;(use sparingly). - Rebuild statistics if they’re stale or skewed.
What .NET engineers should know:
- 👼 Junior: Know that stored procs can behave differently for different parameters.
- 🎓 Middle: Understand that cached query plans cause parameter sniffing; know how to fix it with
RECOMPILEorOPTIMIZE FOR UNKNOWN. - 👑 Senior: Diagnose sniffing with execution plans,
sp_BlitzCache, or Query Store; design queries and statistics to minimize skew effects in high-load systems.
📚 Resources:
❓ How does indexing improve read performance but slow down writes?
Indexes speed up reads, but each index adds maintenance work to writes.
When you INSERT, UPDATE, or DELETE a row:
- The table’s data is modified and
- Every related index must also be updated or rebalanced.
This extra work increases CPU, I/O, and sometimes lock contention.
Example:
CREATE INDEX IX_Users_Email ON Users(Email);Now queries are filtering by Email run much faster—but inserting or changing an email takes slightly longer because SQL must also insert into the index tree.
💡 Best practices:
- Create indexes only for columns used in
WHERE,JOIN, orORDER BY. - Avoid “just-in-case” indexes.
- Drop unused or duplicate indexes — check system views like:
SELECT * FROM sys.dm_db_index_usage_stats;
- Rebuild or reorganize fragmented indexes periodically.
- Use filtered, covering, or composite indexes for precision rather than many single-column indexes.
What .NET engineers should know:
- 👼 Junior: Indexes make reads faster but slow down writes because the database must keep them in sync.
- 🎓 Middle: Know how to design indexes for query patterns (
WHERE,JOIN,ORDER BY) and avoid over-indexing. - 👑 Senior: Balance read vs write workloads; minimize index count in high-write systems, use filtered or composite indexes, monitor fragmentation, and index maintenance schedules.
📚 Resources:
❓ Could you explain what a covering index is and how it can enhance performance?
A covering index (also called a covering or cover index) is an index that contains all the columns needed to satisfy a query, both for filtering and for returning data.
Because everything is already in the index, the database doesn’t have to go back to the main table (called a bookmark lookup or heap lookup) to fetch missing columns.
How it helps
- Fewer reads: The database doesn’t need to jump between the index and the table.
- Less I/O: Data is fetched from smaller index pages instead of whole table pages.
- Better caching: Indexes are often smaller and more likely to stay in memory.
However:
- Covering indexes take up more storage.
- They can slow down inserts and updates (because more data needs to be maintained).
- They should be used strategically for frequently executed, read-heavy queries.
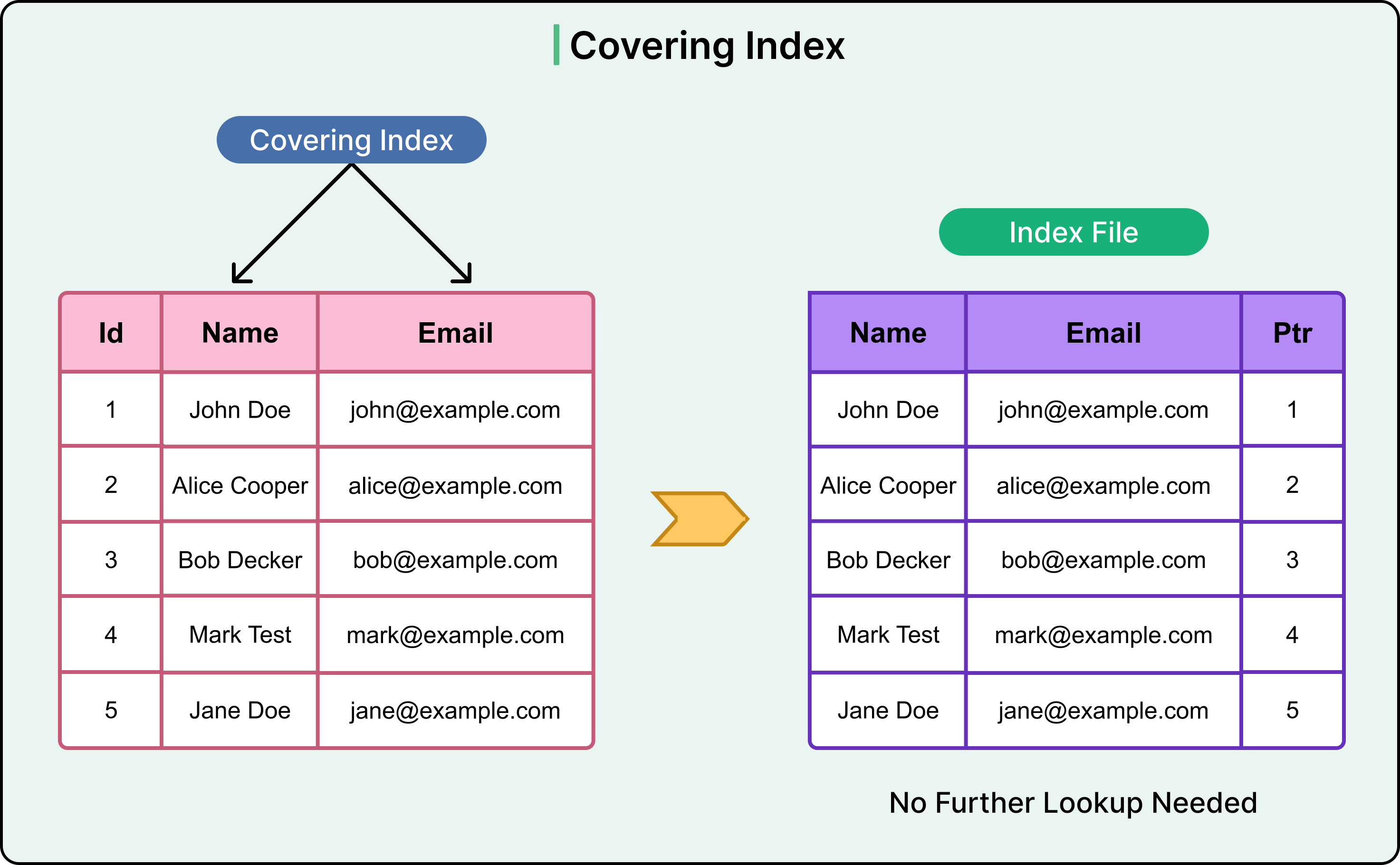
Example:
-- Suppose you often run this query:
SELECT FirstName, LastName
FROM Employees
WHERE DepartmentId = 5;
-- A normal index:
CREATE INDEX IX_Employees_DepartmentId ON Employees(DepartmentId);
-- A covering index:
CREATE INDEX IX_Employees_DepartmentId_Covering
ON Employees(DepartmentId)
INCLUDE (FirstName, LastName);In SQL Server, the INCLUDE clause adds extra columns to the index that aren’t part of the search key but can be returned directly.
In PostgreSQL or MySQL, the same concept applies the index can “cover” the query if all selected columns are in it, even without an explicit INCLUDE clause.
What .NET engineers should know:
- 👼 Junior: Understand that a covering index can make a query faster by including all the needed columns, so the engine doesn’t read the main table.
- 🎓 Middle: Know how to identify queries that benefit from covering indexes and how to use the
INCLUDEclause in SQL Server. Be aware of the trade-off between storage and slower writes. - 👑 Senior: Design indexes based on query patterns, use
INCLUDEefficiently, and read execution plans to confirm the index truly covers the query. Should know how this works in different engines SQL Server (INCLUDE), PostgreSQL (multi-column indexes), MySQL (InnoDB clustered indexes).
📚 Resources:
❓ What are the best practices for indexing large tables?
Indexing large tables is all about striking a balance, speeding up queries without compromising inserts, updates, and storage. Done right, indexes make reads lightning-fast; done wrong, they can cripple write performance and bloat your database.
Here’s how to handle them effectively:
1. Index what you query — not everything
Every index has a cost. Each write (insert, update, delete) must also update all related indexes.
✅ Index columns used in:
WHERE,JOIN,ORDER BY, orGROUP BY- Frequent lookups or range filters
⚠️ Avoid “just in case” indexes; they add cost but no benefit.
2. Use composite indexes for common filters
If queries often combine multiple conditions, build composite indexes matching those patterns.
CREATE INDEX IX_Orders_CustomerId_Date
ON Orders (CustomerId, OrderDate DESC);✅ Works efficiently for queries like:
WHERE CustomerId = 42 AND OrderDate > '2025-01-01'
3. Keep indexes lean
The larger the index, the more memory it consumes.
- Avoid broad indexes (more than 3–4 key columns).
- Exclude large text or blob fields.
- Use
INCLUDEfor non-key columns instead of adding them all to the key.
CREATE INDEX IX_Orders_Status
ON Orders (Status)
INCLUDE (OrderDate, Total);4. Maintain and rebuild regularly
Large tables suffer from index fragmentation due to insert and delete operations.
✅ Schedule maintenance:
ALTER INDEX ALL ON Orders REBUILD WITH (ONLINE = ON);
or use REORGANIZE for lighter defragmentation.
💡 For massive databases, use incremental or partition-level rebuilds.
5. Monitor index usage
Remove unused indexes and tune underused ones.
In SQL Server:
SELECT * FROM sys.dm_db_index_usage_stats;In PostgreSQL:
SELECT * FROM pg_stat_user_indexes;Check for:
- Unused indexes - Drop them.
- Missing indexes: add them where scans dominate.
6. Consider partitioning
For massive datasets, partition tables and indexes by date or range. This reduces scan size and allows parallel operations.
CREATE PARTITION SCHEME psOrderRange AS PARTITION pfOrderRange
TO ([PRIMARY], [FG2025]);
7. Evaluate specialized indexes
- Use filtered or partial indexes to target subsets of data.
- Use columnstore indexes for analytical (OLAP) queries.
- Use hash indexes or memory-optimized tables for hot data in in-memory systems.
What .NET engineers should know:
- 👼 Junior: Understand that indexes make queries faster but slow down writes; add them only where needed.
- 🎓 Middle: Know how to design and maintain indexes, use composites, INCLUDE, and monitor fragmentation or usage.
- 👑 Senior: Architect index strategies for high-scale systems, balance read/write ratio, schedule maintenance, partition large tables, and apply columnstore or filtered indexes for workload-specific optimization.
📚 Resources:
❓ How do database statistics affect query performance?
Statistics tell the query optimizer how data is distributed in a table — things like row counts, distinct values, and data ranges.
The optimizer uses them to select the most efficient execution plan. Outdated or missing statistics can lead to poor choices, such as full table scans instead of index seeks.
-- Manually update statistics
UPDATE STATISTICS Orders WITH FULLSCAN;Keeping stats fresh helps the optimizer make accurate cost estimates and avoid evil query plans.
💡 Best practices:
- Keep auto-update statistics enabled (the default in SQL Server, PostgreSQL, and MySQL).
- Trigger manual updates for significant changes (>20% of rows modified):
UPDATE STATISTICS Orders;- For massive datasets, use:
- FULLSCAN for precision (expensive, but accurate).
- INCREMENTAL STATS on partitioned tables.
- AUTO CREATE STATISTICS for dynamic columns in SQL Server.
- Rebuild indexes periodically; it updates statistics automatically.
What .NET engineers should know:
- 👼 Junior: Know that statistics guide how the DB decides to use indexes; stale stats can cause full scans.
- 🎓 Middle: Understand auto-update thresholds and when to manually refresh statistics for large tables.
- 👑 Senior: Diagnose bad query plans caused by skewed or outdated stats; compare before/after execution plans, use FULLSCAN or incremental stats for partitioned data, and monitor the cardinality estimator behavior.
📚 Resources:
❓ What is the purpose of the NOLOCK hint in SQL Server, and what are the serious risks of using it?
The NOLOCK table hint tells SQL Server to read data without acquiring shared locks, meaning it doesn’t wait for ongoing transactions.
It’s equivalent to running the query under the READ UNCOMMITTED isolation level.
Example:
-- Typical usage
SELECT * FROM Orders WITH (NOLOCK);This can make queries appear faster, because they don’t block or get blocked.
However, the trade-off is significant: the query may read uncommitted, inconsistent, or even corrupted data.
⚠️ Risks of using NOLOCK
- Dirty reads. You might see rows that were inserted or updated but later rolled back.
- Missing or duplicated rows. Page splits, or concurrent updates, can cause the same row to appear twice or not at all.
