CAP Theorem

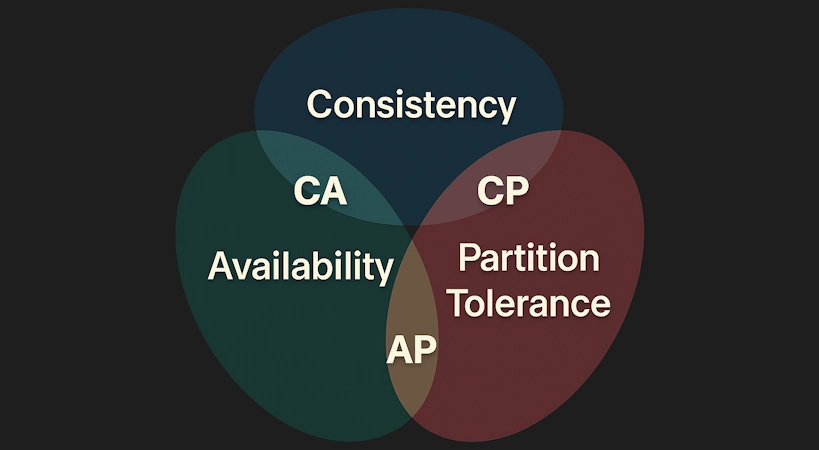
Every distributed system faces a tough choice: Consistency, Availability, or Partition Tolerance. The CAP theorem (also named Brewer's theorem ) says you can only have two of these three at the same time. Let’s break that down without the scary words.
The Core Idea
Imagine you have a database spread across several servers. Now, one server stops communicating with others due to a network issue.
What should the system do?
- Option 1: Stop answering until all servers agree on the same data.
- Option 2: Keep answering even if some answers are outdated.
You can’t do both at the same time. That’s the CAP theorem in action.
What Each Letter Means
C – Consistency:
Consistency ensures that every read receives the most recent write or an error. This means that all working nodes in a distributed system will return the same data at any given time.
A – Availability:
Availability guarantees that every request (read/write) receives a response, but does not ensure that it contains the most recent write. This means that the system remains operational and responsive, even if the reaction from some of the nodes doesn’t reflect the most up-to-date data.
P – Partition Tolerance:
Partition Tolerance means that the system continues to function despite network partitions, where nodes cannot communicate with each other.
Trade-Offs
CA (Consistency and Availability):

A system can be both consistent and available only when there are no network partitions.
Sounds nice, but in distributed systems, partitions always happen, so pure CA systems exist mostly on paper. Consider single-node databases or local applications.
AP (Availability and Partition Tolerance):
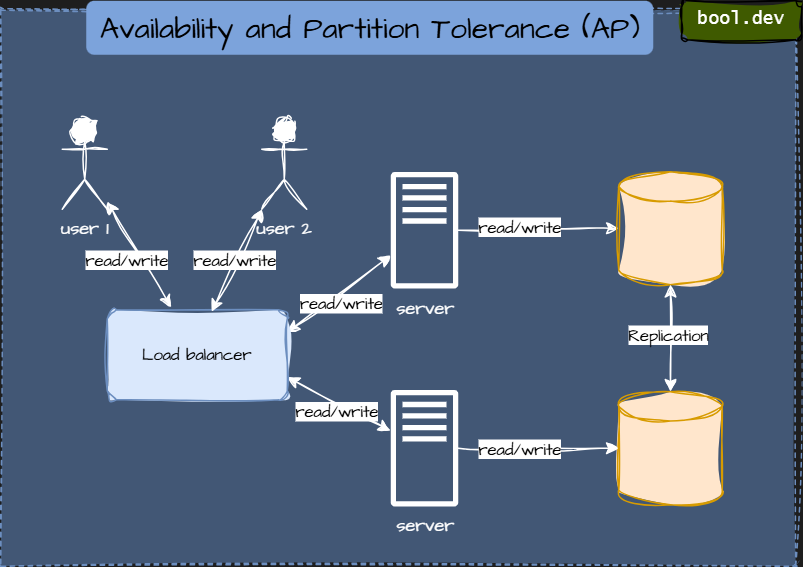
These systems remain online regardless of the circumstances. Even if parts of the network go silent, they still reply.
The price: temporary inconsistencies. Two users might read different data for a short while until replicas sync.
Used in high-uptime, user-facing systems where delays are worse than stale reads.
CP (Consistency and Partition Tolerance):
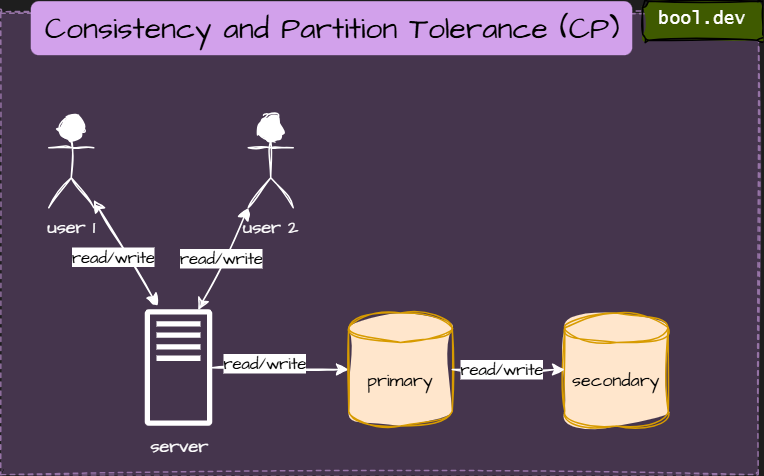
These systems prefer being right over being available. If nodes cannot communicate, some requests are rejected to protect data correctness.
Common in systems where accuracy matters more than immediate response, like finance or transactions.
Summary:
| Type | What it prioritizes | Example databases |
|---|---|---|
| CP (Consistency + Partition Tolerance) | Keeps data correct, might reject requests during partitions | MongoDB (strong mode), Redis (in cluster mode), HBase |
| AP (Availability + Partition Tolerance) | Always responds, may serve slightly outdated data | Cassandra, DynamoDB, CouchDB |
| CA (Consistency + Availability) | Works only without network issues (mostly theoretical) | Single-node SQL databases |
Key Takeaways
- Distributed systems must handle network failures — that’s reality.
- You can’t have Consistency, Availability, and Partition Tolerance all perfect at once.
- Choose what to sacrifice based on your app’s goals.
PACELC Theorem
Daniel Abadi proposed the PACELC theorem as an extension by introducing latency and consistency as additional attributes of distributed systems.
- If there is a partition (P), the trade-off is between availability and consistency (A and C).
- Else (E), the trade-off is between latency (L) and consistency (C).

The first part of the theorem (PAC) is the same as the CAP theorem, and the ELC is the extension. The entire thesis assumes that we maintain high availability through replication. Therefore, when a failure occurs, the CAP theorem prevails. However, if not, we still need to consider the tradeoff between consistency and latency in a replicated system.