Data Versioning and Schema Evolution Patterns


NoSQL databases, such as MongoDB (document-oriented), Cassandra (wide-column), and DynamoDB (key-value), provide flexibility by not enforcing strict schemas, allowing for varied data structures without requiring upfront definitions. This is beneficial for rapid development and managing unstructured data. However, as applications expand, schema changes such as field renames or nested structures often become necessary, leading to potential data inconsistencies or difficult-to-debug issues. Beginners should approach NoSQL schemas as "implicit" and use patterns to manage these changes safely.
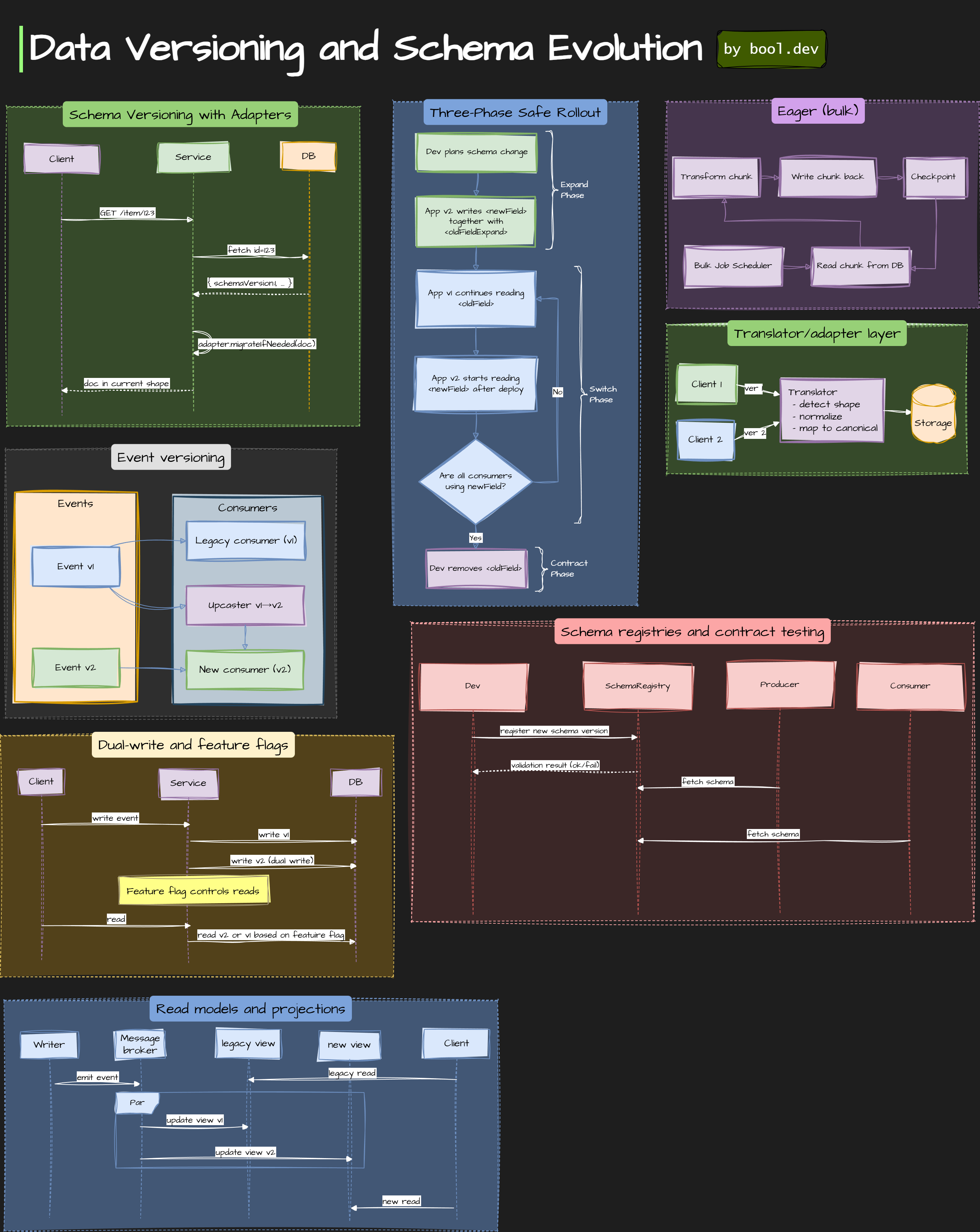
Schema Versioning with Adapters
Store an explicit version number inside each record. At runtime, run a small adapter that upgrades older shapes to the current in-memory model. Write paths can stamp the latest version.