- Phantom reads. Data might change mid-scan, so aggregates like
SUM()orCOUNT()are unreliable. - Corrupted results during page splits. SQL Server might read half an old page and half a new one, returning nonsense values.
✅ Safer alternatives
- Use READ COMMITTED SNAPSHOT ISOLATION (RCSI) — it reads from a versioned snapshot instead of dirty data:
ALTER DATABASE MyAppDB SET READ_COMMITTED_SNAPSHOT ON;Reads are non-blocking and consistent.
- Optimize queries and indexes to reduce blocking rather than skipping locks.
- Use
WITH (READPAST)only when intentionally skipping locked rows (e.g., queue systems).
What .NET engineers should know:
- 👼 Junior: Know
NOLOCKskips locks to speed up reads, but can return incorrect data. - 🎓 Middle: Understand real effects, dirty reads, missing or duplicated rows, and wrong aggregates. Know safer alternatives like
READ COMMITTED SNAPSHOT. - 👑 Senior: Avoid
NOLOCKin production code unless you absolutely understand the trade-off. Should know how to tune queries, isolation levels, and indexing to achieve concurrency without sacrificing data integrity.
🧩 Advanced SQL Patterns
❓ What is a CHECK constraint, and when would you use it?
A CHECK constraint enforces a rule on column values. It ensures that only valid data gets stored in the table. It’s evaluated every time a row is inserted or updated.
For example:
CREATE TABLE Employees (
Id INT PRIMARY KEY,
Age INT CHECK (Age >= 18),
Salary DECIMAL(10,2) CHECK (Salary > 0)
);
Here, the database won’t accept any employee under 18 or with a non-positive salary.
What .NET engineers should know:
- 👼 Junior: A CHECK constraint ensures only valid data is inserted, such as checking that age is above 18.
- 🎓 Middle: Use them to keep insufficient data out of the database. They’re great for static business rules that don’t depend on other tables.
- 👑 Senior: Keep constraints close to the data when rules are consistent and lightweight. Avoid overusing them for complex validations that change often; that logic belongs in the service layer.
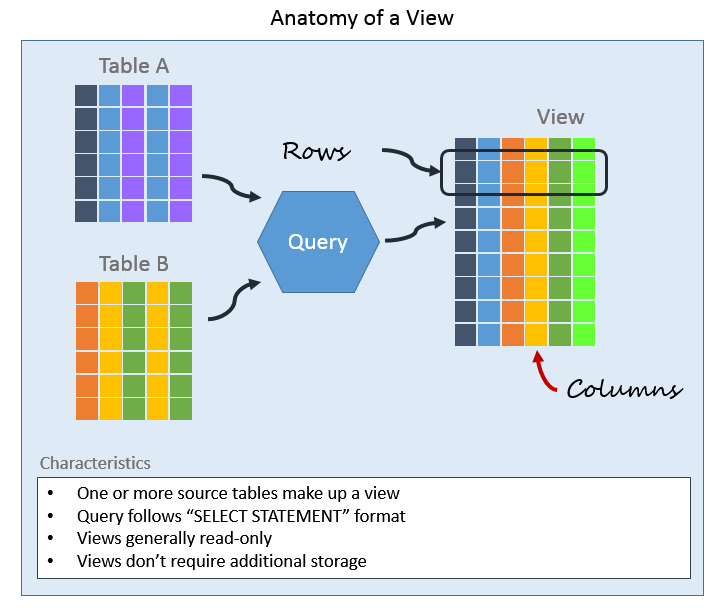
❓ When would you consider using a database view, and what are its limitations?
A view is a saved SQL query that acts like a virtual table. It doesn’t store data; it just stores the definition of a query that runs when you select from it. Views can simplify complex queries, improve security, and standardize access to data.
✅ When to use a view
1. Simplify complex queries
Instead of repeating joins or aggregations everywhere, wrap them in a view:
CREATE VIEW ActiveCustomers AS
SELECT Id, Name, Email
FROM Customers
WHERE IsActive = 1;Then use it efficiently:
SELECT * FROM ActiveCustomers;2. Encapsulate business logic
Centralize derived calculations to ensure multiple applications or reports share consistent results.
3. Improve security
Restrict users to specific columns or rows by granting access to the view instead of the base table.
4. Data abstraction layer
If table schemas change, you can preserve the exact view definition to avoid breaking queries in dependent applications.
⚠️ Limitations
1. Performance overhead
A view doesn’t store data; it re-runs the underlying query each time, which can be slow for heavy joins or aggregations.
2. Read-only in most cases
You usually can’t INSERT, UPDATE, or DELETE through a view unless it maps directly to a single base table (and even then, there are restrictions).
3. No automatic indexing
A view itself isn’t indexed, though you can create indexed/materialized views (if your DB supports them) to store results physically.
4. Maintenance complexity
If base tables change (column names are renamed or types are changed), views can break silently.
💡 When to avoid views
- For real-time, performance-critical queries, use materialized views or precomputed tables instead.
- When you need full CRUD operations.
- When application logic needs to shape data dynamically (views are static).
What .NET engineers should know:
- 👼 Junior: Know that a view is a saved SQL query that simplifies data access.
- 🎓 Middle: Understand how views help with abstraction and security, but can slow down complex queries.
- 👑 Senior: Use indexed/materialized views for performance, manage dependencies carefully, and monitor query plans for inefficiencies.
📚 Resources: Views SQL
❓ What’s the difference between views and materialized views?
Both views and materialized views represent saved SQL queries, but they differ in how they handle data storage and performance.
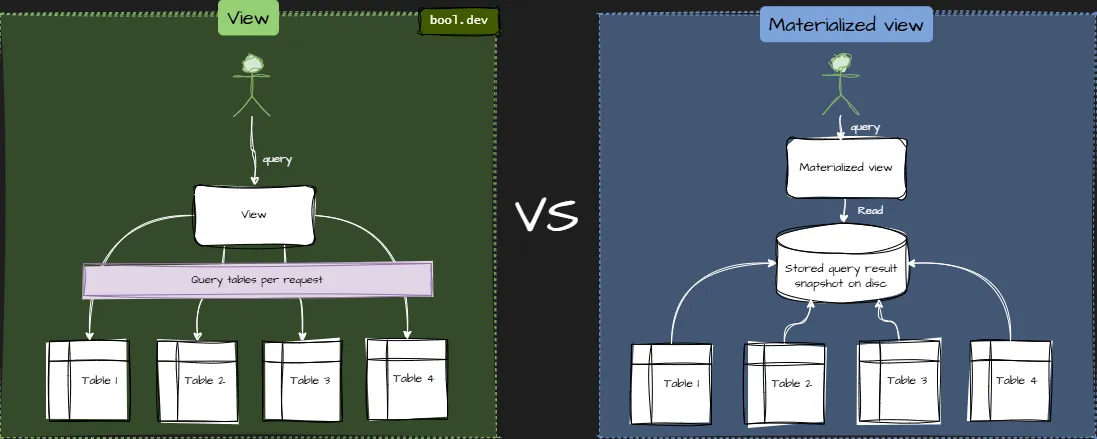
| Feature | View | Materialized View |
|---|---|---|
| Data storage | Doesn’t store data — runs query on demand | Stores query result physically |
| Performance | Slower for complex joins/aggregates | Much faster for repeated reads |
| Freshness | Always current | Must be refreshed |
| Indexing | Can’t be indexed directly (except indexed views in SQL Server) | Can be indexed normally |
| Use case | Lightweight abstraction, security, reusable logic | Analytics, dashboards, reporting, read models |
Example (PostgreSQL):
-- Regular view
CREATE VIEW ActiveCustomers AS
SELECT * FROM Customers WHERE IsActive = TRUE;
-- Materialized view
CREATE MATERIALIZED VIEW CustomerStats AS
SELECT Region, COUNT(*) AS Total
FROM Customers
GROUP BY Region;Refresh when data changes:
REFRESH MATERIALIZED VIEW CustomerStats;You can schedule refreshes or trigger them via events.
💡 Performance tip:
- Materialized views reduce load on large joins and aggregations.
- You can index them, unlike regular views.
- But stale data remains a risk; choose refresh intervals wisely.
- Some databases (like PostgreSQL) support concurrent refreshes to avoid locking.
What .NET engineers should know:
- 👼 Junior: Views show real-time data; materialized views store precomputed data for speed.
- 🎓 Middle: Understand refresh trade-offs, materialized views are faster but can become stale.
- 👑 Senior: Design refresh strategies (scheduled, trigger-based, or event-driven) and decide between SQL Server indexed views or PostgreSQL materialized views for reporting and caching layers.
📚 Resources:
❓ What are the pros and cons of using stored procedures?
Stored procedures are precompiled SQL scripts stored in the database. They can encapsulate logic, improve performance, and simplify maintenance, but they can also complicate versioning, testing, and scaling.
Stored Procedures Pros and Cons
- Pros: stable contract, plan caching, reduced wire traffic, centralized security/permissions, sometimes easier hot-fixing.
- Cons: portability and versioning friction, risk of duplicating domain logic in DB, and testing complexity.
Note: procs aren’t literally precompiled; execution plans are compiled on first use and cached. Use parameters; dynamic SQL inside a proc can still be injectable.
✅ When to use stored procedures:
- Data-heavy logic that benefits from server-side computation (reporting, aggregations, batch jobs).
- Security-critical operations that require strict validation at the database level.
- Systems with shared databases accessed by multiple services or tools.
❌ When not to:
- Application-level business logic that changes often.
- In microservices or DDD-based architectures, logic should live closer to the domain layer.
What .NET engineers should know:
- 👼 Junior: Stored procedures are reusable SQL scripts that run faster and help keep database logic secure.
- 🎓 Middle: They’re great for shared business rules and performance-critical operations, but hard to maintain in CI/CD pipelines.
- 👑 Senior: Use them strategically for data-heavy operations near the database layer. Avoid mixing too much app logic inside them; prefer code-based services when scalability, observability, or versioning matter.
📚 Resources: Stored procedures (Database Engine)
❓ How do you efficiently pass a list of values to a stored procedure in SQL Server versus PostgreSQL?
Both SQL Server and PostgreSQL can accept multiple values in a single call, but they handle them differently.
In SQL Server, you use Table-Valued Parameters (TVPs), while in PostgreSQL, you typically use arrays or unnest().
SQL Server: Table-Valued Parameters (TVP)
A TVP lets you pass a structured list (table) to a procedure.
You define a custom type once and reuse it.
-- Define a table type
CREATE TYPE IdList AS TABLE (Id INT);
-- Create stored procedure using TVP
CREATE PROCEDURE GetOrdersByIds @Ids IdList READONLY AS
BEGIN
SELECT * FROM Orders WHERE OrderId IN (SELECT Id FROM @Ids);
END;
-- Pass values from .NET
var ids = new DataTable();
ids.Columns.Add("Id", typeof(int));
ids.Rows.Add(1);
ids.Rows.Add(2);
using var cmd = new SqlCommand("GetOrdersByIds", conn);
cmd.CommandType = CommandType.StoredProcedure;
var param = cmd.Parameters.AddWithValue("@Ids", ids);
param.SqlDbType = SqlDbType.Structured;
cmd.ExecuteReader();- Pros: Fast, type-safe, avoids string parsing.
- Cons: SQL Server–specific.
PostgreSQL: Arrays and unnest()
PostgreSQL doesn’t have TVPs — instead, you can pass an array parameter and unpack it inside the query.
CREATE OR REPLACE FUNCTION get_orders_by_ids(ids int[])
RETURNS TABLE (order_id int, status text) AS $$
BEGIN
RETURN QUERY
SELECT o.id, o.status
FROM orders o
WHERE o.id = ANY(ids);
END;
$$ LANGUAGE plpgsql;
-- Call it
SELECT * FROM get_orders_by_ids(ARRAY[1, 2, 3]);You can also expand the array with unnest(ids) for joins or complex logic.
- Pros: Native, concise, and efficient.
- Cons: Doesn’t support structured types easily (only arrays of primitives).
What .NET engineers should know:
- 👼 Junior: Know that SQL Server and PostgreSQL handle lists differently — TVPs vs arrays. Understand that sending one significant parameter is better than concatenating strings like
'1,2,3'. - 🎓 Middle: Be able to create and use TVPs in SQL Server and arrays in PostgreSQL, understanding how to map them from .NET (
DataTable→ TVP,int[]→ array). - 👑 Senior: Know performance characteristics — batching vs TVP vs JSON, how to pass complex types (PostgreSQL composite types or JSONB), and when to offload this logic to the app layer.