- Writers set
schemaVersionwhen they write. - Readers fetch a doc. If
schemaVersionis older, calladapter.migrate(doc)to return the current shape. - Optionally do a best-effort write-back to persist the new shape.
Pros
- Clear per-record contract.
- Small, testable adapter functions.
- Works well with lazy migrations.
Cons
- Adds read-time CPU and code paths.
- If you write back, you need optimistic checks to avoid races.
- Migration logic can proliferate if multiple versions accumulate.
When to use
- When changes are incremental, and you can centralize transforms.
- Useful as a fallback when other strategies fail.
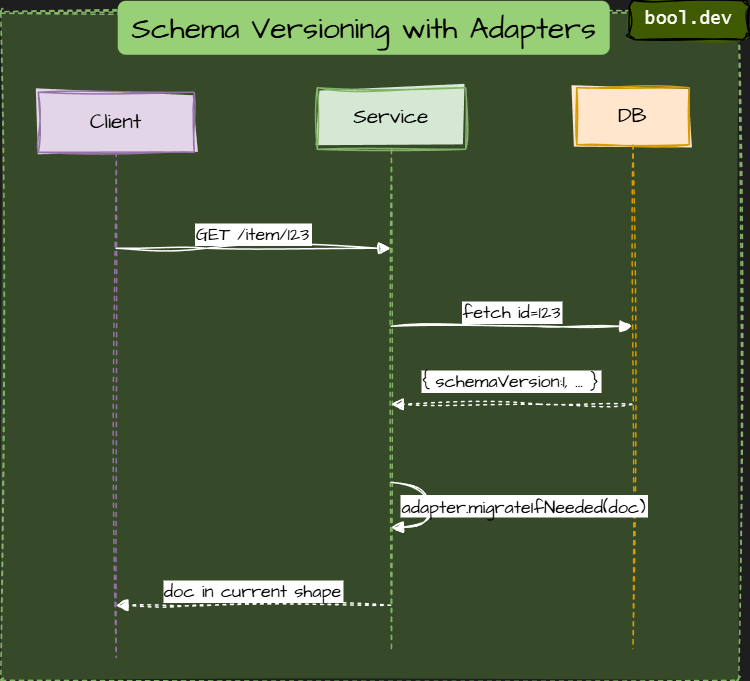
Expand > Switch > Contract (Three-Phase Safe Rollout)
Make non-breaking additions first, switch code to use them, then remove old fields. This is the safest default for most changes.
How it works
- Expand: producers write both old and new fields. Readers still use old fields.
- Switch: update readers to read the new fields. Keep old fields for safety.
- Contract: Once every reader has used the new shape, remove the old fields.
Pros
- Lowest risk for most changes.
- Easy rollback — keep
oldFielduntil you’re sure. - Works without heavy tooling.
Cons
- Temporary schema bloat.
- Risk of forgetting to clean up old fields.
- Requires coordination (or feature flags, or metrics) to know when to contract.
When to use
- Default choice for renames, splits, and simple reshapes.
- When many clients update at different speeds.
Lazy (on-read) migration
Only migrate a document when it has been read. First read does the work and writes the migrated shape back. Cheap for mostly cold data.
How it works (step-by-step)
- Reader fetches doc. If the version is outdated, update it to the latest version.
- Try to write back with a conditional update (only if version unchanged).
- If the write-back loses a race, re-fetch or accept the concurrent update.
Pros
- Very cost-effective for massive cold datasets.
- No big migration window. Work is amortized over regular traffic.
Cons
- First read latency spikes.
- Heterogeneous data shapes live in production for longer.
- Concurrency edge cases require careful handling and idempotent transforms.
When to use
- Massive collections where bulk jobs are expensive.
- Systems where occasional extra latency is acceptable.
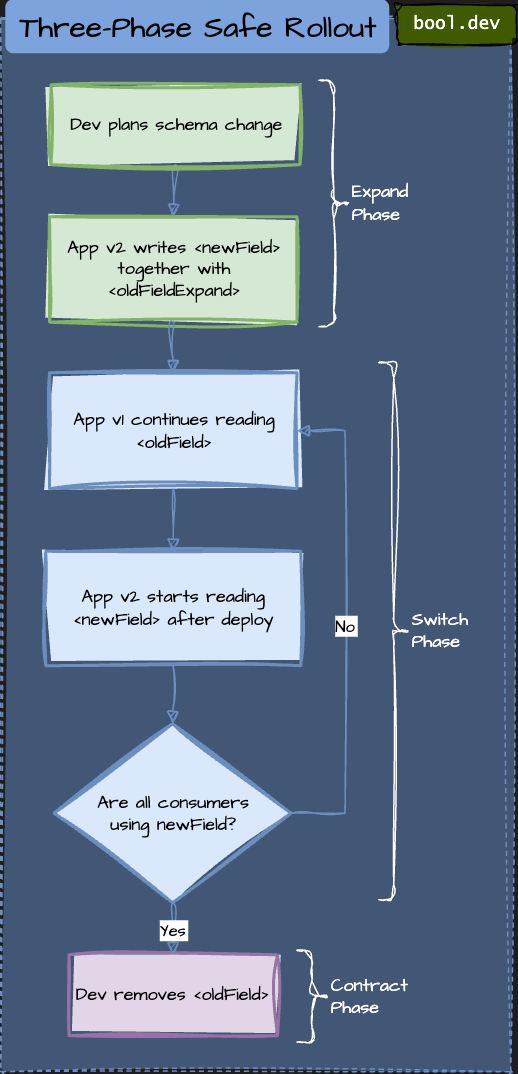
Eager (bulk) migration
Run a background job that converts every document to the new shape before you switch readers. Clean, uniform, but heavy.
How it works
- Launch a job that reads data in batches.
- For each batch, transform the data and write it back. Persist a checkpoint.
- Throttle and retry. Stop safely if the load or errors spike.
Pros
- After the job, every document is uniform.
- No read-time migration latency.
- Easier to reason about application logic.
Cons
- Costly and operationally heavy.
- Needs batching, checkpointing, throttling, and careful retries.
- Long-running jobs can become a source of incidents.
When to use
- When read, latency must be consistent.
- When you need to drop old fields quickly for correctness or cost reasons.
Dual-write and feature flags
Write both old and new formats at write time. Use feature flags to toggle which format readers use.
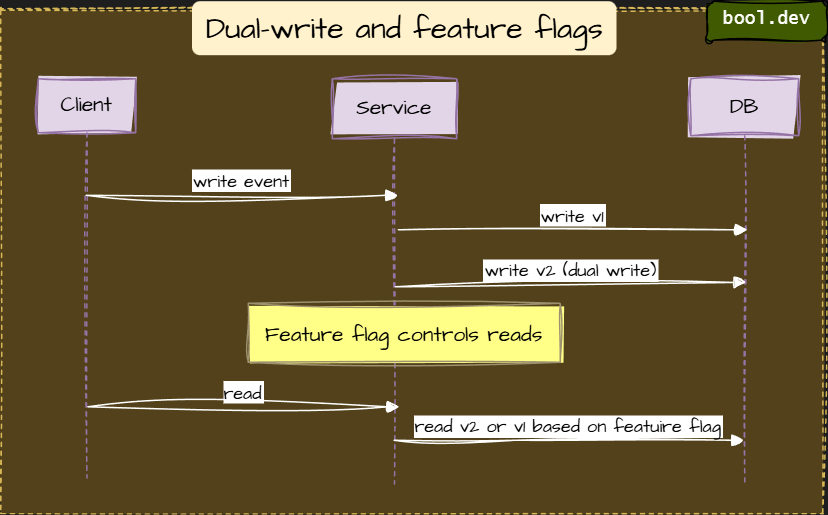
Pros
- Fast cutover for consumers.
- Very explicit control via flags.
- Low user-visible risk when rolled gradually.
Cons
- Doubles write complexity and failure surface.
- Reconciliation is required for partial failures.
- Higher storage and CPU costs.
When to use
- When you must support both old and new clients simultaneously, and rollback time must be minimal.
Schema registries and contract testing
Keep authoritative schemas in a registry (Avro, Protobuf, JSON Schema). Automatically validate compatibility and run contract tests in CI.