📚 Resources:
❓ What’s the difference between temporary tables and table variables?
Temporary tables (#TempTable) and table variables (@TableVar) are used to store temporary data, but they differ in how they behave, how long they live, and how SQL Server optimizes them.
- Temporary tables act like real tables: they live in
tempdb, support indexes and statistics, and are visible to nested stored procedures. - Table variables live in memory (though also backed by
tempdb), don’t maintain statistics, and are scoped only to the current batch or procedure.
Example:
-- Temporary table
CREATE TABLE #TempUsers (Id INT, Name NVARCHAR(100));
INSERT INTO #TempUsers VALUES (1, 'Alice');
-- Table variable
DECLARE @Users TABLE (Id INT, Name NVARCHAR(100));
INSERT INTO @Users VALUES (2, 'Bob');Key Differences:
| Feature | #Temp Table | @Table Variable |
|---|---|---|
| Storage | tempdb | tempdb (lightweight) |
| Statistics | ✅ Yes | ❌ No (until SQL Server 2019+) |
| Indexing | ✅ Any index | Limited (PK/Unique only) |
| Transaction scope | ✅ Follows transaction | ❌ Not fully transactional |
| Recompilation | Can recompile for better plan | No recompile (fixed plan) |
| Performance | Better for large sets | Better for small sets |
| Scope | Session / connection | Batch / function |
What .NET engineers should know:
- 👼 Junior: Both store temporary data, but temporary tables are more flexible and better suited for larger datasets.
- 🎓 Middle: Use temporary tables when you need statistics or multiple joins. Use table variables for small lookups or for simple logic within a single procedure.
- 👑 Senior: Use temp tables for complex or large operations, TVPs for batch inserts from .NET, and monitor tempdb contention in high-load systems.
❓ How would you enforce a business rule like "a user can only have one active subscription" at the database level?
You can enforce it directly in the database using a filtered unique index or a trigger, depending on your database's capabilities.
Option 1: Unique filtered index (preferred)
If your database supports it (SQL Server, PostgreSQL), create a unique index that applies only when IsActive = 1.
CREATE UNIQUE INDEX UX_User_ActiveSubscription
ON Subscriptions(UserId)
WHERE IsActive = 1;This ensures that only one active subscription per user can exist; attempts to insert a second active one will fail automatically.
Option 2: Trigger-based validation
If your database doesn’t support filtered indexes, use a trigger to check before insert/update.
CREATE TRIGGER TR_EnsureSingleActiveSubscription
ON Subscriptions
AFTER INSERT, UPDATE
AS
BEGIN
IF EXISTS (
SELECT UserId
FROM Subscriptions
WHERE IsActive = 1
GROUP BY UserId
HAVING COUNT(*) > 1
)
BEGIN
ROLLBACK TRANSACTION;
RAISERROR('User cannot have more than one active subscription.', 16, 1);
END
END;This prevents commits that violate the business rule, regardless of how many concurrent requests hit the DB.
What .NET engineers should know:
- 👼 Junior: Know that database constraints can prevent invalid data even if the app misbehaves.
- 🎓 Middle: Understand filtered indexes and how they enforce conditional uniqueness.
- 👑 Senior: Design proper DB-level constraints and triggers to enforce rules safely under concurrency and heavy load.
📚 Resources:
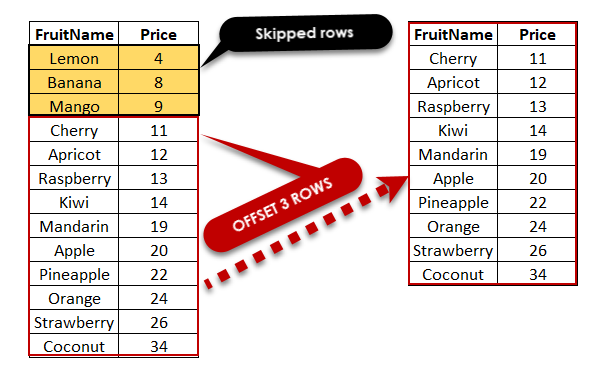
❓ What are some strategies for efficiently paginating through a huge result set, as opposed to using OFFSET/FETCH?
OFFSET/FETCH (or LIMIT/OFFSET) works fine for small pages, but it gets slower as the offset grows, the database still scans all skipped rows. For large datasets, you need smarter paging.
Better pagination strategies:
Keyset (Seek) Pagination
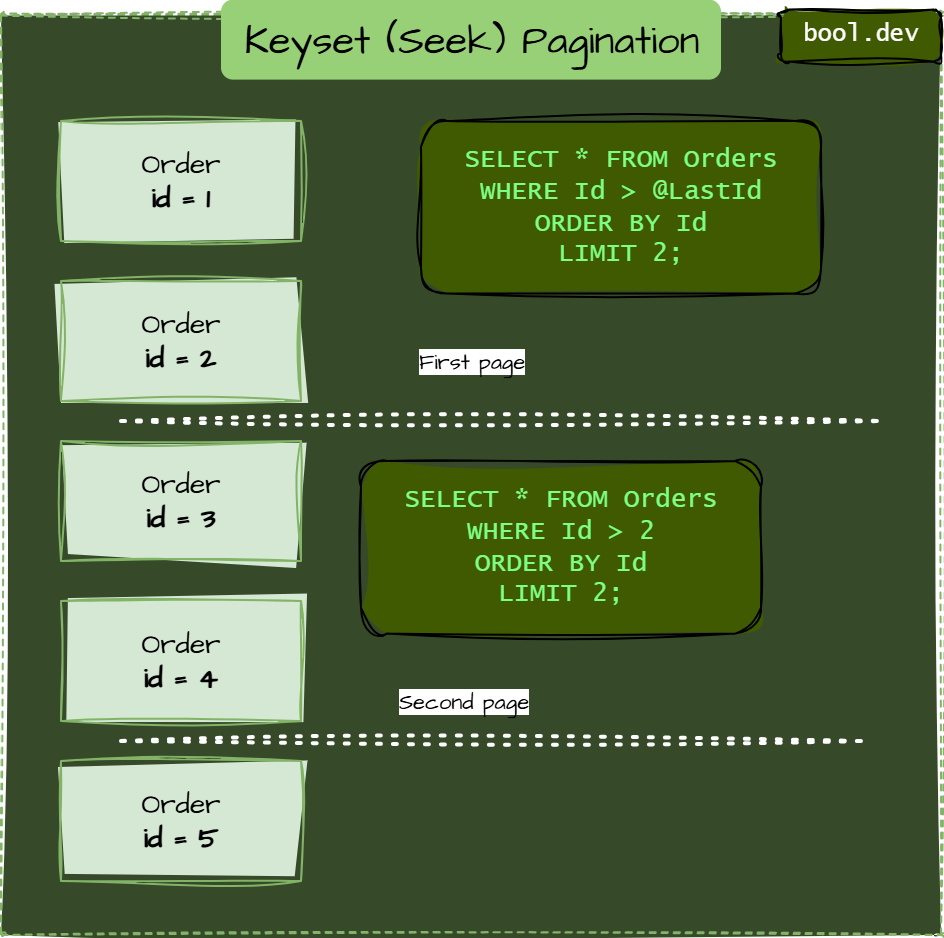
Use the last seen key instead of OFFSET.
SELECT * FROM Orders
WHERE Id > @LastId
ORDER BY Id
LIMIT 50;Fast because it uses an index and skips directly to the next page. Works only when your ID is sortable (is not suitable for UUID V4).
Bookmark Pagination
Used when sorting by multiple columns.
You remember the last record’s values and continue from them.
SELECT * FROM Orders
WHERE (OrderDate, Id) > (@LastDate, @LastId)
ORDER BY OrderDate, Id
FETCH NEXT 50 ROWS ONLY;
Precomputed / Cached Pagination /Snapshot pagination
For reports or exports, materialize results into a temp table or cache so paging doesn’t re-run the same heavy query each time.

Use proper index
Always ensure the ORDER BY columns are indexed; seek-based pagination relies on it.
What .NET engineers should know:
- 👼 Junior: Know that
OFFSETgets slower on big tables. - 🎓 Middle: Use keyset pagination for large or live data.
- 👑 Senior: Combine seek-based paging with caching, filtering, or precomputed datasets for scalable APIs.
📚 Resources: Pagination Strategies
❓ What is a trigger, and when should it be avoided?
A trigger is a special stored procedure that runs automatically in response to certain database events, such as INSERT, UPDATE, or DELETE. Triggers are useful for enforcing rules or auditing changes, but they can make logic hard to trace, debug, and maintain, especially when multiple triggers chain together.
Example:
CREATE TRIGGER trg_AuditOrders
ON Orders
AFTER INSERT, UPDATE
AS
BEGIN
INSERT INTO OrderAudit (OrderId, ChangedAt)
SELECT Id, GETDATE()
FROM inserted;
END;This trigger automatically logs every order creation or update.
When to Use:
- Enforcing data integrity rules not covered by constraints.
- Creating audit trails or history logs.
- Handling cascading actions (e.g., soft deletes).
When to Avoid:
- When business logic can live in the application layer.
- When triggers create hidden side effects that confuse other developers.
- When performance or scalability matters, triggers can cause recursive updates, slowing bulk operations.
What .NET engineers should know:
- 👼 Junior: Triggers run automatically after data changes, good for enforcing rules, but easy to misuse.
- 🎓 Middle: Use triggers mainly for auditing or strict integrity constraints. Avoid complex logic or multiple triggers on the same table.
- 👑 Senior: Keep the database lean, business rules belong in services, not triggers. If auditing is needed, prefer CDC (Change Data Capture), temporal tables, or event-based approaches for transparency and scalability.
📚 Resources: CREATE TRIGGER (Transact-SQL)
❓ How can you implement audit logging using SQL features?
Audit logging tracks who changed what and when in your database.
You can implement it using built-in SQL features like triggers, CDC (Change Data Capture), or temporal tables, depending on how detailed and real-time your auditing needs are.
Triggers (manual auditing):
CREATE TRIGGER trg_AuditOrders
ON Orders
AFTER UPDATE
AS
BEGIN
INSERT INTO OrderAudit (OrderId, ChangedAt, ChangedBy)
SELECT Id, GETDATE(), SUSER_SNAME()
FROM inserted;
END;- Pros: Simple to set up
- Cons: Harder to maintain, can affect performance
Change Data Capture (CDC):
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'Orders',
@role_name = NULL;- Pros: Automatically tracks all changes
- Cons: Requires SQL Server Enterprise or equivalent rights, adds storage overhead
Temporal (System-Versioned) Tables:
CREATE TABLE Orders (
Id INT PRIMARY KEY,
Amount DECIMAL(10,2),
SysStartTime DATETIME2 GENERATED ALWAYS AS ROW START,
SysEndTime DATETIME2 GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME (SysStartTime, SysEndTime)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.OrdersHistory));- Pros: Keeps a complete history of row changes automatically
- Cons: More storage, not suited for high-churn tables
What .NET engineers should know:
- 👼 Junior: Auditing means keeping a record of data changes, starting with triggers if you need a quick log.
- 🎓 Middle: Use CDC or temporal tables for reliable, built-in tracking. They’re safer and easier than custom trigger logic.
- 👑 Senior: Design audit logging based on business and compliance needs, choose between real-time CDC, temporal versioning, or external event-driven logs (e.g., outbox or change-feed patterns). Continually monitor storage and retention.
📚 Resources: Change Data Capture (CDC)
❓ How can you use SQL window functions to calculate rolling averages or cumulative totals?
You can use window functions like AVG() or SUM() with the OVER() clause to calculate rolling averages or running totals without collapsing rows like GROUP BY does. They let you look “across” rows related to the current one, often within a defined time or ordering window.
Cumulative total example:
SELECT
CustomerId,
OrderDate,
SUM(TotalAmount) OVER (PARTITION BY CustomerId ORDER BY OrderDate) AS RunningTotal
FROM Orders;This provides each customer with a running total of their order amounts in chronological order.
Rolling average example (last three orders):
SELECT
CustomerId,
OrderDate,
AVG(TotalAmount) OVER (
PARTITION BY CustomerId
ORDER BY OrderDate
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS RollingAvg3
FROM Orders;What .NET engineers should know:
- 👼 Junior: Use
SUM()orAVG()withOVER(ORDER BY …)to create running totals or averages. - 🎓 Middle: Learn how
PARTITION BYgroups data and how the frame (ROWS BETWEEN …) controls the range of rows included in the calculation. - 👑 Senior: Use window functions to replace self-joins or subqueries for analytics they’re faster and easier to maintain. Optimize with proper indexing on the
ORDER BYcolumn to avoid sorting overhead.
📚 Resources: SQL Window Functions
❓ ORM vs Raw SQL Query. When to Use What?
Both approaches have their strengths; the key is knowing when each is most suitable. Think of it like this: EF Core (ORM) is your daily driver, while raw SQL is your race car — more control, but more work.
Use ORM (like EF Core) when:
- You’re building CRUD-heavy apps (create, read, update, delete).
- Queries are either simple or moderately complex.
- You value maintainability and readability over absolute performance.
- You want LINQ, type-safety, and automatic model tracking.
- You don’t want to maintain SQL scripts across environments.
✅ Great for 90% of app queries.
⚠️ But it may generate less efficient SQL for big joins or analytics.
Use Raw SQL when:
- You need complex reporting, aggregations, or window functions.
- You’re chasing maximum performance, e.g., dashboards, exports, and analytics.
- You must use database-specific features (e.g., CTEs, stored procedures, and hints).
- You’re working with legacy databases or data sources outside EF’s model.
- You need fine-grained control over indexing, joins, or query plans.
✅ Perfect for heavy read/reporting queries.
⚠️ Harder to maintain, no compile-time checking.
Real-world approach:
- Most production systems use a hybrid:
- EF Core for standard business logic.
- Raw SQL for specialized data reporting or batch processing.
- Sometimes, stored procedures are used for long-running jobs or bulk operations.
What .NET engineers should know:
- 👼 Junior: Use EF Core by default; it’s easier, safer, and cleaner.
- 🎓 Middle: Mix EF and raw SQL when performance or complexity requires it.
- 👑 Senior: Profile, measure, and choose based on data size, complexity, and maintainability, not personal preference.
📚 Resources:
🔒 Concurrency, Transactions, and Isolation
❓ How would you explain the difference between the DB isolation levels?
Isolation levels define how much one transaction can “see” from another before it’s committed. The stricter the level, the safer your data, but the slower your system.
When multiple users read and modify the same data at once, three things can go wrong:
- Dirty Read — You read uncommitted data from another transaction.
Example: someone updates a balance, you read it, and then they roll back; you saw data that never existed. - Non-Repeatable Read — You read the same row twice, but its value changed between reads.
Example: you check an order’s status at the start and end of your transaction, and it’s different. - Phantom Read — You re-run a query and get a new row that didn’t exist before.
Example: between two reads, another transaction inserts a new record matching your WHERE clause.
| Level | Prevents Dirty Reads | Prevents Non-Repeatable Reads | Prevents Phantom Reads | Notes |
|---|---|---|---|---|
| Read Uncommitted | ❌ | ❌ | ❌ | Fastest, but least safe |
| Read Committed | ✅ | ❌ | ❌ | Default in SQL Server |
| Repeatable Read | ✅ | ✅ | ❌ | Keeps read locks until commit |
| Serializable | ✅ | ✅ | ✅ | Most consistent, slowest |
| Snapshot | ✅ | ✅ | ✅ | Uses row versioning instead of locks |
Example: How to set Isolation level:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN TRAN
SELECT * FROM Orders WHERE Status = 'Pending';
-- Another transaction modifies Orders here
SELECT * FROM Orders WHERE Status = 'Pending'; -- may return different results
COMMIT;If you switch to REPEATABLE READ SQL Server will lock the rows you selected, so the second query sees the same data, but updates from others will be blocked.
What .NET engineers should know:
- 👼 Junior: Understand what dirty, non-repeatable, and phantom reads are. Know that isolation levels help prevent these concurrency issues.
- 🎓 Middle: Be able to pick the correct isolation level for a use case. Understand trade-offs: more isolation = less concurrency.
- 👑 Senior: Know how isolation levels work under the hood (locking vs MVCC), tune them per operation, and use
SNAPSHOTor retry strategies to handle high-load concurrency safely in distributed systems.
❓ What’s the difference between pessimistic and optimistic locking?
Pessimistic locking means you lock a record as soon as you start working with it, so no one else can change it until you’re done.
Optimistic locking lets multiple users read and work on the same data, but before saving, it checks if someone else has already updated it.
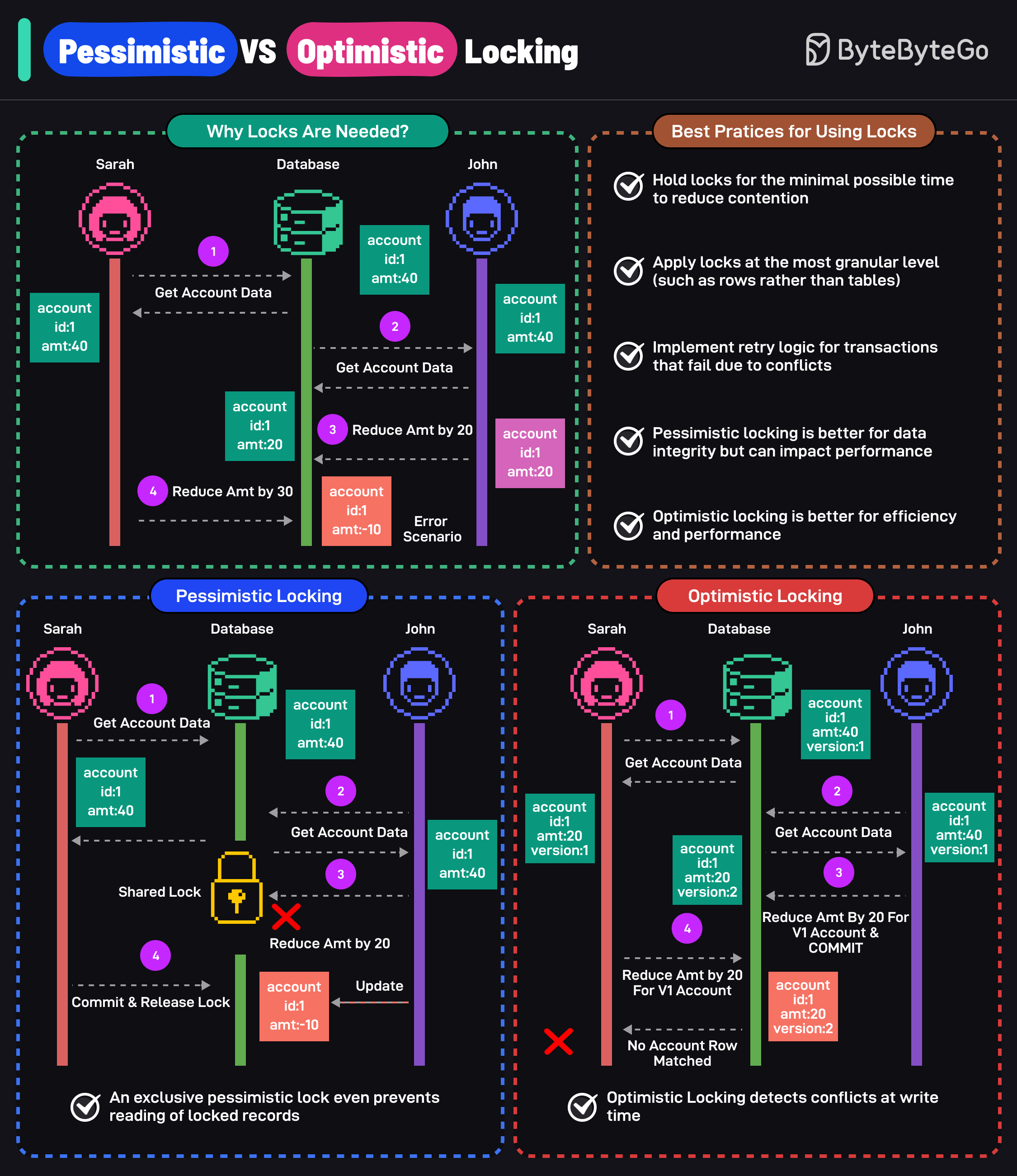
Pessimistic locking example:
BEGIN TRAN;
SELECT * FROM Accounts WITH (UPDLOCK, ROWLOCK) WHERE Id = 1;
UPDATE Accounts SET Balance = Balance - 100 WHERE Id = 1;
COMMIT;Here, the row is immediately locked, blocking other writes until the transaction completes.
Optimistic locking example (EF Core):
public class Account
{
public int Id { get; set; }
public decimal Balance { get; set; }
[Timestamp]
public byte[] RowVersion { get; set; }
}EF Core adds the RowVersion to the WHERE clause during updates. If the row was changed by someone else, the update fails, and the app decides how to handle it (e.g., retry or show an error).
What .NET engineers should know:
- 👼 Junior: Pessimistic locks the data right away. Optimistic checks for changes only when saving.
- 🎓 Middle: Use pessimistic when updates must be serialized, like in finance systems. Use optimistic in web apps or APIs where most operations don’t overlap.
- 👑 Senior: Choose based on workload and contention. Pessimistic is safer but reduces throughput; optimistic provides higher concurrency but requires conflict handling in the code.
📚 Resources:
❓ How do you detect and prevent deadlocks?
A deadlock occurs when two or more transactions block each other, each holding a lock that the other needs. SQL Server detects the situation and kills one transaction (the “victim”) with error 1205.
The fix is to find which statements lock the same resources and in what order.
How can a deadlock happen?
-- Session 1
BEGIN TRAN
UPDATE Orders SET Status = 'Processing' WHERE Id = 1;
WAITFOR DELAY '00:00:05';
UPDATE Customers SET Name = 'John' WHERE Id = 1;
COMMIT;
-- Session 2
BEGIN TRAN
UPDATE Customers SET Name = 'Alice' WHERE Id = 1;
WAITFOR DELAY '00:00:05';
UPDATE Orders SET Status = 'Pending' WHERE Id = 1;
COMMIT;Each transaction locks one table, then waits for the other to lock a table, resulting in a classic deadlock.
How to handle it in application code
// Example of retrying a transaction that failed due to a deadlock
for (int attempt = 1; attempt <= 3; attempt++)
{
try
{
using var connection = new SqlConnection(connString);
connection.Open();
using var tx = connection.BeginTransaction();
// Some update logic here...
tx.Commit();
break;
}
catch (SqlException ex) when (ex.Number == 1205)
{
// Deadlock detected - retry the transaction
Thread.Sleep(200 * attempt);
}
}This snippet demonstrates a retry policy, a common approach for graceful recovery when a transaction is rolled back due to a deadlock.
What .NET engineers should know:
- 👼 Junior: Understand what a deadlock is: two processes waiting on each other. Know that SQL Server aborts with error 1205.
- 🎓 Middle: Be able to capture and analyze deadlock graphs, identify lock order conflicts, and fix design issues (consistent table access order, shorter transactions, better indexing).
- 👑 Senior: Understand locking internals, apply retry logic with idempotent operations, tune isolation levels, and design schema or workflows to minimize contention in distributed or high-load systems.
📚 Resources: Deadlocks guide
❓ How would you design a retry policy for failed transactions?
A retry policy helps your system recover from temporary issues, such as deadlocks, timeouts, or network hiccups — without requiring user intervention.
The key is to retry safely: only for transient errors and with a proper delay between attempts.
Example (C# with Polly):
var retryPolicy = Policy
.Handle<SqlException>(ex => ex.Number == 1205) // deadlock
.Or<TimeoutException>()
.WaitAndRetry(
retryCount: 3,
sleepDurationProvider: attempt => TimeSpan.FromSeconds(Math.Pow(2, attempt)) // exponential backoff
);
retryPolicy.Execute(() =>
{
// Database operation
SaveChanges();
});This retries the operation up to 3 times, waiting 2, 4, and 8 seconds between attempts.
Best practices:
- Retry only idempotent operations (safe to repeat multiple times).
- Use exponential backoff to avoid overloading the DB.
- Add jitter (random delay) to prevent synchronized retries.
- Log every retry and failure for diagnostics.
- Stop retrying after a few attempts, don’t loop forever.