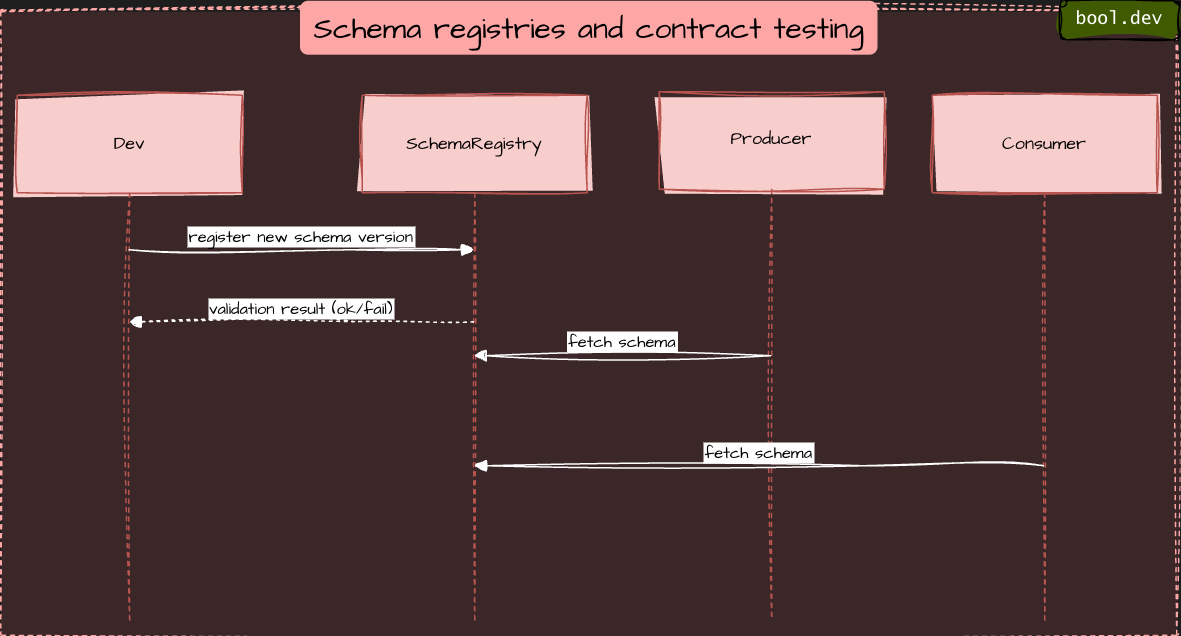
Producers and consumers fetch schemas from the registry.
CI validates changes against compatibility rules before they merge.
Pros
- Prevents accidental breaking changes.
- Excellent for event-driven, message-first architectures.
- Enables automated contract tests.
Cons
- Adds governance overhead and a new dependency.
- Not a silver bullet for ad-hoc document stores (but still useful).
When to use
- Kafka/event pipelines and microservices with shared message contracts.
Event versioning (upcast, side-by-side, downcast)
Events are immutable. Either upcast older events at read time, publish new event types side-by-side, or provide downcasts for legacy consumers.
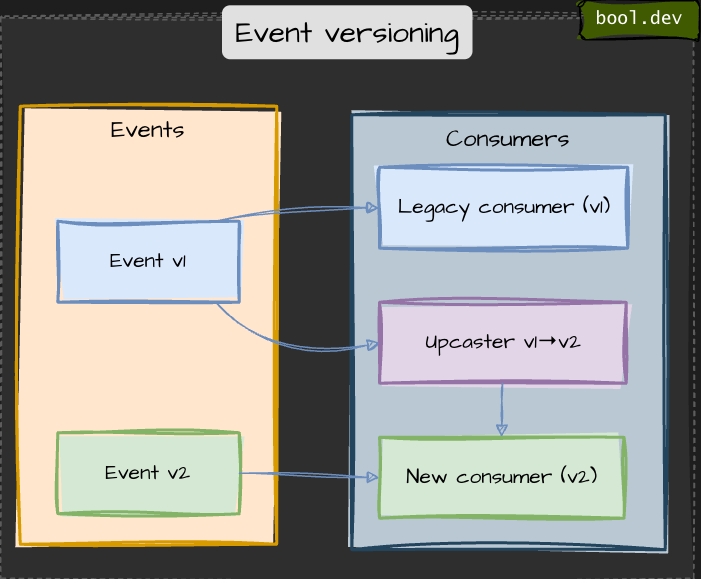
Side-by-side: Publish EventV1 and EventV2, and let consumers choose.