What .NET engineers should know:
- 👼 Junior: A retry policy automatically repeats failed operations, useful for temporary errors.
- 🎓 Middle: Use exponential backoff and retry only transient issues, such as deadlocks or timeouts. Don’t retry logic errors.
- 👑 Senior: Design retries with idempotency, circuit breakers, and observability in mind. Combine with transaction scopes or outbox patterns for guaranteed consistency in distributed systems.
🛠️ Database Maintenance and System Design

❓ What’s the difference between OLTP and OLAP systems?
OLTP (Online Transaction Processing) handles real-time operations, including inserts, updates, and deletes, for day-to-day business activities.
OLAP (Online Analytical Processing) is designed for analytics, processing large volumes of data to generate reports, dashboards, and trend analyses.
What .NET engineers should know:
- 👼 Junior: OLTP is for live operations (like processing an order). OLAP is for analyzing data later.
- 🎓 Middle: OLTP maintains data normalization for consistency; OLAP stores it in a denormalized format for speed. Use OLTP for transactions and ETL pipelines to feed OLAP for reporting.
- 👑 Senior: Architect them separately. OLTP for system-of-record workloads, OLAP for analytical queries.
Use ETL or ELT pipelines to sync them and avoid performance hits on production databases.
📚 Resources:
❓ What is table bloat in PostgreSQL, and how does the autovacuum process help manage it?
In PostgreSQL, table bloat occurs when a table or index contains a large number of dead tuples — old row versions that remain after updates or deletes.
Unlike some databases, PostgreSQL uses MVCC (Multi-Version Concurrency Control), which never updates data in place. Instead, it creates a new row version and marks the old one as obsolete once no active transaction needs it. Over time, those dead tuples accumulate, wasting disk space and slowing sequential scans.
That’s where autovacuum comes in.
It’s a background process that automatically:
- Scans tables for dead tuples.
- Mark's unused space as reusable (via
VACUUM). - Updates visibility maps so queries can skip clean pages.
- Optionally runs
ANALYZEto refresh statistics.
Without autovacuum, bloat grows until queries slow down or the disk fills up.
Example: Manually trigger vacuum if autovacuum can't keep up
VACUUM ANALYZE orders;
-- Check for bloat using pg_stat views
SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
ORDER BY n_dead_tup DESC;You can also tune autovacuum in postgresql.conf:
autovacuum = on
autovacuum_vacuum_scale_factor = 0.2
autovacuum_analyze_scale_factor = 0.1This means that a vacuum runs when 20% of rows are dead or when 10% of changes need re-analysis.
What .NET engineers should know:
- 👼 Junior: Understand that PostgreSQL doesn’t delete rows instantly; old versions remain and can cause “bloat.” Know that autovacuum cleans it up automatically.
- 🎓 Middle: Know how to check autovacuum activity via
pg_stat_activityand tune parameters likeautovacuum_vacuum_scale_factor. Recognize symptoms of bloat, increasing table size, and slower queries. - 👑 Senior: Be able to diagnose severe bloat using tools like
pgstattuple, decide when to runVACUUM FULLorREINDEXand design update-heavy workloads to reduce bloat (e.g., avoid frequent minor updates and use partitioning).
📚 Resources: sql-vacuum
❓ What are database partitions, and when should you use them?
Partitioning splits a large table or index into smaller, more manageable pieces while keeping them logically as one table.
It improves performance, scalability, and maintenance for large datasets by letting the database work on smaller chunks.
CREATE PARTITION FUNCTION OrderDateRangePFN (DATE)
AS RANGE LEFT FOR VALUES ('2023-12-31', '2024-12-31');
CREATE PARTITION SCHEME OrderDateRangePS
AS PARTITION OrderDateRangePFN
TO ([PRIMARY], [FG_2024], [FG_2025]);
CREATE TABLE Orders (
Id INT PRIMARY KEY,
OrderDate DATE,
Amount DECIMAL(10,2)
) ON OrderDateRangePS(OrderDate);This partitions the Orders table by year, each year’s data can live on a different filegroup.
When to use partitioning:
- Tables grow into tens or hundreds of millions of rows.
- You need faster queries on specific data ranges (e.g., by date).
- You want to archive or delete old data efficiently (by switching or dropping partitions).
- You run ETL or analytics on large datasets without locking the entire table.
Avoid it when:
- Tables are small, or queries already perform well with indexes.
- It adds unnecessary complexity without measurable benefit.
What .NET engineers should know:
- 👼 Junior: Partitioning breaks a big table into smaller parts, but you still query it as one.
- 🎓 Middle: Use it for large, date-driven tables to speed up queries and simplify maintenance, such as archiving or rolling data windows.
- 👑 Senior: Plan partition keys carefully, as they affect query performance and maintenance costs. Combine partitioning, indexing, and compression for high-scale systems.
📚 Resources: Partitioned tables and indexes
❓How would you archive old records without affecting query performance?
Archiving means moving old, rarely accessed data out of your main tables to keep them small and fast.
The key is to separate hot (active) and cold (historical) data so queries only scan what’s relevant.
Common approaches:
1. Table partitioning (best for large datasets):
Keep old data in separate partitions and move it to an archive table.
ALTER TABLE Orders
SWITCH PARTITION 1 TO OrdersArchive PARTITION 1;✅ Zero downtime, minimal locking
⚠️ Requires partitioned tables set up correctly
2. Scheduled archiving jobs:
Periodically move or delete records with a SQL Agent job or a background service.
INSERT INTO OrdersArchive
SELECT * FROM Orders WHERE OrderDate < '2024-01-01';
DELETE FROM Orders WHERE OrderDate < '2024-01-01';✅ Simple and flexible
⚠️ Must run during off-peak hours, requires proper indexing and batching
3. Separate archive database:
Store archived data in a dedicated database or a less expensive storage option (e.g., Azure SQL Hyperscale, S3).
Your app can still query it through a linked server or API when needed.
✅ Keeps production DB light
⚠️ Increases query complexity if historical data is often needed.
What .NET engineers should know:
- 👼 Junior: Move old data to another table to keep active queries fast.
- 🎓 Middle: Use partitioning or scheduled jobs to archive by date or status. Keep indexes on active data lean.
- 👑 Senior: Design for data lifecycle — use partition switching for instant archival, automate retention policies, and store cold data on cheaper storage tiers. Constantly monitor index fragmentation and query plans after archiving.
❓ How would you secure sensitive data at rest and in transit?
Data security comes down to two layers:
- At rest: protecting stored data (in files, databases, backups).
- In transit: protecting data while it’s moving over the network.
You use encryption, access control, and secure connections for both.
1. Data at rest (stored data):
- Use Transparent Data Encryption (TDE) to encrypt entire databases on disk.
- Use column-level encryption or Always Encrypted for specific fields, such as SSNs or credit card numbers.
- Secure backups with encryption and restrict file-level permissions.
Example: enabling TDE
CREATE DATABASE ENCRYPTION KEY
WITH ALGORITHM = AES_256
ENCRYPTION BY SERVER CERTIFICATE MyServerCert;
ALTER DATABASE MyAppDB SET ENCRYPTION ON;2. Data in transit (network data):
- Always connect over TLS (SSL) — this encrypts the data between the client and server.
- Disable plain TCP connections and enforce encrypted connections in connection strings.
- Use VPNs, private endpoints, or firewalls for sensitive environments.
// Example: Enforce encryption in connection string
"Server=myserver;Database=mydb;Encrypt=True;TrustServerCertificate=False;"3. Access control & monitoring:
- Use least privilege — grant only what’s necessary.
- Rotate credentials and use managed identities or Azure Key Vault for secrets.
- Audit access with built-in logging (e.g., SQL Server Audit, Azure Defender).
What .NET engineers should know:
- 👼 Junior: Encrypt the database and use secure connections (TLS). Never store passwords or secrets in plain text.
- 🎓 Middle: Combine TDE for full-database protection with column-level encryption for critical fields. Use
Encrypt=Truein all DB connections. - 👑 Senior: Apply defense-in-depth: encryption, access control, key management, and network isolation. Integrate with Key Vault, KMS, or HSM for key lifecycle management and automate compliance monitoring.
📚 Resources:
❓ How would you design a reporting database separate from the OLTP database?
I’d start by separating the operational and analytical workloads. The OLTP database should handle fast inserts and updates, while the reporting database focuses on heavy read and aggregation queries.
To do that, I’d build a data pipeline, typically an ETL or ELT process, that copies data from the OLTP system into a reporting or data warehouse environment. The ETL job can run on a schedule, such as hourly or nightly, depending on how frequently the reports need to be updated.
The reporting database would utilize a denormalized schema, such as a star or snowflake schema, to simplify and expedite queries. I’d also add indexes, materialized views, or pre-aggregated tables for standard reports.
For near-real-time dashboards, I might use Change Data Capture (CDC) or an event-driven pipeline to ensure updates flow continuously.
The primary goal is to offload reporting from the OLTP system, ensuring that user transactions remain fast and analytics queries don’t lock or slow down production data.
What .NET engineers should know:
- 👼 Junior: Be aware that you need to transfer data from the central database to a separate database for reports to prevent slowing users down.
- 🎓 Middle: Use ETL or CDC to sync data into a reporting database that’s optimized for reads and aggregations.
- 👑 Senior: Design the warehouse with a star schema, partitioning, and caching. Keep compute isolated and automate refreshes with incremental loads or streaming ingestion.
❓ What is "Sharding" and what are the biggest challenges when implementing it?
Sharding is a technique for horizontally scaling a database by distributing data across multiple servers (shards). Each shard holds only a portion of the total data, for example, users A–M on one server, N–Z on another. The goal is to handle more data and traffic than a single database can, while maintaining fast query performance and balanced writes.
How it works:
- You pick a shard key (like
UserId,Region, orTenantId). - The system uses that key to determine where a record is stored.
- Each shard operates independently with its own storage, indexes, and performance profile.
Most significant challenges when implementing sharding:
- Choosing the right shard key
- Cross-shard queries and joins
- Queries that need data from multiple shards are slow and complex.
- Joins, aggregates, and transactions across shards often require custom logic or data duplication.
- Rebalancing shards
- If one shard grows faster than the others, you may need to move data (resharding).
- This is difficult without downtime or consistency issues.
- Transactions and consistency
- ACID transactions are typically limited to a single shard.
- Cross-shard transactions require coordination (like two-phase commit).
- Operational complexity
- Backups, migrations, and monitoring become multi-node operations.
- You need tooling to detect hotspots and manage shard health.
What .NET engineers should know:
- 👼 Junior: Should know sharding means splitting data across multiple servers for scalability.
- 🎓 Middle: Should understand how shard keys affect performance and what problems arise with cross-shard operations.
- 👑 Senior: Should design resilient shard-aware systems abstracting routing logic, monitoring data distribution, and planning for rebalancing, multi-region scaling, and observability.
📚 Resources:
❓ How would you configure high availability and disaster recovery for a critical SQL Server database?
High availability (HA) and disaster recovery (DR) both aim to keep your database online, but they solve different problems:
- High availability means minimal downtime during local failures (such as a server crash).
- Disaster recovery = the ability to recover from larger incidents (such as data center loss).
SQL Server gives you a few main ways to achieve this, depending on your needs and budget:
1. Always On Availability Groups (AG)
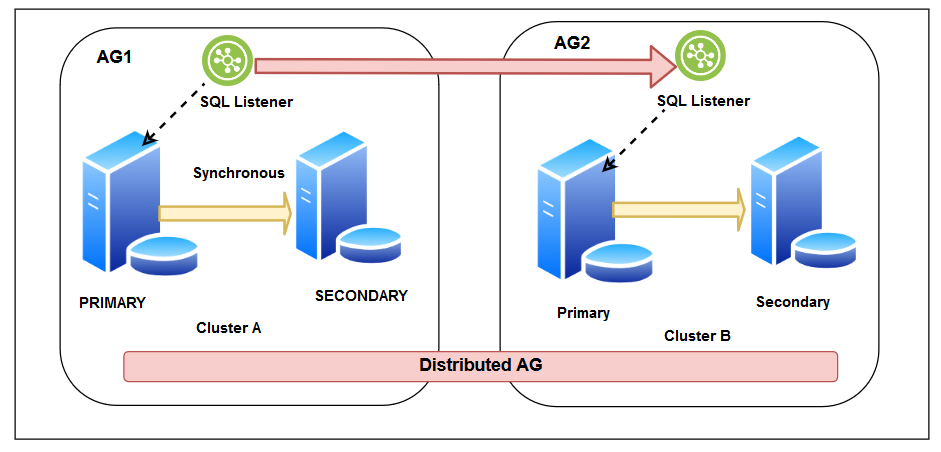
Best choice for mission-critical systems. It keeps multiple replicas of the same database on separate servers. One is the primary, and the others are secondaries.
If the primary fails, another replica automatically takes over.
- Sync mode = zero data loss, used for HA (within the same region).
- Async mode = some delay, used for DR (across regions).
-- Simplified setup (conceptually)
CREATE AVAILABILITY GROUP SalesAG
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE SalesDB
REPLICA ON 'SQLNode1' WITH (ROLE = PRIMARY),
'SQLNode2' WITH (ROLE = SECONDARY);2. Failover Cluster Instance (FCI)
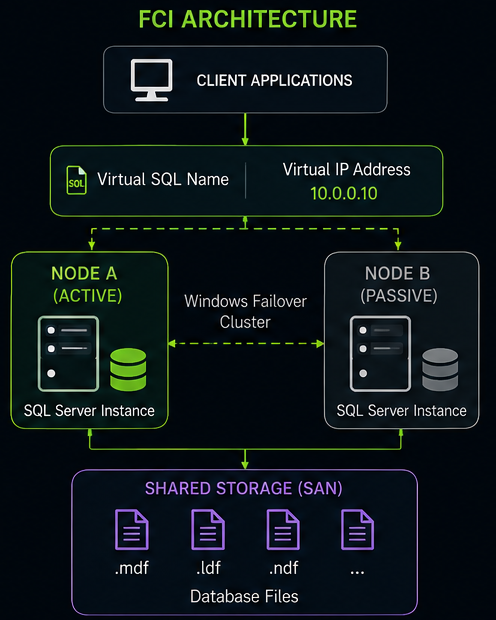
The entire SQL Server instance (not just a database) runs on a Windows Failover Cluster. Shared storage is used — only one node is active at a time.
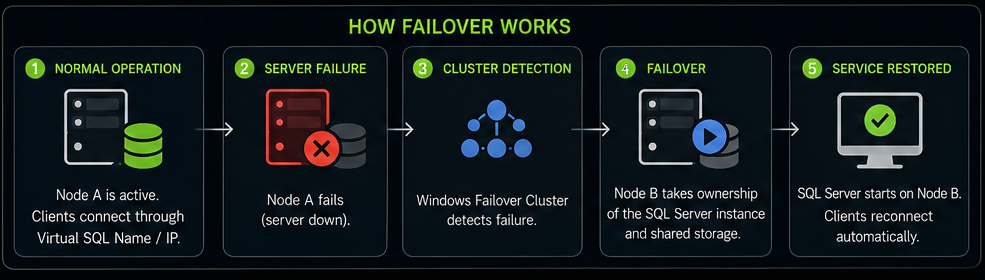
Suitable for hardware or OS-level failures, but not storage corruption.
3. Log Shipping
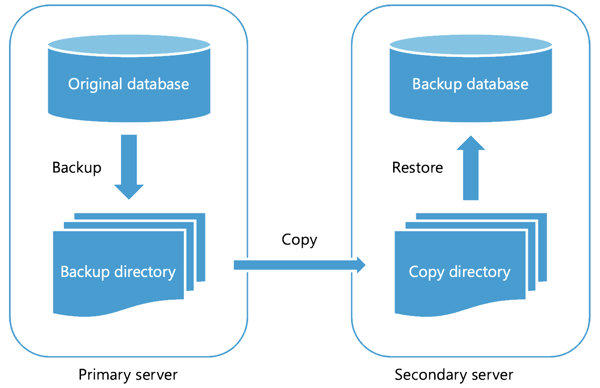
Transaction log backups are automatically shipped and restored to a secondary server.
There’s no automatic failover, but it’s simple and suitable for DR setups.
4. Backups + Geo-Replication
For smaller systems, you can combine frequent backups with geo-replicated storage (e.g., Azure Blob Storage or S3).
It’s slower to recover but cost-effective.
What .NET engineers should know:
- 👼 Junior: Understand that HA/DR keeps the database available during failures. Know basic terms, such as primary/secondary replicas and failover.
- 🎓 Middle: Be familiar with options like Availability Groups, Failover Clusters, and Log Shipping, and when to use each. Know how connection strings use listeners for automatic failover.
- 👑 Senior: Design a complete HA/DR strategy based on business RPO/RTO goals, handle cross-region replication, test failover regularly, and plan for split-brain and backup consistency. Should also integrate monitoring and alerting (SQL Agent, Prometheus, or Azure Monitor).
📚 Resources:
- Get started with log shipping on Linux
- About log shipping
- Always On failover cluster instances
- What is an Always On availability group?
❓ How can you reduce locking contention in a high-write environment?
Locking contention happens when transactions compete for the same rows or pages. The fix is either to reduce the time locks are held or to reduce the overlap between competing transactions.
1. Use READ COMMITTED SNAPSHOT ISOLATION (RCSI) Readers no longer block writers. Writers no longer block readers. SQL Server uses row versions in tempdb instead of shared locks.
ALTER DATABASE YourDb SET READ_COMMITTED_SNAPSHOT ONSingle setting change. Biggest impact for most applications. Enable this first.
2. Keep transactions short Long transactions hold locks longer. Move business logic, external calls, and validation outside the transaction boundary.
// Wrong: external call inside transaction
using var tx = await db.Database.BeginTransactionAsync();
var order = await db.Orders.FindAsync(id);
await emailService.SendAsync(order); // holds lock during email send
await tx.CommitAsync();
// Right: external call outside transaction
var order = await db.Orders.FindAsync(id);
using var tx = await db.Database.BeginTransactionAsync();
order.Status = "Confirmed";
await db.SaveChangesAsync();
await tx.CommitAsync();
await emailService.SendAsync(order); // lock already released3. Index for your write patterns. Missing indexes cause table scans. Table scans lock far more rows than index seeks. Every unindexed WHERE clause in a high-write table is a contention risk.
4. Partition hot tables. Spread writes across multiple filegroups or use table partitioning so concurrent writes hit different partitions.
5. Optimistic concurrency with rowversion. Skip pessimistic locks entirely. Detect conflicts at commit time rather than preventing them up front.
public class Order
{
public int Id { get; set; }
public string Status { get; set; } = string.Empty;
[Timestamp]
public byte[] RowVersion { get; set; } = [];
}-- EF Core generates this under the hood
UPDATE Orders
SET Status = 'Shipped'
WHERE Id = 1 AND RowVersion = @originalVersion
-- If 0 rows affected, someone else updated first6. Batch writes with a queue. Stop hammering the database with individual row inserts. Collect writes in a queue and flush in batches.
// Batch insert with EF Core ExecuteUpdate or raw SQL
await db.BulkInsertAsync(pendingEvents);🎯 Scenario-Based & Practical

❓ Can you define a transaction and give an example of a business operation that absolutely needs to be wrapped in one?
A transaction is a unit of work in a database that involves multiple operations and succeeds or fails as a whole.
If one step fails, everything rolls back, so your data isn’t left in a broken or partial state.
Classic example: bank transfer.
Step 1: Subtract money from Account A
Step 2: Add money to Account B
If the second step fails, the first one must roll back. Otherwise, money “disappears.”
Example in C#:
using var transaction = await db.Database.BeginTransactionAsync();
try
{
var from = await db.Accounts.FindAsync(1);
var to = await db.Accounts.FindAsync(2);
from.Balance -= 100;
to.Balance += 100;
await db.SaveChangesAsync();
await transaction.CommitAsync();
}
catch
{
await transaction.RollbackAsync();
throw;
}What .NET engineers should know:
- 👼 Junior: Determine whether a transaction involves multiple database actions or none at all.
- 🎓 Middle: Understand how to implement transactions in EF Core or SQL, and when they’re needed (payments, inventory updates).
- 👑 Senior: Tune isolation levels, handle deadlocks, and design distributed transactions or compensating actions in microservices.
📚 Resources:
❓ A page in your application is loading slowly. How would you systematically determine if the problem is a database query?
If you suspect the database, you can narrow it down step by step:
- Measure total request time — add timing logs at the start and end of your controller or service.
- Log query durations — most ORMs, such as EF Core, can log SQL commands and execution times.
- Find slow queries — in SQL Server, check the Query Store or Extended Events; in PostgreSQL, use
pg_stat_statementsorEXPLAIN (ANALYZE). - Run the query directly — copy the SQL from the logs and execute it in SSMS or psql to see if it’s prolonged or if something else is causing a delay.
- Check the execution plan — look for missing indexes, table scans, or heavy joins.
- Test with parameters — sometimes the plan works for one input and breaks for another (parameter sniffing).
What .NET engineers should know:
- 👼 Junior: Learn to identify if the slowdown is from the database by logging execution times. Be able to run simple queries manually and compare performance.
- 🎓 Middle: Use tools like Query Store or
EXPLAIN (ANALYZE)to analyze execution plans, find missing indexes, or optimize queries. - 👑 Senior: Understand deeper causes of parameter sniffing, locking, and poor statistics, and know how to correlate app metrics with DB metrics. Should also be able to tune connection pools and caching strategies.
📚 Resources:
❓ How does database connection pooling work in .NET, and what are some common mistakes that can break it?
Connection pooling in .NET is a mechanism that allows for the reuse of existing database connections, rather than opening and closing new ones each time your code executes a query. Opening a database connection is expensive; pooling makes it fast and efficient by keeping a small pool of ready-to-use connections in memory.
When you call SqlConnection.Open(), .NET doesn’t always create a brand-new connection. It checks if there’s an available one in the pool with the exact connection string:
- If yes, it reuses it.
- If not, it creates a new one (up to the pool limit).
When you call Close() or Dispose() connection isn’t really closed; it’s returned to the pool for reuse.
What .NET engineers should know:
- 👼 Junior: Know that connection pooling reuses DB connections to improve performance. Always close or properly dispose of connections.
- 🎓 Middle: Understand that each unique connection string has its own pool. Know how to adjust pool sizes and identify issues like pool exhaustion.
- 👑 Senior: Be able to debug connection leaks (e.g., via
Performance Countersordotnet-trace), tune pools for async workloads, and understand provider-specific pooling (SQL Server, Npgsql, MySQL). Should design data access code that scales safely under load.
📚 Resources: SQL Server connection pooling (ADO.NET)
❓ If you had to improve the performance of a large DELETE or UPDATE operation, what strategies would you consider?
Big DELETE or UPDATE queries can lock tables and fill logs. The trick is to do it in smaller batches and reduce overhead.
Main approaches to handling it:
- Batch processing – run deletes in chunks:
DELETE TOP (10000) FROM Orders WHERE Status = 'Archived'; - Partitioning – drop or truncate old partitions rather than delete rows.
- Disable extra work – temporarily drop unused indexes or triggers.
- Use the proper recovery/logging mode – e.g.,
BULK_LOGGEDin SQL Server. - Run off-peak and monitor lock and log sizes.
What .NET engineers should know:
- 👼 Junior: Avoid deleting millions of rows at once — use batching.
- 🎓 Middle: Tune indexes and use partitioning for large tables.
- 👑 Senior: Design cleanup jobs and archiving strategies that don’t block production systems.
📚 Resources: How to use batching to improve application performance
❓ How would you handle a situation where a necessary query is just inherently slow due to the volume of data it needs to process?
Sometimes a query is slow, not because it’s poorly written — it’s just doing a lot of work. When that’s the case, the goal isn’t to make it instant, but to make it manageable — by controlling when, how often, and how much data it touches.
Here’s how you can approach it step by step 👇
1. Don’t make it faster — make it smarter
Ask:
Do we really need all the data right now?
- Fetch summaries instead of raw rows (e.g., aggregates or pre-computed stats).
- Use incremental updates, process only what has changed since the last run.
- Cache results if they don’t change often.
2. Run it asynchronously or in the background
Move the heavy query out of the request path.
For example:
- Use a background job (Hangfire, Quartz.NET, Azure Function, etc.).
- Trigger it periodically and store results in a reporting table.
- Let the frontend fetch preprocessed data instead of running the query live.
3. Partition or segment data
Split large tables by date, region, or tenant, so queries only scan relevant partitions.