Downcast: offer a translation layer that emits older event shapes for legacy services.
Pros
- Keeps the event store immutable (suitable for audits).
- Upcast centralizes the transform logic.
Cons
- Upcasting adds CPU at rehydration.
- Side-by-side increases event surface and cognitive load.
When to use
- Event-sourced systems or systems with long-lived streams.
Translator/adapter layer
Put a translator between clients and storage. The adapter normalizes incoming requests and hides schema differences from the application.
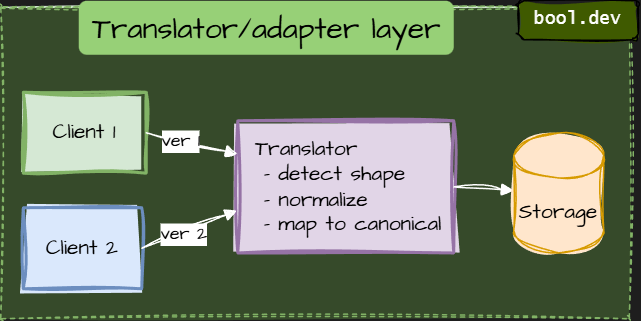
It normalizes the shape into the canonical internal model (or to multiple read-models).
An adapter can also implement migration-on-write or feature toggles.
Pros
- Isolates legacy clients without changing storage.
- Suitable for third-party or slow-updating clients.
Cons
- Single point of complexity/resources.
- Adds latency and extra testing surface.
When to use
When you can’t change clients quickly or need a facade for slow adopters.
How does it differ from "Schema versioning + adapters":
Schema versioning + adapters answers:
- When I read a single record, how do I convert it from version 1 to version 2?
- Do I write the migrated version back?
- How do I handle multiple document shapes?
This is internal transformation logic tied to data itself.
Translator/adapter layer answers:
- Different clients send different JSON shapes — how do I normalize them?
- How do I hide schema evolution from external consumers?
- How do I support old mobile clients who cannot update quickly?
This is request-level normalization, not document migration.
Read models and materialized views.
Leave the write model alone. Build new read models (projections) that serve new consumers, while allowing old consumers to continue using the old view.
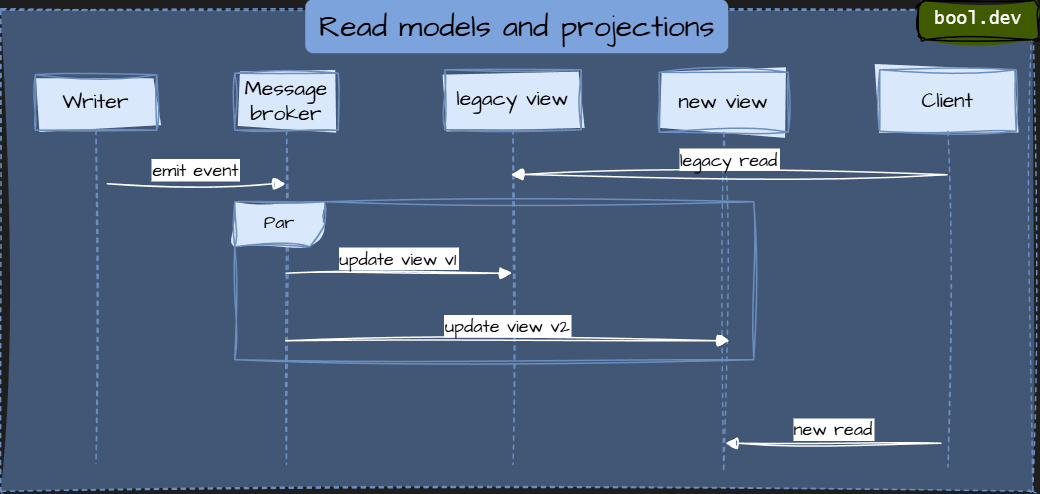
Update LegacyView and NewView in parallel.
Shift clients to the new read model when ready.
Pros
- Minimal disruption to writes.
- Safe rollback: keep the old read model until cutover.
- Tailored models for different UX needs.
Cons
- More storage and maintenance.
- Eventual consistency between write and new read views.
When to use
When new consumers need a different shape or a precomputed view.
Cheat Sheet