SELECT * FROM Orders
WHERE OrderDate >= '2024-01-01' AND OrderDate < '2024-02-01';Now the DB only touches one month’s data instead of years.
4. Use materialized views or pre-aggregated tables
Precompute common aggregations and refresh them periodically.
5. Tune hardware and execution environment
Sometimes you’ve already optimized everything logically, then it’s about:
- More memory for caching.
- Faster storage (SSD).
- Parallel query settings or read replicas for scaling reads.
What .NET engineers should know:
- 👼 Junior: Understand that some queries are heavy due to the large data size. Learn to cache or limit data when possible.
- 🎓 Middle: Move heavy queries to background jobs or precompute results using materialized views or summaries.
- 👑 Senior: Design systems around data volume partitioning, async pipelines, read replicas, and caching strategies that keep heavy operations off the critical path.
📚 Resources:
❓ What's the purpose of the STRING_AGG or FOR XML PATH techniques in SQL? Can you think of a use case?
Both STRING_AGG (modern approach) and FOR XML PATH (older workaround) are used to combine multiple row values into a single string a process often called string aggregation or grouped concatenation.
They’re commonly used when you need to return a list of related values as a single field instead of multiple rows.
Example use case
Suppose you want a list of products purchased by each customer.
With STRING_AGG (SQL Server 2017+, PostgreSQL 9.0+, MySQL 8+):
SELECT c.CustomerName,
STRING_AGG(p.ProductName, ', ') AS Products
FROM Orders o
JOIN Customers c ON o.CustomerId = c.Id
JOIN Products p ON o.ProductId = p.Id
GROUP BY c.CustomerName;Output:
| CustomerName | Products |
|---|---|
| Alice | Laptop, Mouse, Keyboard |
| Bob | Monitor, Mouse |
Before STRING_AGG existed, SQL Server developers used FOR XML PATH to achieve the same result:
SELECT c.CustomerName,
STUFF((
SELECT ',' + p.ProductName
FROM Orders o2
JOIN Products p ON o2.ProductId = p.Id
WHERE o2.CustomerId = c.Id
FOR XML PATH('')
), 1, 1, '') AS Products
FROM Customers c;This works by building XML, then flattening it into a string a creative workaround that was popular before aggregation functions became standard.
What .NET engineers should know:
- 👼 Junior: Understand that
STRING_AGGcombines multiple row values into one string. - 🎓 Middle: Know how to use it in grouped queries and replace older
FOR XML PATHlogic in legacy systems. - 👑 Senior: Optimize its use in reporting or API queries and understand its behavior with ordering (
STRING_AGG(... ORDER BY ...)) and null handling.
📚 Resources:
⚙️ Entity Framework Core

❓ What are the trade-offs of using AsNoTracking() in EF Core?
AsNoTracking() tells Entity Framework Core not to track changes for the returned entities. Usually, EF keeps a copy of every loaded entity in its change tracker — so if you modify it later, EF knows how to generate an UPDATE. With AsNoTracking(), EF skips that overhead completely.
// Regular query: tracked entities
var users = context.Users.ToList();
// No tracking: faster, lightweight
var users = context.Users.AsNoTracking().ToList();AsNoTrackingWithIdentityResolution
Introduced in EF Core 5.0, this version offers a middle ground.
It still disables change tracking for performance, but ensures each unique entity from the result is returned only once — meaning if the same record appears in multiple navigation paths, you get a shared instance instead of duplicates.
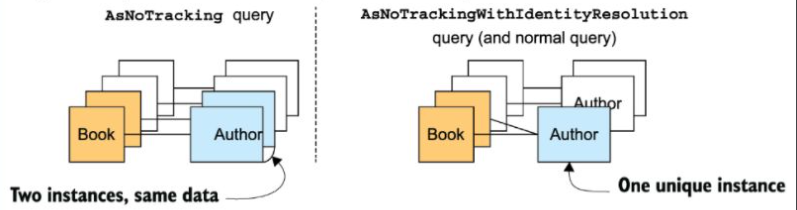
Example:
var users = context.Users
.Include(u => u.Orders)
.AsNoTrackingWithIdentityResolution()
.ToList();This helps when working with complex queries that involve joins or relationships, avoiding duplicate entity instances while maintaining the query's read-only status.
What .NET engineers should know:
- 👼 Junior: Know that
AsNoTracking()speeds up read-only queries by skipping change tracking. - 🎓 Middle: Understand when to use
AsNoTrackingWithIdentityResolution()— for read-only queries that include navigation properties. - 👑 Senior: Balance both options — use regular tracking for write operations,
AsNoTracking()for simple reads, andAsNoTrackingWithIdentityResolution()for complex projections where identity consistency matters.
📚 Resources: Tracking vs. No-Tracking Queries
❓ You need to insert 100,000 records. What's wrong with using a simple loop with SaveChanges(), and what would you do instead?
Calling SaveChanges() inside a loop is one of the most common performance mistakes when inserting large datasets. Each call sends a separate transaction and round-trip to the database, meaning 100,000 inserts = 100,000 transactions. That’s extremely slow and puts unnecessary load on both the application and the database.
foreach (var item in records)
{
context.Items.Add(item);
context.SaveChanges(); // ❌ 100,000 separate database calls
}This approach can take minutes instead of seconds.
Better approaches to insert multiple records:
Batch inserts with fewer SaveChanges calls
Add multiple records, then save once per batch:
await foreach (var chunk in records.Chunk(1000).ToAsyncEnumerable()) // ✅ Use async streaming
{
context.AddRange(chunk);
await context.SaveChangesAsync(); // ✅ Async, 1000 records per transaction
}This dramatically reduces round-trip and transaction overhead.
Tip: Disable change tracking and use a using block for scoped DbContext:
using var context = new AppDbContext(); // ✅ Scoped lifetime
context.ChangeTracker.AutoDetectChangesEnabled = false;
await foreach (var chunk in records.Chunk(1000).ToAsyncEnumerable())
{
context.AddRange(chunk);
await context.SaveChangesAsync();
}Use Bulk Operations
Libraries like EFCore.BulkExtensions perform bulk inserts directly via SQL:
context.BulkInsert(records);These bypass EF’s change tracking, making large inserts 10–100x faster.
Use raw SQL or database-specific tools.
- SQL Server:
SqlBulkCopy - PostgreSQL:
COPYcommand - MySQL: multi-row
INSERTstatements
These are ideal for millions of records where EF overhead is too high.
What .NET engineers should know:
- 👼 Junior: Understand that calling
SaveChanges()per record is inefficient. Use batching to reduce database calls. - 🎓 Middle: Apply chunked inserts or use bulk libraries to optimize mass inserts.
- 👑 Senior: Choose the best approach per scenario: EF batching for moderate data, raw bulk APIs for massive imports, and tune transaction size to balance performance and memory.
📚 Resources:
❓ How can you use projections in EF Core to optimize a query that only needs a few fields?
By default, EF Core maps entire entities, all columns — even if you only use a few of them later. That means extra data is fetched, tracked, and stored in memory unnecessarily. Using projections with .Select() lets you fetch only the columns you actually need, which reduces database I/O, memory usage, and tracking overhead.
Example
Let’s say your entity has many columns, but you only need a user’s name and email for a list view.
// Without projection — loads full User entity
var users = await context.Users.ToListAsync();
// With projection — fetch only required fields
var users = await context.Users
.Select(u => new { u.Name, u.Email })
.ToListAsync();EF Core translates this directly into SQL, selecting only those columns:
SELECT [u].[Name], [u].[Email]
FROM [Users] AS [u];The result is smaller, transfers faster, and uses less memory on the .NET side.
You can also project into DTOs or view models:
var customers = await context.Customers
.Select(c => new CustomerDto
{
Id = c.Id,
Name = c.Name,
TotalOrders = c.Orders.Count
})
.ToListAsync();What .NET engineers should know:
- 👼 Junior: Use
.Select()to fetch only the fields needed, not whole entities. - 🎓 Middle: Project into DTOs or anonymous types to reduce memory and improve performance.
- 👑 Senior: Combine projections with pagination and no-tracking for maximum efficiency in API and reporting layers.
📚 Resources: Efficient Querying
❓ What exactly is the "N+1 query problem," and how have you solved it in EF Core?
The N+1 query problem happens when your code runs one main query to fetch a list of items (the “1”), and then executes a new query for each item to load its related data (the “N”).
So instead of a single efficient join or batch, you end up issuing dozens or hundreds of minor queries.
It usually occurs when lazy loading is used or when navigation properties are unoptimized.
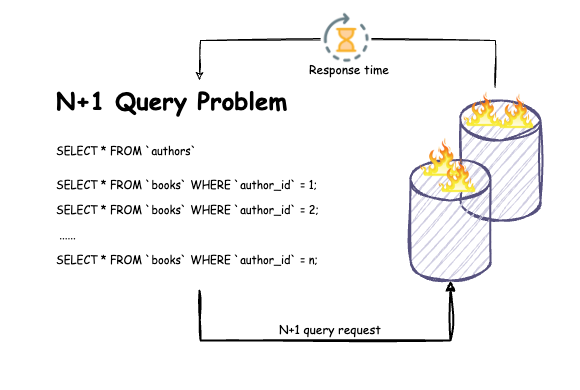
Example of the problem
// ❌ Triggers N+1 queries
var orders = context.Orders.ToList();
foreach (var order in orders)
{
Console.WriteLine(order.Customer.Name); // Each access triggers a new query
}This looks simple, but EF runs 1 query for all orders, then 1 query per order to fetch its customer, resulting in poor performance.
How to fix it
- Option 1: Use eager loading (
Include)
// ✅ Single query
var orders = context.Orders
.Include(o => o.Customer)
.ToList();EF Core generates a single SQL query with a join to include customers up front.
- Option 2: Use projection instead of navigation
var orders = context.Orders
.Select(o => new
{
o.Id,
CustomerName = o.Customer.Name,
o.Total
})
.ToList();Projections fetch exactly what you need in a single, efficient query.
- Option 3. Disable lazy loading.
Lazy loading is often the root cause. If you don’t explicitly need it, disable it:
context.ChangeTracker.LazyLoadingEnabled = false;- Option 4. Consider split queries (when using large includes)
When eager loading too much data in one query leads to cartesian explosions, EF Core 5+ can split them safely:
var orders = context.Orders
.Include(o => o.Customer)
.AsSplitQuery()
.ToList();What .NET engineers should know:
- 👼 Junior: Understand that N+1 means too many queries caused by loading related data separately.
- 🎓 Middle: Use
.Include()or projections to efficiently load related data. Disable lazy loading if not needed. - 👑 Senior: Combine eager loading, projections, and split queries strategically based on data shape and query size. Optimize using profiling tools such as EF Core Power Tools or SQL Profiler.
📚 Resources:
❓ How would you explain the Unit of Work and Repository patterns to someone just starting with EF Core? Does the DbContext itself implement these?
The Repository and Unit of Work patterns are classic ways to organize data access in an application.
But if you’re using EF Core, you’re already using both, even if you don’t realize it.
Repository pattern
The Repository pattern acts as a collection-like interface for accessing data.
Instead of writing SQL, you interact with objects:
// Repository-style access
var user = await context.Users.FirstOrDefaultAsync(u => u.Email == email);Unit of Work pattern
The Unit of Work groups a set of changes into a single transaction. In EF Core, DbContext tracks changes to entities and saves them all at once with SaveChanges() — committing as one atomic operation.
var user = new User { Name = "Alice" };
context.Users.Add(user);
user.Name = "Alice Cooper";
await context.SaveChangesAsync(); // ✅ single transaction (Unit of Work)Do you still need to implement them manually?
In most modern applications, it's not needed; EF Core already provides these abstractions:
- Each
DbSet<TEntity>acts as a Repository. - The
DbContextacts as a Unit of Work.
Adding extra layers often introduces complexity without providing a significant benefit. However, some teams still use custom repository interfaces to:
- Decouple EF Core from business logic (for testing or mocking).
- Enforce consistent query rules across the app.
But for many projects, DbContext is enough.
What .NET engineers should know:
- 👼 Junior: Understand that
DbContexttracks entities (Repository) and commits changes together (Unit of Work). - 🎓 Middle: Know when to use EF Core directly vs adding abstraction for testability or specific business rules.
- 👑 Senior: Design clean data layers; avoid redundant abstractions, use generic repositories only when they add value, and keep transaction scope inside the Unit of Work (
DbContext).
📚 Resources:
❓ How do you manage the lifetime of your DbContext in a modern ASP.NET Core application? Why shouldn't it be a singleton?
In ASP.NET Core, the DbContext is designed to be short-lived and scoped to a single request. That means a new instance is created for each incoming HTTP request and disposed automatically when the request ends.
You register it like this:
services.AddDbContextPool<AppDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("Default")));By default, this sets it up with a Scoped lifetime.
Even though a new DbContext is created per request; you’re not opening a brand-new database connection every time.
Why shouldn’t it be a singleton?
- A singleton DbContext lives for the entire app lifetime — which leads to multiple serious issues:
- Thread safety – DbContext isn’t thread-safe. Multiple requests using the same instance can corrupt its internal state.
- Memory leaks – It keeps tracking every entity it’s ever loaded. Over time, this can consume a massive amount of memory.
- Stale data – Long-lived contexts don’t reflect the current database state unless you explicitly reload entities.
- Transaction issues – The context might hold open transactions or connections longer than intended.
Essentially, using a single shared DbContext for all requests turns your app into a ticking time bomb of concurrency and data-consistency issues.
Recommended lifetimes:
| Lifetime | Description | When to use |
|---|---|---|
| Scoped | One per web request (default) | ✅ Standard for web apps and APIs |
| Transient | New instance every time it’s requested | For background jobs or short-lived operations |
| Singleton | One instance for the app lifetime | ❌ Never use for DbContext |
What .NET engineers should know:
- 👼 Junior: Know that
DbContextshould be a short-lived one per request. - 🎓 Middle: Understand why scoped lifetime prevents concurrency and memory issues.
- 👑 Senior: Manage custom scopes for background jobs or async work; ensure transactional consistency by keeping
DbContextlifetimes aligned with business operations.
📚 Resources:
❓ Let's say you have a complex, pre-tuned SQL query. How do you execute it and get the results back into your .NET code using EF Core?
Sometimes you already have a hand-optimized SQL query — maybe from a DBA or profiler, and you want to reuse it in your .NET app.
EF Core lets you run raw SQL directly and still safely map the results to your entities or custom DTOs.
Below are the options for how we can execute those queries:
- Using
FromSqlRaw()for entity results
var users = await context.Users
.FromSqlInterpolated($"SELECT * FROM Users WHERE City = {city}")
.ToListAsync();- Using
Database.SqlQuery<T>()
If your query doesn’t match an entity (e.g., returns aggregates or joins), map it to a custom type
public record UserStats(string City, int Count);
var stats = await context.Database
.SqlQuery<UserStats>(
"SELECT City, COUNT(*) AS Count FROM Users GROUP BY City")
.ToListAsync();- Using
Database.ExecuteSqlRaw()for commands
If the SQL doesn’t return rows (e.g., bulk updates or deletes):
await context.Database.ExecuteSqlRawAsync(
"UPDATE Orders SET Status = 'Archived' WHERE OrderDate < {0}", cutoffDate);- Fallback: ADO.NET for complete control
For advanced cases (multiple result sets, temp tables, etc.), you can still drop to raw ADO.NET via EF’s connection:
using var cmd = context.Database.GetDbConnection().CreateCommand();
cmd.CommandText = "EXEC GetUserStats";
context.Database.OpenConnection();
using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
// manual mapping
}What .NET engineers should know:
- 👼 Junior: Know you can run raw SQL via
FromSqlRaw()andExecuteSqlRaw(). - 🎓 Middle: Use
SqlQuery<T>()or DTO projections when results don’t match an entity. Handle parameters safely with interpolation. - 👑 Senior: Mix EF queries with raw SQL, strategically prefer EF for maintainability, but drop to SQL for performance-critical paths. Understand connection management and transaction context when running raw commands.
📚 Resources: SQL Queries
❓ How does EF Core handle concurrency conflicts? Can you describe a scenario where you’ve had to implement this?
EF Core handles concurrency conflicts using optimistic concurrency control. The idea is simple: multiple users can read and modify the same data, but when saving, EF Core checks if the data has changed since it was read. If yes, it throws a DbUpdateConcurrencyException.
To make it work, you add a concurrency token (like a RowVersion column) to your entity. EF Core includes this value in the WHERE clause during updates, ensuring the record is updated only if the token hasn’t changed.
Example:
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public decimal Price { get; set; }
[Timestamp]
public byte[] RowVersion { get; set; }
}
// Handling concurrency
try
{
context.SaveChanges();
}
catch (DbUpdateConcurrencyException)
{
Console.WriteLine("Data was modified by another user. Reload and retry.");
}In practice, this happens when, say, two admins edit the same product’s price. The second SaveChanges() will fail, and you can choose whether to overwrite or reload the entity.
What .NET engineers should know:
- 👼 Junior: Should know EF Core can detect conflicting updates and that this exception means the record was changed by someone else.
- 🎓 Middle: Should understand how to use
[Timestamp]orIsConcurrencyToken()and how to handle conflicts properly — retry, reload, or merge data. - 👑 Senior: Should design system-wide concurrency strategies, combining EF Core mechanisms with DB-level or custom logic to ensure consistency under heavy load.
📚 Resources: Handling Concurrency Conflicts
❓ How do you seed reference data (like a list of countries or product categories) using EF Core migrations?
In EF Core, you can seed reference data using the HasData() method in your OnModelCreating() configuration. When you add a migration, EF Core generates INSERT statements for that data. This approach is helpful for static reference data — like countries, product types, or predefined roles — that rarely changes.
Example:
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Country>().HasData(
new Country { Id = 1, Name = "Poland" },
new Country { Id = 2, Name = "Germany" },
new Country { Id = 3, Name = "France" }
);
}Then run:
dotnet ef migrations add SeedCountries
dotnet ef database updateEF Core will insert the seed data during migration. If you change the data later, EF will generate UPDATE or DELETE statements automatically.
What .NET engineers should know:
- 👼 Junior: Should know that
HasData()can seed static data and that it runs through migrations, not runtime initialization. - 🎓 Middle: Should understand that seeded data must include primary keys and how EF Core compares data changes to update or delete existing records.
- 👑 Senior: Should know when to avoid
HasData()(e.g., large datasets, dynamic configs) and instead use custom scripts, JSON imports, or background seeders for more flexibility.
📚 Resources: Data Seeding
❓ What are owned entities in EF Core, and when would you use them?
Owned entities in EF Core let you group related fields into a value object that doesn’t have its own identity or table. They’re helpful when you want to logically separate parts of an entity — like an address or a money type — but still keep them stored in the same table as the owner. It’s a clean way to model value objects in line with Domain-Driven Design principles.
Example:
public class User
{
public int Id { get; set; }
public string Name { get; set; }
public Address Address { get; set; }
}
[Owned]
public class Address
{
public string City { get; set; }
public string Street { get; set; }
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<User>().OwnsOne(u => u.Address);
}This generates one table Users with columns like City and Street embedded directly in it.
When to use:
Use owned entities when you want to model a complex value object that always belongs to a single parent entity and doesn’t need its own lifecycle, primary key, or repository.
What .NET engineers should know:
- 👼 Junior: Should understand that the owned entities group-related fields are stored in the same table as their parent.
- 🎓 Middle: Should understand how to configure them with
[Owned]orOwnsOne(), and how they differ from regular relationships (no separate key or table). - 👑 Senior: Should use owned entities to implement value objects and ensure clean domain boundaries, possibly combining them with immutability or record types for better consistency.
📚 Resources: Owned Entity Types
❓ How do you configure a many-to-many relationship in EF Core?
In EF Core, many-to-many relationships are easy to set up starting from EF Core 5. You can define them directly without creating a separate join entity class — EF Core automatically builds a join table under the hood.
If you need additional columns in the join table (such as timestamps or metadata), you can explicitly define the join entity.
Example:
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
public ICollection<Course> Courses { get; set; }
}
public class Course
{
public int Id { get; set; }
public string Title { get; set; }
public ICollection<Student> Students { get; set; }
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Student>()
.HasMany(s => s.Courses)
.WithMany(c => c.Students);
}EF Core will create a join table named CourseStudent automatically with StudentId and CourseId as composite keys.
What .NET engineers should know:
- 👼 Junior: Should know that EF Core supports many-to-many relationships out of the box and automatically creates a join table.
- 🎓 Middle: Should understand how to customize the join table and define explicit join entities when additional fields are needed.
- 👑 Senior: Should design data models with clear ownership rules, consider performance implications (like lazy loading or query joins), and optimize navigation properties for large datasets.
📚 Resources: Many-to-many relationships
❓ What are global query filters, and what's a practical use case for them?
Global query filters in EF Core let you automatically apply a WHERE condition to all queries for a specific entity type. They’re great for scenarios like soft deletes, multi-tenancy, or filtering archived data — so you don’t have to repeat the same condition in every query.
Example (soft delete):
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public bool IsDeleted { get; set; }
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Product>().HasQueryFilter(p => !p.IsDeleted);
}
Now every query like context.Products.ToList() automatically includes WHERE IsDeleted = 0. You can still disable the filter temporarily using IgnoreQueryFilters().
What .NET engineers should know:
- 👼 Junior: Should know global filters automatically apply to all queries and simplify logic like soft deletes.
- 🎓 Middle: Should understand how to use
HasQueryFilter()and disable filters withIgnoreQueryFilters()when needed. - 👑 Senior: Should design multi-tenant and soft-delete strategies using filters carefully — considering performance, caching, and how filters interact with includes or raw SQL.
📚 Resources: Global Query Filters
❓ Can you explain what a shadow property is in EF Core?
A shadow property in EF Core is a field that exists in the model but not in your entity class. It’s managed by EF Core internally — you can query, filter, and store values for it, even though it’s not part of your C# object.
This is handy when you need extra metadata (like CreatedAt, UpdatedBy, or TenantId) that doesn’t belong to the domain model itself but is still helpful in the database.
Example:
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Product>()
.Property<DateTime>("CreatedAt")
.HasDefaultValueSql("GETDATE()");
}Now EF Core will create a CreatedAt column in the Products table, even though Product doesn’t have that property in C#. You can access it like this:
var createdAt = context.Entry(product).Property("CreatedAt").CurrentValue;What .NET engineers should know:
- 👼 Junior: Should know shadow properties exist in the EF model but not in the entity class.
- 🎓 Middle: Should understand how to define and use them for audit fields, multi-tenancy, or soft deletes.
- 👑 Senior: Should design when to use shadow properties deliberately — balancing between clean domain models and operational metadata needs, possibly integrating them with interceptors or change tracking.
📚 Resources: Shadow and Indexer Properties
❓ How does EF Core decide whether to issue an INSERT or an UPDATE when you call SaveChanges()?
When you call SaveChanges() in Entity Framework Core, the framework looks at the state of each tracked entity in the DbContext to decide what SQL command to send. It’s all about change tracking — EF Core keeps track of each entity’s lifecycle from when you load or attach it until you save.
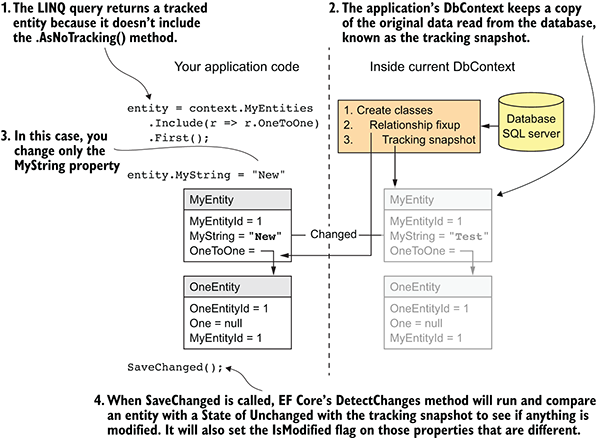
It compares current property values with original ones (snapshotted on load).Based on that diff, it decides which SQL operation to generate.
What .NET engineers should know:
- 👼 Junior: Should know
Add(),Update(), andRemove()change entity states, and EF Core decides what to save based on them. - 🎓 Middle: Should understand how the Change Tracker works and when to use
AsNoTracking()to skip tracking for read-only queries. - 👑 Senior: Should control state management explicitly — using
Attach(),Entry(entity).State, or detached entity updates to avoid unnecessary SQL operations in high-load systems.
📚 Resources:
📖 Future reading
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum