Agile & Scrum Interview Questions and Answers (2026): for Developers, Architects, Team Leads, and Everyone


Welcome to the our .NET Interview Questions and Answers series exploring the ins and outs of C# and .NET! This part of the interview questions and answers covers Agile interview questions, including Scrum, Kanban, metrics, risk management, and enterprise scaling. For junior to senior engineers preparing for interviews
Also, please take a look at other articles in the series: C# / .NET Interview Questions and Answers
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
Agile Fundamentals Interview Questions and Answers
❓ What is Agile, and how is it different from traditional Waterfall delivery?
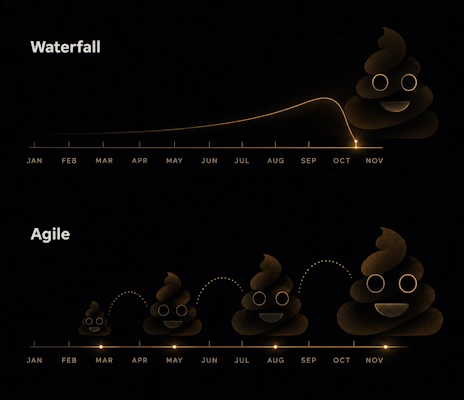
Waterfall
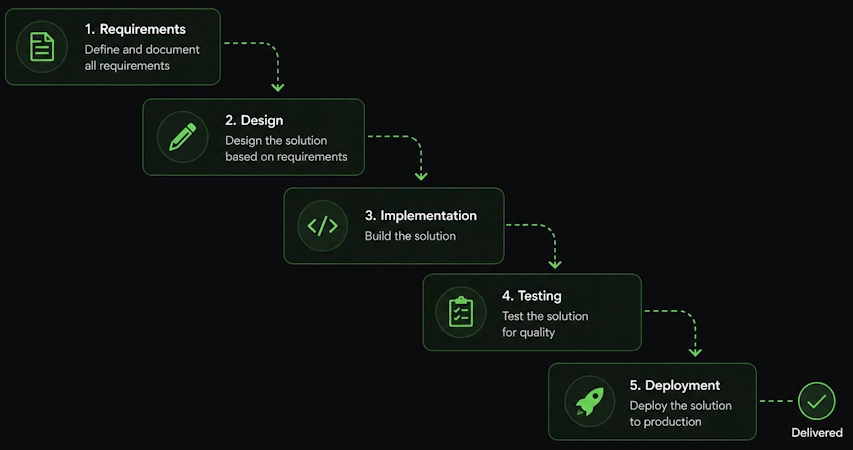
Waterfall follows a linear, sequential approach.
How it works:
- Plan everything up front
- Design the entire system
- Build the complete product
- Test the whole thing
- Deploy once
Each phase completes before the next begins. You move forward; you don't go back.
When it works:
- Requirements are stable and well-understood
- You know exactly what the customer needs
- Changes are expensive or impossible
- Projects have fixed deadlines and budgets
- Examples: embedded systems, construction, regulated industries
Challenges:
- Customers see nothing until the end
- Discovering problems late costs time and money
- Adapting to new requirements is difficult
- Risk concentrates at the end of the project
Agile
Agile works in short cycles called sprints, typically one to four weeks.
How it works:
- Deliver working features every sprint
- Gather customer feedback regularly
- Adjust priorities based on feedback
- Build incrementally
- Test continuously
You deliver, learn, and refine throughout the project.
When it works:
- Requirements are unclear or evolving
- You need to respond to market changes
- Customer feedback drives decisions
- Frequent releases create business value
- Examples: software products, startups, web applications
Challenges:
- Requires active customer involvement
- Less predictable final scope
- Demands discipline in team practices
- Works poorly with fixed contracts
❓ What are the core values and principles of the Agile Manifesto?

Four Core Values
- Individuals and interactions over processes and tools. Your team's collaboration matters more than rigid procedures or software.
- Working software over comprehensive documentation. Deliver functional code. Documentation supports the product, not the other way around.
- Customer collaboration over contract negotiation. Work with customers as partners. Respond to their needs, not just fulfill a contract.
- Responding to change by following a plan. Embrace new requirements. Plans serve you; you don't serve plans.
Twelve Principles
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
- Business people and developers must work together daily throughout the project.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
- Working software is the primary measure of progress.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
- Continuous attention to technical excellence and good design enhances agility.
- Simplicity, the art of maximizing the amount of work not done, is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
- At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
❓ What is the difference between Agile, Scrum, Kanban, and Lean?
These are related but distinct approaches to managing work. Think of Agile as the philosophy, and Scrum, Kanban, and Lean as different ways to practice it.
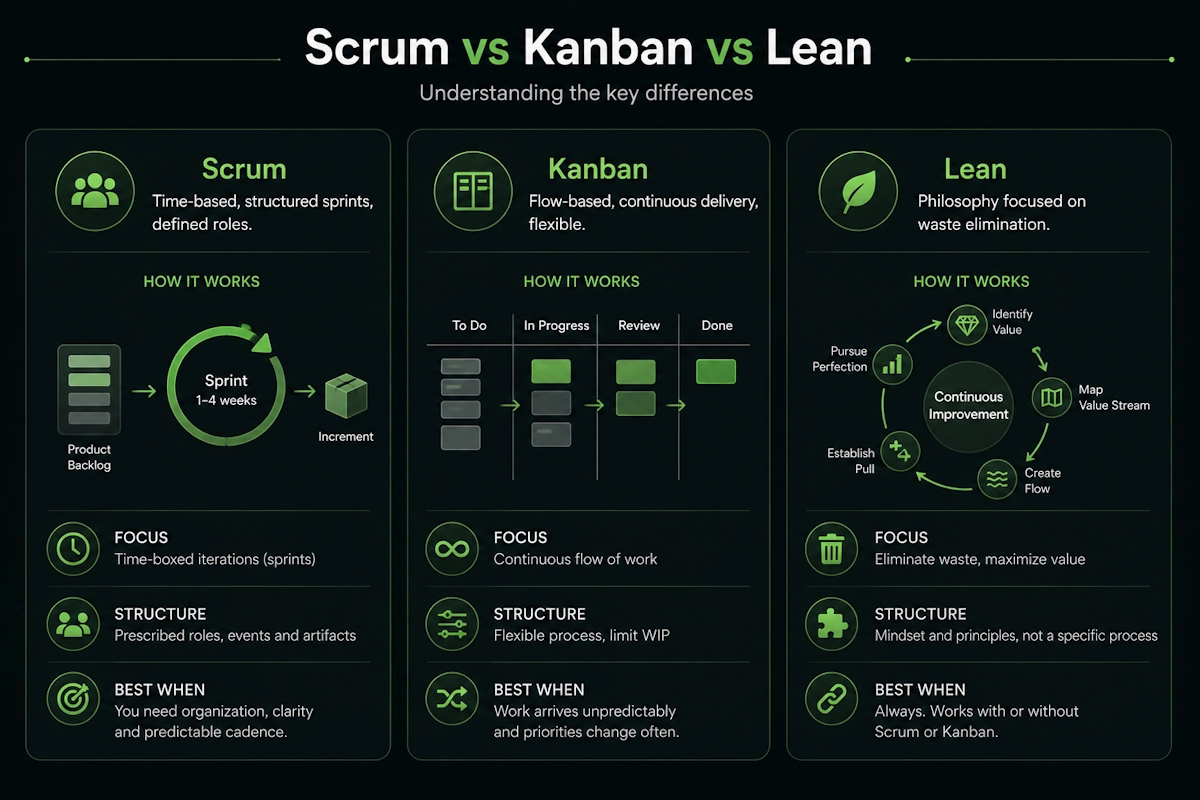
- Scrum: Time-based, structured sprints, defined roles. Best when you need organization.
- Kanban: Flow-based, continuous delivery, flexible. Best when work arrives unpredictably.
- Lean: Philosophy focused on waste elimination. Works with or without Scrum or Kanban.
Agile
Agile is the umbrella philosophy. It emphasizes iterative delivery, customer feedback, and responding to change. Scrum and Kanban are both Agile frameworks.
Scrum

Scrum structures work into fixed-length sprints, typically two weeks.
How it works:
- Plan work at the start of each sprint
- Hold daily standups to sync progress
- Complete work by the sprint end
- Review results with stakeholders
- Retrospect to improve next sprint
Best for:
- Teams needing a clear structure
- Projects with a defined scope per sprint
- Complex work requiring frequent replanning
- Organizations that want predictability
Key roles: Product Owner, Scrum Master, Development Team.
Kanban
Kanban visualizes work on a board with columns like "To Do," "In Progress," and "Done."
How it works:
- Pull work when you have capacity
- Limit work in progress
- Move tasks through the workflow
- Optimize continuously
- No fixed sprints
Best for:
- Continuous delivery environments
- Support teams handling varied requests
- Work arriving unpredictably
- Teams avoiding rigid schedules
Key concept: Work-in-progress limits prevent bottlenecks.
Lean
Lean reduces waste and maximizes value delivery.
Core idea: Identify what customers value. Eliminate everything else.
Focuses on:
- Removing non-value work
- Reducing handoffs and delays
- Empowering frontline workers to solve problems
- Continuous improvement
Best for:
- Manufacturing and operations
- Scaling organizations
- Cost reduction
- Systems thinking across departments
Lean is a broader philosophy than Scrum or Kanban. Many organizations combine Lean thinking with Scrum or Kanban execution.
❓ What problems does Agile try to solve in software delivery?

Late Discovery of Problems
Waterfall waits months before seeing working code. By then, fundamental misunderstandings surface. You've built the wrong thing.
Agile delivers working software every sprint. Problems appear early when fixes cost less.
Changing Requirements
Business needs to shift. Markets move. Competitors act. Waterfall locks in requirements upfront, then treats changes as failures.
Agile expects change. Your team adjusts priorities each sprint without derailing the project.
Disconnected Teams
Traditional delivery separates business from developers. Business hands off requirements. Developers build. QA tests. Each group works in isolation.
Agile puts them together. Daily standups, sprint reviews, and constant conversation keep everyone aligned.
Customer Dissatisfaction
Customers don't see the product until launch. They can't steer decisions. When they finally use it, the features don't match expectations.
Agile shows customers working software at the end of each sprint. They provide feedback immediately. Your team adjusts before investing more effort.
Predictability Without Flexibility
Waterfall promises a fixed scope and deadline. Reality rarely cooperates. Projects slip, costs balloon, quality drops.
Agile trades certainty for responsiveness. You deliver value incrementally. Scope adjusts to meet actual timelines and budgets.
Risk Concentration
Waterfall hides risk until testing begins. Integration fails. Performance suffers. Security holes appear. You discover problems when time and money have run out.
Agile distributes risk across sprints. Testing, integration, and deployment happen continuously. Major problems surface early.
Wasted Effort
Teams build features nobody needs. Documentation becomes outdated. Processes consume more energy than work.
Agile prioritizes ruthlessly. Build what delivers value. Skip what doesn't. Cut waste.
Team Burnout
Long projects with distant deadlines burn out developers. Waterfall offers no wins until the end.
Agile creates wins every sprint. Completed work, delivered value, and team recognition happen regularly.
Agile solves these problems by making software delivery visible, responsive, and human-centered.
❓ What are the most common misconceptions about Agile?
Agile Means No Planning
False. Agile plans continuously, not just once. You plan the sprint, the release, and the roadmap. Planning happens every day in standups and sprint reviews.
Agile Works Without Documentation
False. Agile values working software over excessive documentation. You still document requirements, architecture decisions, and code. You skip redundant paperwork.
Agile Eliminates Deadlines
False. Agile works within deadlines. You deliver incrementally toward fixed dates. Each sprint has a deadline. This makes timelines more reliable, not absent.
Agile Means Developers Do Whatever They Want
False. Agile requires discipline. Daily standups, sprint planning, code reviews, and retrospectives create structure. Self-organization means the team decides how to work, not that individuals ignore the plan.
Agile Works for Any Project
False. Agile thrives with unclear or changing requirements. It struggles with fixed contracts, stable requirements, and poorly communicating distributed teams. Waterfall works better for some projects.
Agile Removes the Need for Management
False. Agile needs strong product ownership and leadership. The Scrum Master removes obstacles. The Product Owner prioritizes work. Management changes form, not disappears.
Agile Means Constant Context Switching
False. Agile batches work by breaking down into sprints, so you focus on the same goals for weeks. Within a sprint, you minimize interruptions. Sprint boundaries reduce context switching compared to continuous reactive work.
Agile Guarantees Success
False. Agile increases the odds of delivering value. It surfaces problems early. It aligns teams with customers. Success still requires clear goals, skilled people, and good decisions.
Agile Scales Automatically
False. One team running Scrum works well. Ten teams coordinating across products require additional frameworks such as SAFe or LeSS. Scaling Agile is hard and demands intentional structure.
Agile Means No Technical Excellence
False. Agile principle nine explicitly states: "Technical excellence and good design enhance agility." Agile requires clean code, automation, testing, and refactoring. Technical debt slows Agile teams.
Agile Replaces Architecture and Design
False. Agile builds architecture incrementally rather than up front. You still design. You design more narrowly at the start, and detail emerges through implementation and feedback.
Agile Requires Daily Standups of 30 Minutes
False. Standups work best at 15 minutes for small teams. Larger teams need different coordination tools. If standups feel long or boring, shorten them or change the format.
The core misunderstanding is that:
Agile is not the absence of structure, planning, or discipline.
Agile is a different kind of structure that responds to reality instead of resisting it.
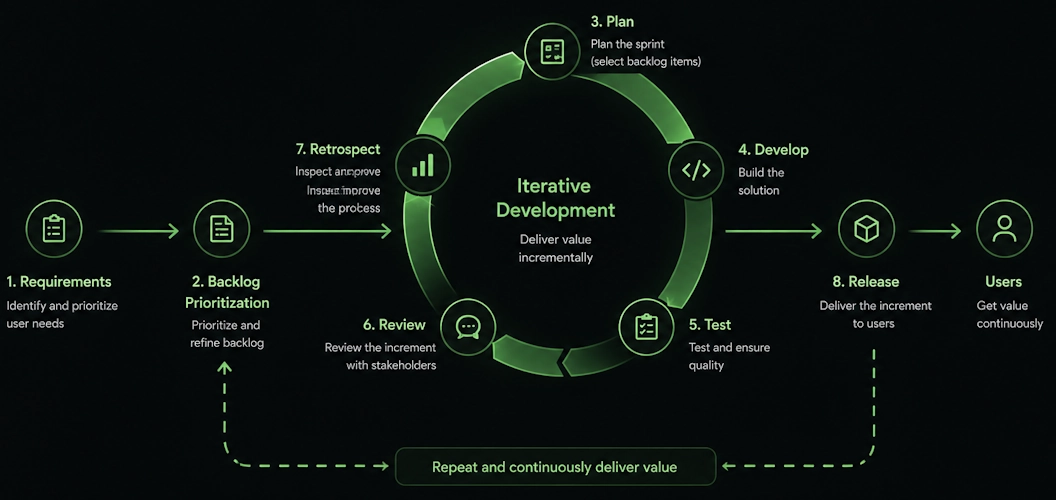
❓ What is iterative development, and why does Agile prefer short delivery cycles?
Iterative development means repeatedly refining and improving the product in cycles. Short cycles (1–4 weeks) reduce risk by making feedback frequent, catching wrong assumptions early, and reducing the cost of change. The longer you wait for feedback, the more expensive corrections become.
❓ What is incremental delivery, and how is it different from iterative delivery?
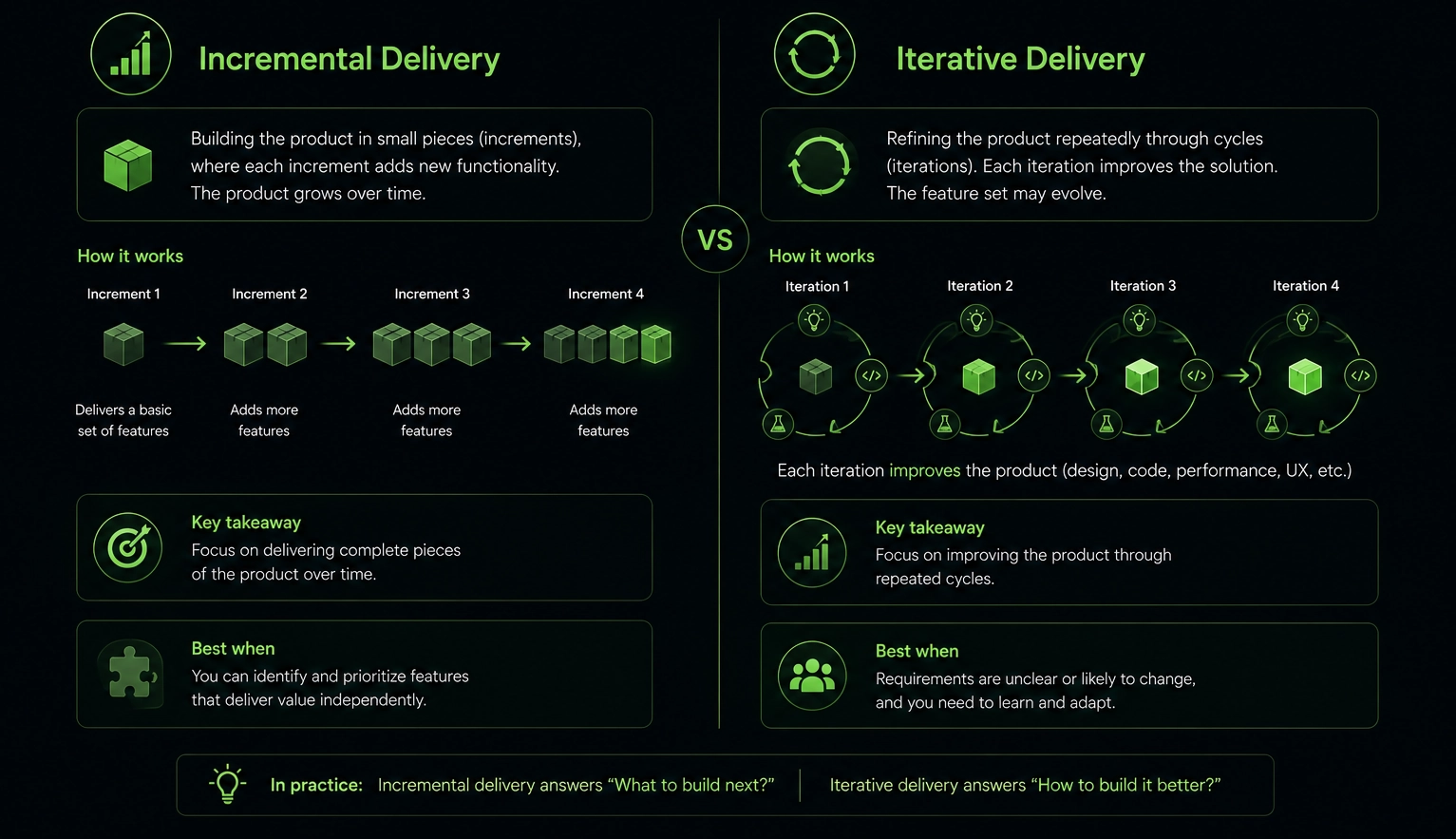
Incremental adds new things. Iterative improves existing things.
You typically do both. A product roadmap includes incremental releases of new features. Within each release, you iterate based on user feedback before moving to the next feature.
Incremental: Each sprint completes a new feature slice. You ship it to production.
Iterative: You gather feedback and refine the feature in the next sprint before moving forward.
Scrum teams release each sprint incrementally. They iterate based on sprint reviews and retrospectives. Kanban teams often iterate within work-in-progress limits before moving to the next feature.
The best products use both. You deliver new capabilities incrementally while iterating on what users actually need.
❓ What does "customer collaboration" mean in real Agile teams?
What It Actually Looks Like
- Daily or weekly contact. Someone from your team talks to customers regularly. Not quarterly reviews. Not annual planning. Weekly touchbases to understand what matters now.
- Customers in the room. During sprint planning, a customer or product representative sits with developers. They answer questions immediately. Developers understand context, not just requirements.
- Feedback shapes work. After each sprint, customers see working software. They use it. They tell you what works and what doesn't. You adjust priorities based on their input.
- Shared goals. The team and customer agree on what success looks like. You're not optimizing the contract. You're optimizing outcomes.
What It's Not
It's not about collecting requirements once and then building in isolation. It's not waiting until launch to show customers anything. It's not treating feedback as scope creep that incurs extra costs.
Real Examples
A financial software company embeds a customer representative in the development team. She attends standups. She clarifies ambiguous requirements in minutes instead of weeks. She flags features that don't match how customers actually work.
A SaaS team releases features to a beta customer group every two weeks. Users test immediately. They report problems and requests. The team prioritizes fixes and improvements for the next release. Features launch with built-in customer validation.
A healthcare startup invites clinicians to sprint reviews. Clinicians use prototypes. They spot workflow problems that developers missed. The team redesigns before writing code.
The Hard Part
Customers must commit time. They need to be available for questions and feedback. If customers are unavailable or uninterested, collaboration fails.
Your team needs to listen without defensiveness. Customers request things that don't fit your architecture. You explain trade-offs rather than dismiss their input. Together, you find solutions.
❓ What is the difference between output and outcome in Agile delivery?
The Output is what you deliver: features, code, and releases.
Outcome: user behavior change, business value, and revenue impact. Agile teams should measure outcomes, not just outputs. Shipping a feature (output) that nobody uses is not success. Good teams ask, "Did this change user behavior?" not just "Did we ship it?"
❓ Why do some companies fail when adopting Agile?
Common causes: Agile theater following ceremonies without the mindset. Management retains command and control over teams. No engineering discipline (no CI/CD, no automated tests). Treating Agile as a process change rather than a cultural shift. Scaling frameworks are imposed top-down. Product Owners without authority. Teams are pressured for velocity over quality.
Agile Metrics & Reporting Interview Questions and Answers

❓ What is a burndown chart?
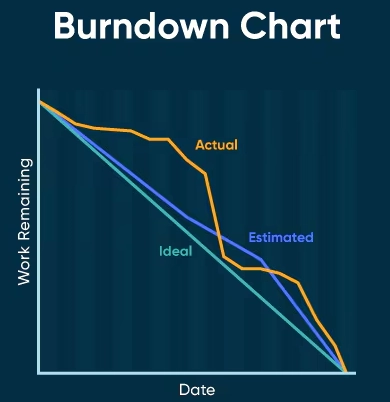
A burndown chart shows how much work remains in a sprint or release over time. The Y-axis is remaining work (story points or tasks), and the X-axis is time. Ideally, the line burns down to zero by the sprint end. It's useful for spotting early trouble in a sprint, but it can be gamed and doesn't show what was added mid-sprint.
❓ What is a burnup chart?
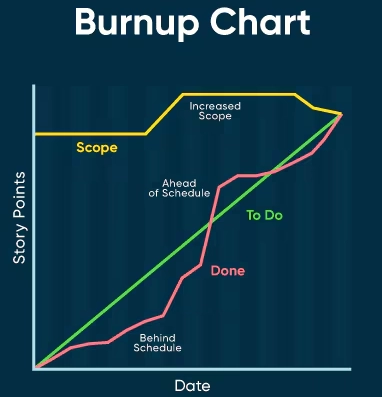
A burnup chart shows completed work over time and the total scope of work. Unlike burndown, it makes scope changes visible — if the total line rises, scope was added. More honest than burndown for tracking project-level progress and communicating with stakeholders.
❓ What is a cumulative flow diagram (CFD)?
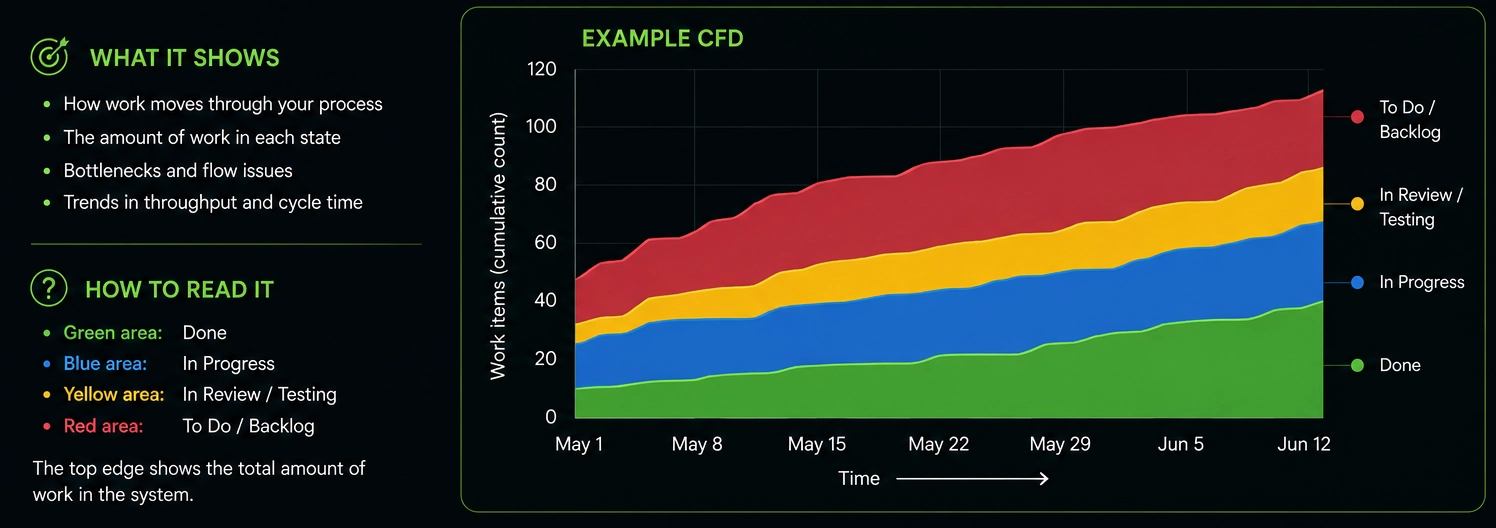
A CFD shows how many items are in each workflow stage over time (e.g., To Do, In Progress, Done). Wide bands in "In Progress" indicate WIP accumulation or bottlenecks. It's the primary visualization for Kanban teams and reveals systemic flow problems that sprint metrics hide.
❓ How do Agile metrics become toxic?
Metrics become toxic when you use them to judge people rather than understand systems. Velocity becomes a target to hit rather than a tool to forecast capacity. Story points shift from complexity estimates to measures of individual output, destroying collaboration.
The fix: Use metrics for conversation, not blame. Track team outcomes, not individual performance. Change metrics regularly so people stop gaming them.
Example of toxic metrics:
- Velocity as Pressure and Comparisons Across Teams
- Story Points as Effort
- Burn-Down Charts as Blame
- Test Coverage as a Target
- Utilization Rates as Efficiency
- Individual Sprint Commitments
- Bug Count Without Context
❓ What is DORA, and why does it matter?
DORA (DevOps Research and Assessment) measures four things: deployment frequency, lead time for changes, mean time to recovery, and change failure rate. These metrics show how fast and safely your team delivers software.
Why it matters: Teams with high DORA scores ship more often, recover from failures quicker, and break production less. DORA separates high performers from low performers across industries. Your metrics reveal bottlenecks in your delivery process.
❓ What are the four DORA metrics?
- Deployment Frequency. How often does your team release to production? High performers deploy multiple times per day. Low performers deploy monthly or less.
- Lead Time for Changes. Time from code commit to production. High performers: less than one hour. Low performers: months. Shorter lead time means faster feedback.
- Mean Time to Recovery. How long does it take to fix a production failure? High performers recover in under one hour. Low performers need days. Recovery speed matters more than preventing all failures.
- Change Failure Rate. Percentage of deployments that cause incidents. High performers fail less than 15% of the time. Low performers fail over 46%. This measures quality and testing effectiveness.
❓ How do you measure delivery predictability?
Track what you commit to versus what you deliver. Measure sprint goal completion rate (percentage of committed work finished each sprint). Monitor forecast accuracy by comparing estimated sprint capacity with actual output across 10 sprints. Low variance between estimates and results shows predictability.
Monitor lead time consistency. If your average lead time is two weeks but ranges from three days to six weeks, you're unpredictable. Tight variance around the average means customers trust your timelines.
Scrum Basics Interview Questions and Answers
❓ What is Scrum, and when does Scrum work well?
Scrum is a framework that organizes work into fixed timeboxes called sprints, usually two weeks long. Your team plans what to build at the start of the sprint, works together to complete it, and reviews the results with customers at the end of the sprint. A Scrum Master removes blockers. A Product Owner prioritizes work based on customer value. The team decides how to do the work.
When Scrum Works Well
- Scrum thrives when your requirements change often. Your customers discover what they need as you build. Each sprint shows them progress and gives them a chance to adjust priorities. This feedback loop keeps you building the right thing.
- Scrum works for teams that need structure. Daily standups, sprint planning, and reviews create rhythm. Everyone knows what's expected and when. This clarity helps teams stay aligned and productive.
- Scrum delivers predictability. Two-week cycles let you forecast when features ship. You commit to realistic work, finish it, and prove your estimates. Over time, your forecasts improve.
When Scrum Struggles
- Scrum breaks down with unstable teams. New people join mid-sprint. People move between projects. The team never builds momentum.
- Scrum fails when customers are unavailable. You need product owners in sprint planning and reviews to answer questions and validate work. Absent customers create guessing and rework.
- Scrum doesn't fit distributed teams across many time zones. Daily standups become painful. Real-time collaboration suffers. Asynchronous work, like Kanban, works better.
- Scrum struggles with fixed-scope and fixed-deadline contracts. Customers demand specific features by a date. Scrum adapts scope based on reality. This flexibility conflicts with rigid agreements.
Use Scrum when your team is stable, customers are present, and you value learning over certainty.
❓ What are the Scrum roles and responsibilities?
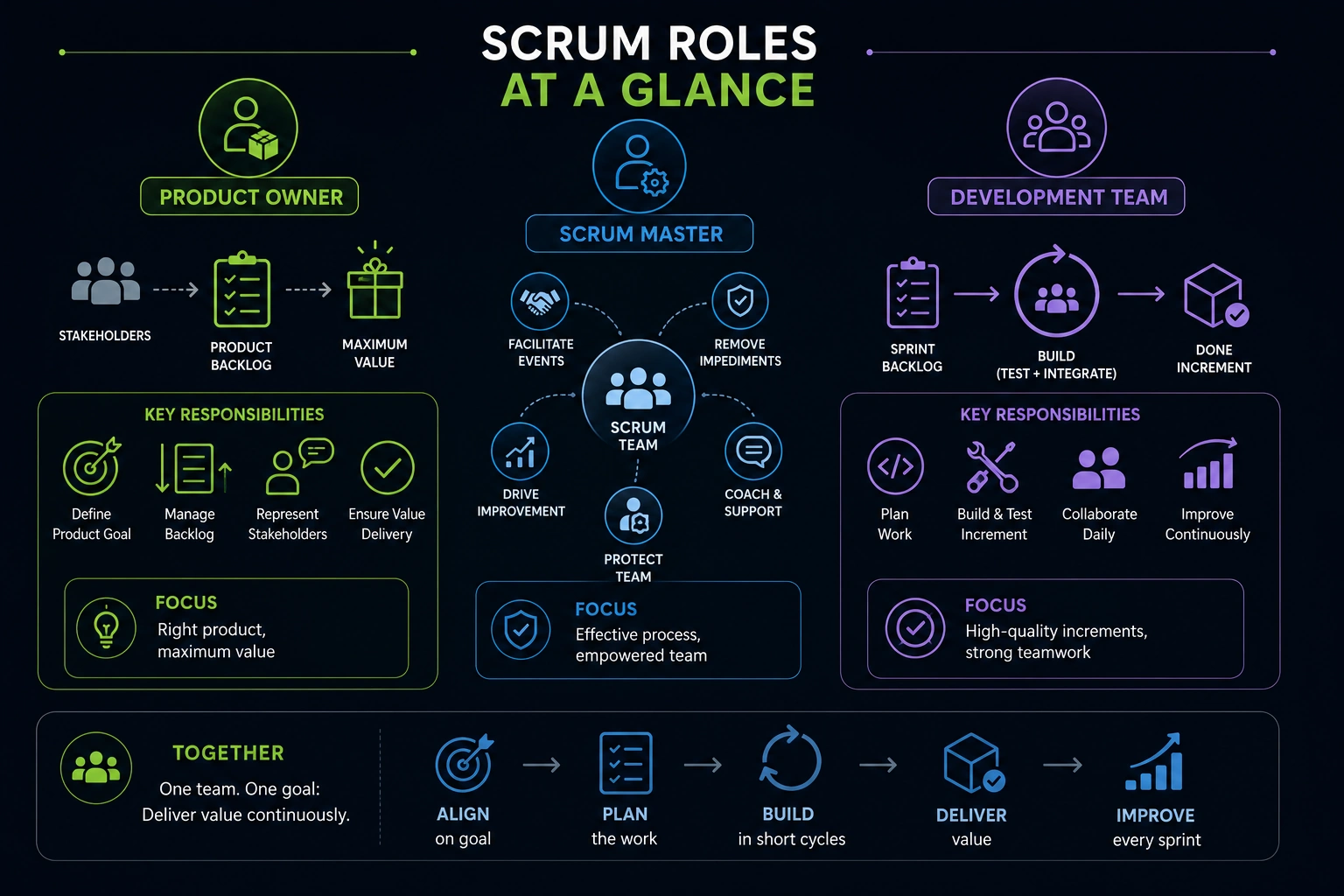
Product Owner
The Product Owner decides what to build. You prioritize the backlog based on customer value and business goals. You write user stories that describe features. You answer developer questions during sprints. You accept completed work or reject it if it doesn't meet expectations.
Without a strong Product Owner, teams build the wrong things or waste time asking for clarification.
Scrum Master
The Scrum Master removes obstacles that slow the team. You facilitate sprint planning, daily standups, sprint reviews, and retrospectives. You protect the team from interruptions and scope creep. You coach the team to improve how they work together.
The Scrum Master is not a project manager giving orders. You serve the team and help them self-organize.
Development Team
The team builds the product. You estimate work, plan sprints, and deliver finished code. You collaborate daily through standups. You decide how to approach technical problems. You own quality through testing and code review.
Teams work best with five to nine people. Larger teams need multiple Scrum teams. Team members stay the same throughout a project so you build trust and rhythm.
❓ What is the difference between Product Owner, Project Manager, and Scrum Master?
The Product Owner owns the vision. The Project Manager owns the plan. The Scrum Master owns the process.
The Product Owner says, "Build search filters." The Project Manager says, "Finish by March and stay under budget." The Scrum Master says, "Let's remove the blocker preventing the team from finishing."
In Agile teams, the Project Manager role often merges with the Product Owner or disappears entirely. The Scrum Master handles the process. The team handles execution.
Product Owner
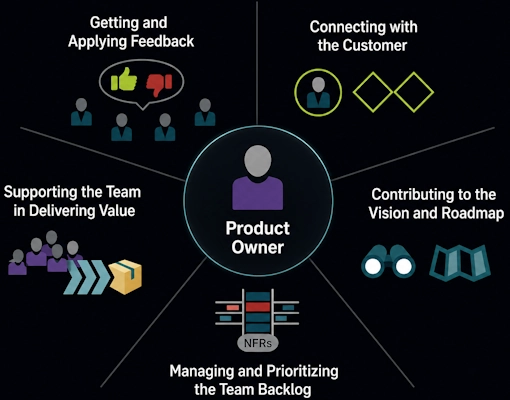
The Product Owner decides what to build and why. You own the product vision and roadmap. You prioritize the backlog based on customer value and business impact. You talk to customers constantly to understand their needs. You accept or reject finished work based on whether it meets requirements.
You're accountable for the product's success. If features don't deliver value, that's on you.
Project Manager
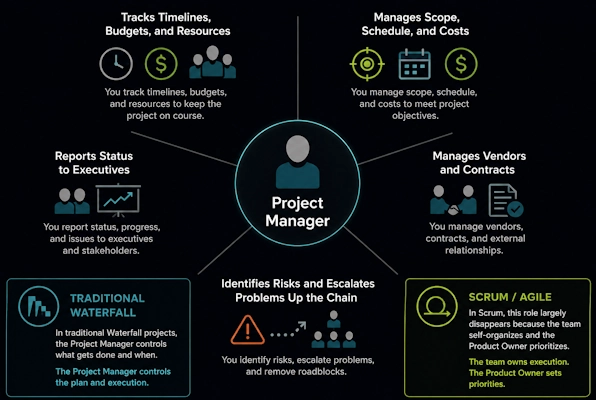
The Project Manager tracks timelines, budgets, and resources. You manage scope, schedule, and costs. You report status to executives. You manage vendors and contracts. You identify risks and escalate problems up the chain.
In traditional Waterfall projects, the Project Manager controls what gets done and when. In Scrum, this role largely disappears because the team self-organizes and the Product Owner prioritizes.
Scrum Master
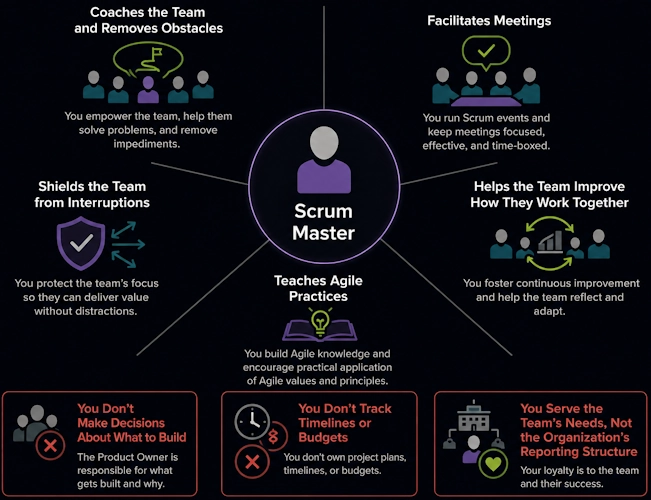
The Scrum Master coaches the team and removes obstacles. You facilitate meetings. You shield the team from interruptions. You help the team improve how they work together. You teach Agile practices.
You don't make decisions about what to build. You don't track timelines or budgets. You serve the team's needs, not the organization's reporting structure.
❓ What makes a good Product Owner?
A good Product Owner is available and accessible. You answer questions immediately rather than leaving developers guessing. You talk to customers regularly, so you understand their real needs, not assumptions.
You communicate clearly. User stories are unambiguous. You explain the "why" behind features. You say no to requests that don't fit your vision, protecting the team from scope creep.
You make decisions with incomplete information. You prioritize ruthlessly. You understand technical trade-offs, so you don't promise impossible timelines. Teams need direction and clarity, not endless deliberation.
❓ What makes a good Scrum Master?
A good Scrum Master removes obstacles quickly. When the team blocks on a technical issue, an unclear requirement, or an external dependency, you fix it. You don't just identify problems; you solve them.
You facilitate without controlling. You run meetings but don't dictate decisions. You coach the team to solve their own problems rather than hand them answers. You ask questions that help them think.
You protect the team from interruptions and scope creep. You shield developers from constant requests so they can finish sprint work. You push back on executives demanding mid-sprint changes.
You coach the organization on Agile practices. You teach stakeholders why interrupting sprints hurts delivery. You help executives understand why velocity matters and what it means. You advocate for the team's needs.
❓ What is a cross-functional team?
A cross-functional team has all the skills needed to deliver work without depending on other teams. Instead of separate teams for frontend, backend, and QA, one team includes developers, testers, and designers who collaborate daily.
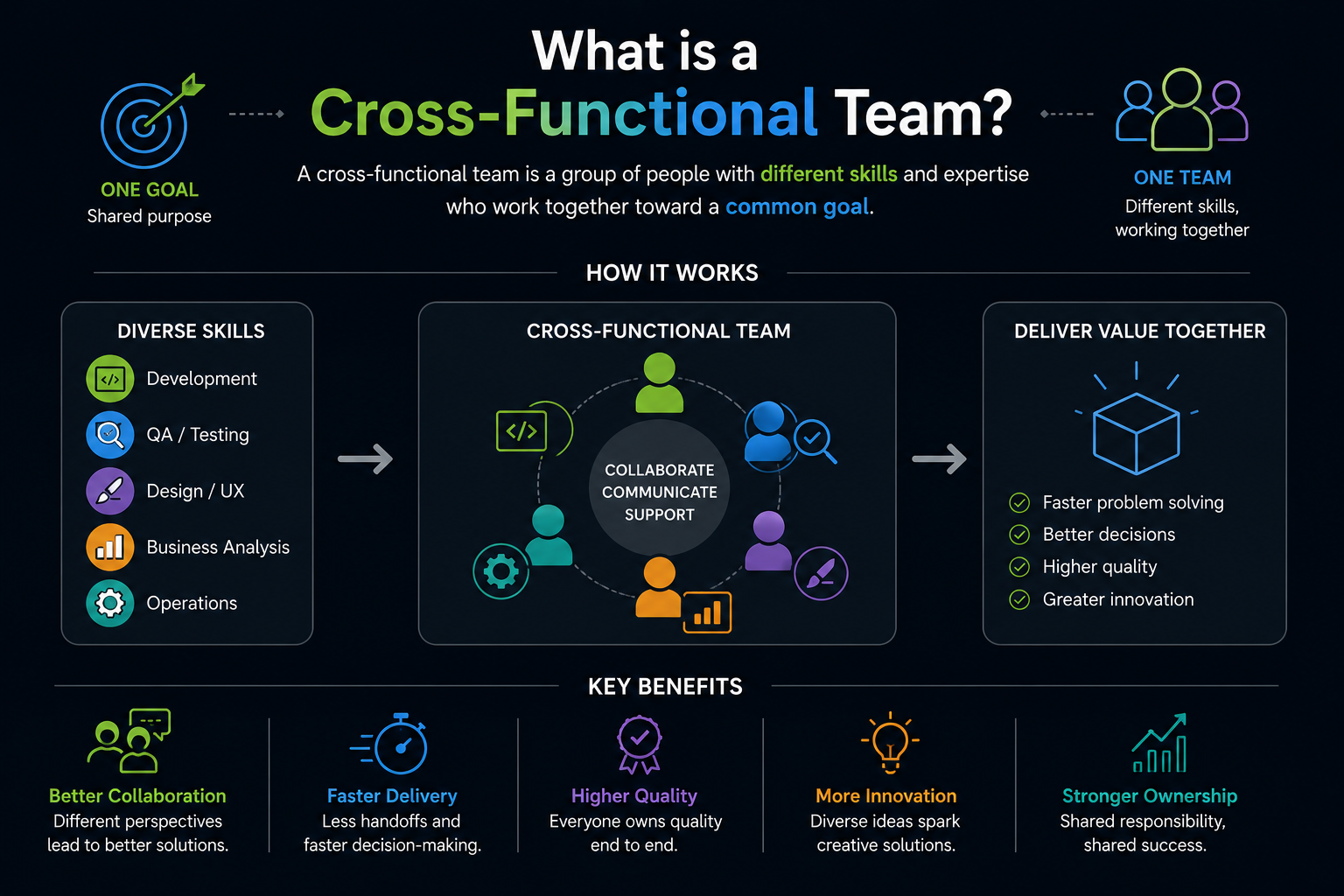
Cross-functional teams move faster because they don't wait for handoffs. A frontend developer doesn't wait for a backend team to finish. They work together, solve problems together, and finish features together.
These teams own their outcomes. They can't blame delays on another department. They make trade-off decisions without escalating. They innovate faster because all perspectives are in the room.
The tradeoff: cross-functional teams are harder to staff. You need people with broad skills or a willingness to learn. Larger organizations struggle because specialists resist moving to generalist teams.
❓ What is a self-organizing team?
A self-organizing team decides how to do the work without a manager telling them. During sprint planning, the team chooses which tasks to tackle and who does what. You don't assign work; the team volunteers based on skills and capacity.
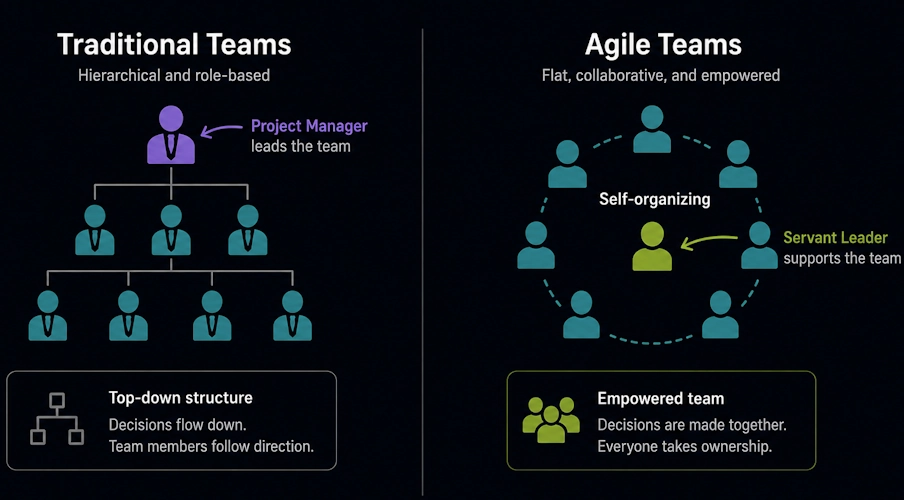
The team solves problems together. If code review is slow, you discuss and change the process. If standup feels useless, you shorten it or change the format. You own how you work.
This requires trust and autonomy. Managers must step back. Micromanaging kills self-organization. The team needs authority to make decisions about their work.
Self-organizing teams deliver better results because people feel a sense of ownership. They're motivated to improve rather than follow orders. Problems surface faster because the team identifies them, not a manager.
❓ What is the purpose of a Sprint?
To create a timebox within which a team delivers a potentially shippable product increment toward the Sprint Goal. The fixed duration creates rhythm, forces prioritization, and generates regular feedback opportunities. The Sprint Goal gives the sprint coherence; it's not just a bag of tickets.
❓ What is the recommended Scrum team size, and why?
3–9 developers (excluding PO and SM).
Too small: insufficient skills coverage.
Too large: communication overhead grows exponentially, coordination becomes harder, and self-organization breaks down.
The "two-pizza rule" (Jeff Bezos) applies:
"if you can't feed the team with two pizzas, it's too big"
❓ What is the Definition of Done (DoD)?
Definition of Done is a checklist that defines when work is actually finished. It includes code review, automated testing, documentation, and deployment readiness. A story isn't done until it meets every item on the checklist.
Without a clear DoD, "done" means different things to different people. One developer thinks done means code written. Another thinks it means tested. The team ships incomplete work with bugs and missing documentation.
A strong DoD ensures quality and consistency. Every story goes through the same standards. The team builds confidence that the finished work is truly ready for customers.
❓ What is the Definition of Ready (DoR)?
Definition of Ready is a checklist that defines when a story is ready to enter a sprint. It includes clear acceptance criteria, estimated effort, no dependencies blocking work, and customer clarity on what success looks like.
A story isn't pulled into the sprint until it meets every item on the checklist. This prevents developers from starting work on ambiguous or incomplete stories, which would waste time.
A strong DoR saves sprints from chaos. Teams don't waste time in standups asking clarifying questions. Stories move smoothly from backlog to completion because everyone understands what's needed before work starts.
Scrum Ceremonies Interview Questions and Answers
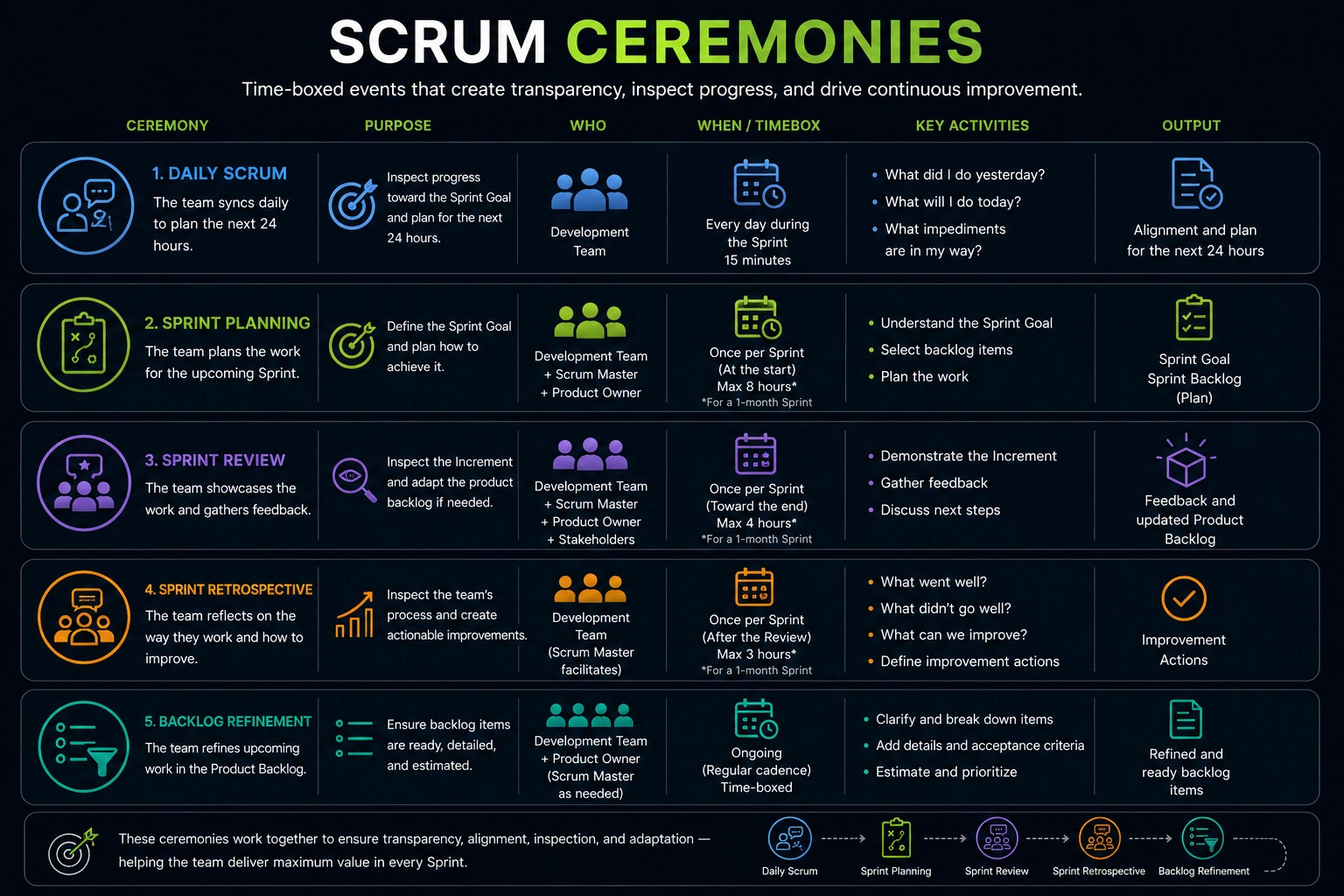
❓ What happens during Sprint Planning?
The team selects items from the top of the backlog, agrees on a Sprint Goal, and breaks selected stories into tasks. The PO clarifies requirements; the team estimates and commits to what's achievable. Output: sprint backlog + Sprint Goal. Duration: up to 8 hours for a 2-to 4-week sprint.
❓ What makes Sprint Planning ineffective?
Items aren't ready (no acceptance criteria, unclear scope). PO is absent or can't make decisions. Team commits to too much and pads with a buffer. No, a Sprint Goal is just a list of tasks. Estimates are driven by pressure rather than honest assessment. Planning takes 4 hours, but the sprint goal is unclear.
❓ What is Daily Scrum, and what is its real purpose?
Daily Scrum is a 15-minute meeting every morning where the team syncs progress. Each person answers three questions: What did I complete yesterday? What will I complete today? What's blocking me?
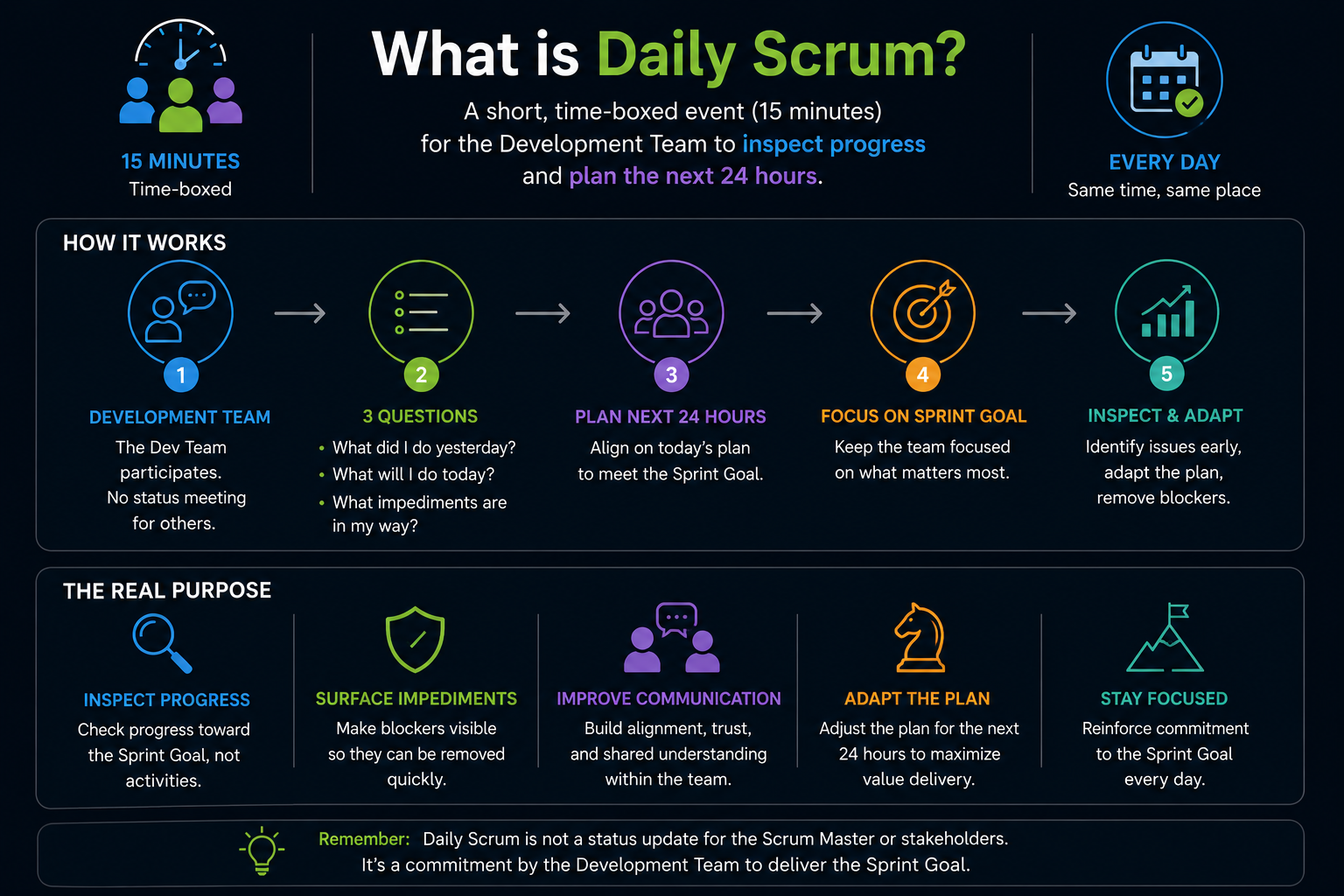
The real purpose is not status reporting. It's identifying blockers and coordinating work. If someone is stuck, the team unblocks them immediately. If two people are working on related tasks, they align. The meeting keeps work flowing.
A bad Daily Scrum becomes a status report to the Scrum Master. People recite what they did. Nothing gets solved. These meetings waste time and kill momentum.
A good Daily Scrum surfaces problems in minutes and moves on. If a blocker needs deep discussion, you take it offline after the meeting instead of consuming everyone's time.
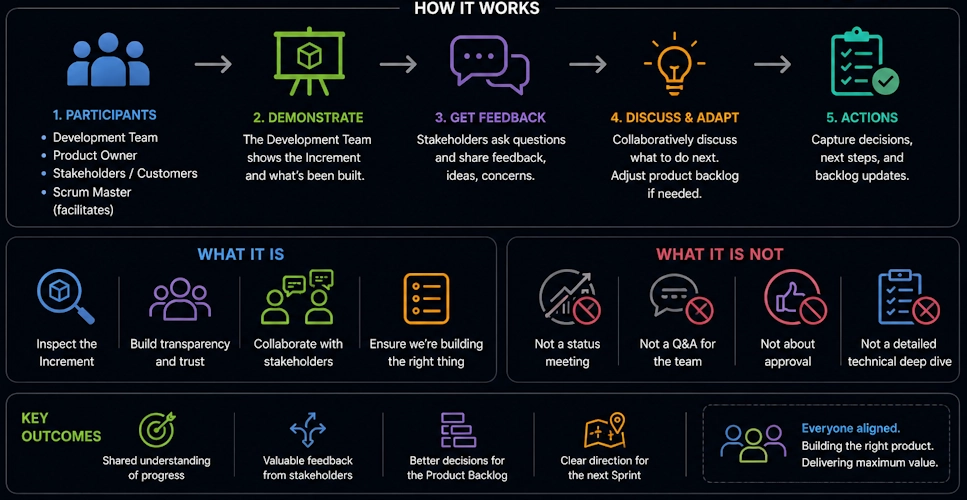
❓ What is a Sprint Review, and who should attend?
❓ What is a Sprint Retrospective, and why is it important?
A Sprint Retrospective is a meeting at the end of each sprint where the team reflects on how they worked together. You discuss what went well, what didn't, and what to change in the next sprint. You commit to specific improvements.
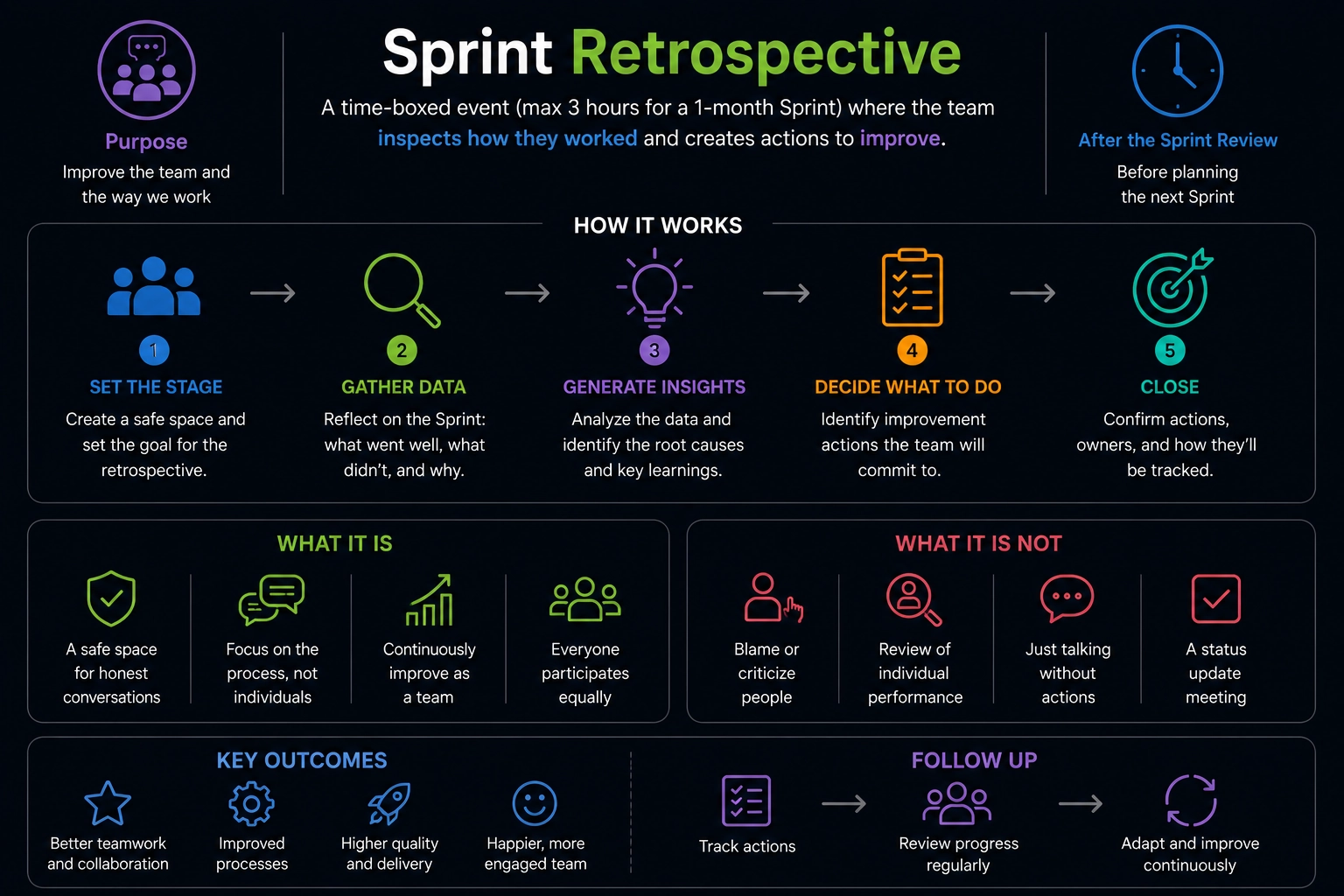
The real purpose is continuous improvement. Teams that reflect improve faster than teams that repeat the same mistakes. You identify bottlenecks, fix communication problems, and eliminate waste.
Without retrospectives, teams get stuck in patterns. Standups stay too long. Code review takes forever. People work overtime. Nothing changes because nobody surfaces the problems.
A good retrospective creates psychological safety. People speak honestly about what's broken without fear of blame. You experiment with small changes and measure if they help. Over time, these small improvements compound into a high-performing team.
❓ How do you run effective retrospectives?
- Create psychological safety first. Make clear that retrospectives are about improving work, not blaming people. What's said in the room stays in the room. People must feel safe speaking honestly.
- Use a simple structure. Ask what went well, what didn't go well, and what to change. Gather ideas from everyone. Vote on the top problems. Pick one or two concrete changes to try next sprint.
- Focus on actionable improvements. "Communication was bad" is useless. "Code review feedback takes three days" is specific. You can fix it by setting an expected response time.
- Assign owners to improvements. Don't just agree to change something. Someone commits to making it happen and reports back at the next retrospective.
- Keep it short. Thirty minutes for a two-week sprint works. Longer meetings bore people and generate complaints instead of solutions.
- Rotate facilitators. Different people run the retrospective each time. This prevents it from becoming the Scrum Master's meeting and ensures the team owns improvement.
- Track what you changed and whether it worked. Did reducing standup to ten minutes help? Did pairing on complex code reduce bugs? Measure impact so improvements stick.
❓ What anti-patterns appear in Scrum ceremonies?
- Sprint Planning takes too long. Teams debate every detail for hours. Developers haven't thought through the work. The Product Owner hasn't prioritized clearly. Fix it by preparing backlog items before planning and trusting the team to figure out details during the sprint.
- Daily Scrum becomes a status report. The Scrum Master asks each person what they did. People recite tasks. Nothing gets solved. Switch to peer-to-peer conversation focused on blockers, not status.
- Retrospectives blame individuals. "Bob made a mistake on that deploy." People stop speaking honestly. Create psychological safety by focusing on systems, not people. Ask why the mistake happened, not who caused it.
- Sprint Review shows incomplete work. The team demos unfinished features or half-baked ideas. Stakeholders leave confused about what was shipped. Only demo finished work that's production-ready.
- Backlog refinement never happens. Stories arrive at sprint planning unprepared. No estimates. No acceptance criteria. Planning becomes guessing. Schedule regular refinement sessions so stories are ready before sprints start.
- Team ignores retrospective changes. You identify improvements but don't implement them. Next sprint is identical. Pick one or two changes, assign owners, and measure impact. Small wins build momentum.
- Sprints ignore dependencies. Stories require other teams' work. The team waits. Velocity drops. Plan sprints by identifying dependencies early and either removing them or accepting the wait.
Scrum Estimation & Planning Interview Questions and Answers
❓ What are Story Points, and why do Agile teams use them?
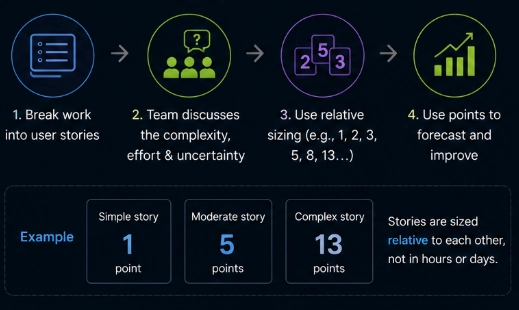
Story points are a relative unit of estimation representing complexity, effort, and uncertainty - not hours. Teams use them because humans are better at comparing complexity (this is twice as hard as that) than predicting absolute duration. They also abstract away individual skill differences and encourage team-level ownership of estimates.
❓ What is velocity, and why is it often misused?
Velocity is the average story points completed per sprint over recent sprints. It's useful for a team's own capacity planning. It's misused when: compared across teams (different point scales), used as a performance KPI, demanded to increase every sprint, or used to commit to delivery dates without acknowledging uncertainty.
❓ What is sprint capacity planning?
Calculating how much work a team can realistically take on in a sprint, accounting for team member availability (holidays, meetings, PTO), typical overhead, and historical velocity. Capacity planning prevents overcommitment and is separate from estimation; it's about availability, not complexity.
❓ What is the difference between estimation and commitment?
Estimation is the team's best guess at how complex a story is. You discuss unknowns, ask questions, and assign story points. Estimation is collaborative and honest. It's not a promise.
Commitment is what the team promises to finish by the end of the sprint. You commit to a realistic amount of work based on historical velocity and capacity. If someone is sick or pulls out mid-sprint, you adjust the commitment.
❓ What estimation techniques exist in Agile teams?
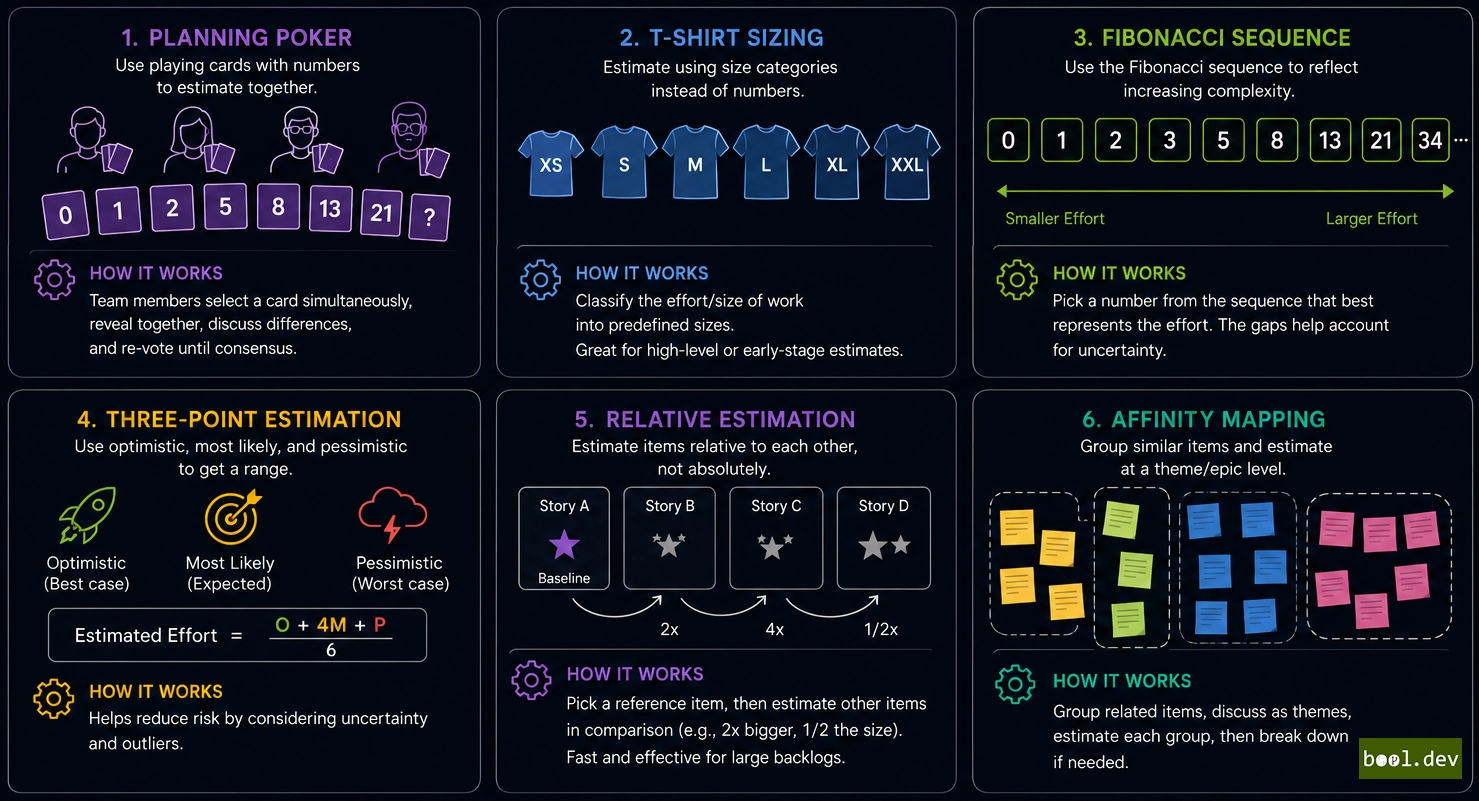
- Planning Poker. Each developer estimates a story silently using cards with point values. Everyone reveals at once. If estimates differ widely, you discuss why and re-estimate. This prevents anchoring and surfaces different perspectives.
- T-shirt Sizing. Stories get labeled small, medium, large, or extra-large instead of points. Later, you convert sizes to points. This works well for rough roadmap planning before stories are detailed.
- Fibonacci Sequence. Use 1, 2, 3, 5, 8, 13, 21 instead of consecutive numbers. The gaps force conversation. Why is this 5 instead of 4? This prevents false precision and acknowledges that uncertainty increases with complexity.
- Three-point Estimation. Estimate best case, worst case, and most likely. Calculate the average. This surfaces risk. A story with wide gaps (best case: 2 points, worst case: 13) needs to be broken down.
- Relative Estimation. Pick a baseline story worth 5 points. Compare all other stories to it. "This is half as complex, so 2 points." "This has more unknowns, so 8 points." Relative estimation is faster and more accurate than absolute.
- Affinity Mapping. Lay out stories on a wall. The team groups them by complexity without discussing points. Then assign point values to groups. This finds consensus quickly without debate.
The best technique depends on your team. Start with Planning Poker. If it feels slow, switch to Affinity Mapping. Experiment and keep what works.
❓ Why do estimates often fail in software projects?
Estimates assume a perfect understanding of a problem that isn't yet solved. Unknown dependencies, changing requirements, technical debt surprises, optimism bias, and pressure to give low numbers. The further the estimate is from the delivery date, the less accurate it is. The solution is shorter planning horizons and forecasting based on historical data rather than estimation.
❓ What is technical debt, and how should Agile teams manage it?
Technical debt is the cost of choosing speed over quality. You ship code with shortcuts. Tests are incomplete. Documentation is missing. The code works, but it costs more to maintain and change later.
Like financial debt, technical debt compounds. Early shortcuts seem harmless. Over time, the codebase becomes fragile. Changes take longer. Bugs multiply. New features slow down because developers navigate messy code.
How Agile Teams Should Manage It
- Pay it down incrementally. Dedicate 10 to 20 percent of each sprint to refactoring and technical improvements. Don't save it for a later cleanup sprint that never happens. Small, continuous work prevents debt from exploding.
- Track it explicitly. Create backlog items for technical work. Make it visible. If you ignore debt, it grows invisibly and kills velocity later.
- Prevent new debt. Code review catches shortcuts. Automated testing ensures quality. Pay attention to code quality metrics. Prevent new debt before it accumulates.
- Measure the cost. Track how much debt slows you down. If a feature takes twice as long due to bad code, quantify the time. Show stakeholders the impact. This justifies the time spent paying it down.
- Balance delivery and quality. You need both. Ignore quality, and debt grows. Obsess over quality and you ship nothing. Most teams should invest 70 percent in new features and 30 percent in quality and debt payoff.
Technical debt kills Agile teams. High debt makes sprints unpredictable. Velocity drops. People work overtime. Pay it down consistently, or it destroys your delivery rhythm.
❓ How do Agile teams balance feature work and refactoring?
Common approaches include allocating a fixed percentage of sprint capacity to tech debt (10–20%). Use the Boy Scout Rule: leave the code better than you found it. Make refactoring visible in the backlog rather than hiding it. Relate tech debt to business impact to get PO buy-in. Never ship a feature without addressing the debt it creates.
Backlog & Requirements Interview Questions and Answers

❓ What is a Product Backlog?
A Product Backlog is a prioritized list of tasks for your team. It includes user stories, bug fixes, and technical improvements, all of which are managed and prioritized by the Product Owner.
The backlog constantly evolves as team needs and priorities shift. Items at the top are detailed and ready for upcoming sprints, while those at the bottom are rough concepts that may never be implemented. When planning a sprint, the team selects work from the top of the backlog. Only the most valuable tasks get prioritized this way.
- Keep the backlog manageable by removing unnecessary items. Combine similar requests to help keep it focused and useful.
- Make it a habit to regularly refine the backlog. Write clear acceptance criteria, break down large items, and estimate complexity to ensure efficient sprint planning.
- The backlog is always evolving as new customer insights emerge and business priorities shift. As a result, top items remain well-defined and ready for sprints, while items at the bottom reflect early-stage ideas that might never ship.
- Your team always pulls work from the top during sprint planning, ensuring only the most valuable work is considered. This approach pushes the Product Owner to maintain strict prioritization.
- A healthy backlog stays manageable. Too many items cause confusion; too few and you risk running out of work. Keep it lean by removing or consolidating items as needed.
- Refine the backlog before each sprint: write acceptance criteria, break large items into smaller ones, and estimate complexity to enable efficient sprint planning.
❓ What makes a good backlog item?
- Clear: the team understands what it is. Valuable: it delivers benefit to the user or the business.
- Sized appropriately: small enough to complete in a sprint. Testable: acceptance criteria exist.
- Prioritized: its position reflects its value. Backlog items that are too large, vague, or untestable cause planning problems and scope creep.
❓ What is backlog refinement?
An ongoing activity (not a fixed ceremony in Scrum, though often scheduled) in which the team and PO review upcoming backlog items, clarifying requirements, splitting large stories, estimating, and ordering. Goal: ensure the top of the backlog is always sprint-ready. Typically, 10% of sprint capacity is spent on refinement.
❓ What is a user story?
A short description of a feature from the user's perspective: "As a [type of user], I want [action] so that [benefit]." It's a placeholder for a conversation, not a complete specification. The story captures who needs something and why — the how is discovered in conversation with the team.
❓ What is the difference between epic, feature, story, and task?
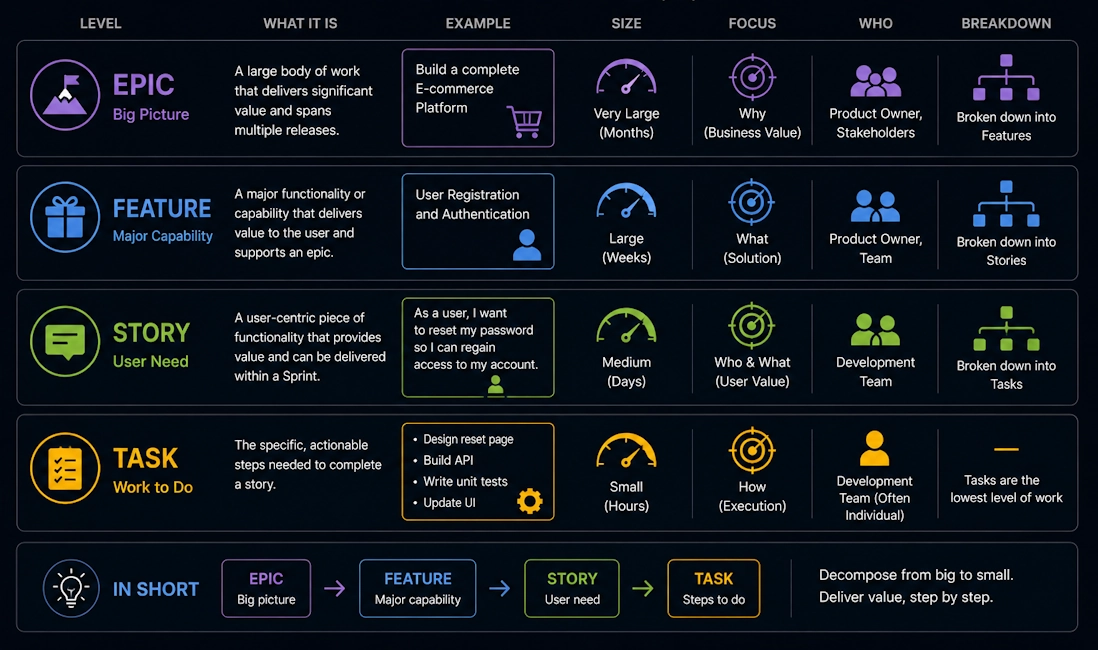
- Epic. A large body of work that takes multiple sprints to complete. Examples: "Build payment system" or "Redesign user dashboard." Epics are too big to fit into a single sprint. You break them into smaller pieces.
- Feature. A piece of functionality that delivers customer value. Examples: "Add dark mode" or "Enable two-factor authentication." Features usually fit in one or two sprints. They're what customers see and use.
- Story. A small unit of work that one developer completes in a few days. Examples: "Add dark mode toggle to settings page" or "Send verification email after signup." Stories have acceptance criteria that define what done means. The team estimates stories in points.
- Task. Work that supports a story but isn't directly visible to customers. Examples: "Update database schema" or "Refactor authentication module." Tasks are internal work. They enable stories but don't ship as standalone features.
❓ What is INVEST in Agile?
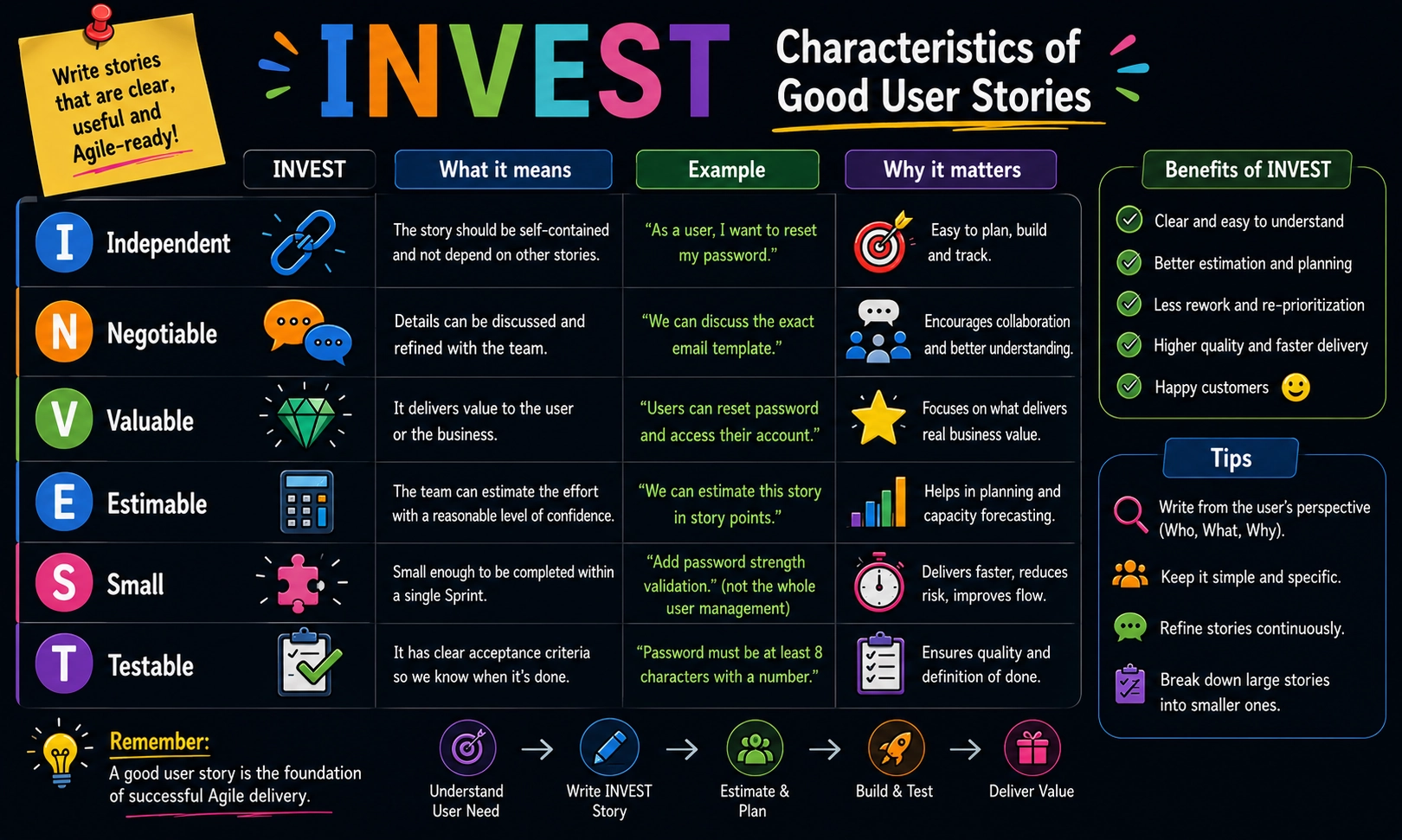
- Independent. The story doesn't depend on other stories. You complete it without waiting for another team or story to finish first.
- Negotiable. Details aren't fixed. You discuss the story with the team and the Product Owner. You adjust acceptance criteria based on what's feasible. The story is a conversation starter, not a contract.
- Valuable. The story delivers customer value. It's not internal work or a technical task. Users see and benefit from it.
- Estimable. The team understands the story well enough to estimate it. If you can't estimate, the story needs clarification or breakdown.
- Small. The story fits in one sprint. It takes a few days, not weeks. Small stories move faster and reduce risk.
- Testable. You write acceptance criteria that let you test the story. If you can't test it, you can't confirm it's done.
Stories that follow the INVEST move through sprints smoothly. They don't block other work. Teams finish them. They're clear enough that developers don't waste time guessing what to build.
Use INVEST to evaluate stories before pulling them into sprints. If a story fails any criterion, refine it or break it into smaller pieces.
❓ What makes a good user story?
It follows INVEST (Independent, Negotiable, Valuable, Estimable, Small, Testable). Has clear acceptance criteria. Written from the user's perspective. Small enough to complete in one sprint. Doesn't prescribe implementation. Generates a conversation between the dev team and the PO. Delivers value on its own, not only when combined with other stories.
❓ What are acceptance criteria?
Specific conditions that must be met for a story to be accepted as done. Written by the PO, often with input from dev. Commonly in Given/When/Then (BDD) format. They define the story's boundary, prevent scope creep, and enable test automation. Without acceptance criteria, "done" is subjective and leads to rework.
❓ How do Agile teams handle changing requirements?
Agile expects requirements to change. You build feedback loops into every sprint so customers can steer decisions early. In sprint reviews, you show working software. Customers use it and request changes. You adjust priorities for the next sprint.
This is fundamentally different from Waterfall, which treats changes as failures. Agile treats them as learning.
Managing Changes in a Sprint
If a critical change arrives mid-sprint, the Product Owner decides: pull a lower-priority story out and add the new work, or wait until next sprint. You don't just add work and expect the team to absorb it. You make trade-offs explicitly.
For non-critical changes, the Product Owner adds them to the backlog and prioritizes them for future sprints. The team finishes the current sprint without disruption.
Protecting Sprints
Protect sprint goals from constant interruptions. If every sprint gets derailed by urgent requests, the team loses momentum. Set a rule: mid-sprint changes only for true emergencies. Everything else waits for the next sprint.
The Scrum Master shields the team from scope creep. Stakeholders request features constantly. You push back politely and help them understand why mid-sprint changes hurt delivery.
The Balance
Agile thrives on change, but chaos kills productivity. Change regularly through sprint planning and review. Don't allow constant mid-sprint disruption. Small, regular adjustments beat large surprises.
❓ How do you prioritize backlog items?
By value delivered, risk reduced, dependency order, and cost of delay. Avoid: prioritizing by who asked loudest, by effort alone, or by date requested. The PO must make tough tradeoff decisions based on business impact, not stakeholder politics.
❓ Which prioritization techniques are you choosing for which situation?
In Agile, there are many prioritization frameworks/techniques; for example, we explain 17 prioritization frameworks.
Below are common situations and frameworks that can be used:
| Situation | Recommended Framework |
|---|---|
| Planning a release with mixed stakeholders | MoSCoW |
| Comparing product features with usage data | RICE |
| Scoring growth experiments quickly | ICE or PIE |
| Enterprise portfolio planning | WSJF or Weighted Scoring |
| Timing-sensitive business decisions | Cost of Delay |
| Visual workshop with a team | Value vs Effort Matrix |
| Personal or leadership workload planning | Eisenhower Matrix |
| Multi-criteria decisions with many stakeholders | Weighted Scoring Model |
| High-uncertainty technical projects | Risk-Based Prioritization |
| Customer satisfaction and emotional response | Kano Model |
| Finding underserved customer needs | Opportunity Scoring |
| Refactoring, reliability, security, or platform work | Technical Debt Prioritization |
| Architecture roadmap planning | Architecture Priority Model |
| Customer or stakeholder trade-off workshops | Buy a Feature |
| Large sets of ideas or research notes | Affinity Mapping |
| Outcome-driven product strategy | Jobs-to-be-Done Prioritization |
Kanban Interview Questions and Answers
❓ What is Kanban, and how does it differ from Scrum?
- Kanban visualizes work on a board with columns: To Do, In Progress, Done. Work flows continuously without fixed sprints. You pull tasks when you have capacity. There are no ceremonies or roles.
- Kanban has no sprints. Work arrives unpredictably and moves through your system continuously. Scrum batches work into sprints so you focus on the same goals for two weeks.
- Kanban limits work in progress. If three items are "In Progress," you finish one before starting another. This prevents context switching. Scrum commits to completing all sprint work by the deadline.
- Kanban changes priorities anytime. A critical bug arrives, and you pull it to the top. Scrum protects the sprint from mid-cycle changes. You handle urgent work outside the sprint or wait until the next sprint.
- Kanban works best for support teams, operations, or continuous delivery environments where work arrives unpredictably. Scrum works better for product teams building new features where you need structure and predictability.
❓ What is continuous delivery in Kanban?
Continuous delivery means shipping code to production multiple times per day. Work moves through your pipeline immediately without batching or waiting. Code finishes development, passes testing, and deploys automatically. Kanban enables this through work-in-progress limits. When a task finishes, it moves to the next stage right away. No bottlenecks. No queues.
You automate tests and deployments. Manual steps slow you down. Automated pipelines push code live within hours of completion.
Benefits: feedback arrives fast. Bugs get fixed the same day. Users get features immediately. Problems surface when they're cheap to fix.
This requires high test coverage and reliable deployments. Immature teams constantly disrupt production. Mature teams ship safely multiple times daily.
❓ What are WIP limits, and why are they important?
WIP (work in progress) limits the number of tasks your team works on simultaneously. If your limit is three items in progress, nobody starts new work until someone finishes and moves a task to done.
WIP limits force focus. Your team stops context switching. Developers finish tasks faster because they concentrate on fewer things. Throughput increases even though it looks like you're doing less.
Without limits, your board fills with half-finished work. Tasks sit for weeks. Dependencies pile up. Nothing ships.
Set limits based on team size. A five-person team might limit development to four items. Testing to three. This prevents bottlenecks and keeps work flowing smoothly.
Lower WIP limits reveal problems immediately. If work gets stuck, you see it. You unblock it instead of starting new work and ignoring the problem.
❓ What is cycle time?
The time from when work starts (team picks it up) to when it's done. Cycle time measures team execution speed and is the primary metric for forecasting how long new work will take. Lower and more consistent cycle time = more predictable delivery. Measured in days.
❓ What is lead time?
The time from when work is requested (enters the backlog) to when it's delivered. Lead time includes queue time before work starts, plus cycle time. From a customer perspective, lead time is what matters — it's the time between "I asked for this" and "I have this." Distinguishing lead time from cycle time reveals where work waits.
❓ What is throughput in Kanban?
The number of items completed per unit of time (e.g., 8 stories per week). Throughput is a flow metric useful for forecasting: if you consistently complete 8 items/week, you can estimate when a backlog of items will be completed. More reliable than velocity for capacity planning.
❓ What is flow efficiency?
The ratio of active work time to total lead time. If a ticket takes 10 days but is actively worked on for only 2 days, the flow efficiency is 20%. Most software teams have 15–40% flow efficiency — most of the time is spent waiting (in queues, blocked, awaiting review). Improving flow efficiency doesn't mean working faster, it means reducing wait time.
❓ What are bottlenecks, and how do you identify them?
A bottleneck is a stage where work accumulates faster than it can be processed, slowing the entire system. Identify them via CFD (wide bands in one stage), by observing where tickets pile up, or by measuring queue sizes at each step. Fix the bottleneck before optimizing anything upstream — otherwise, you just fill the queue faster.
❓ What metrics matter most in Kanban teams?
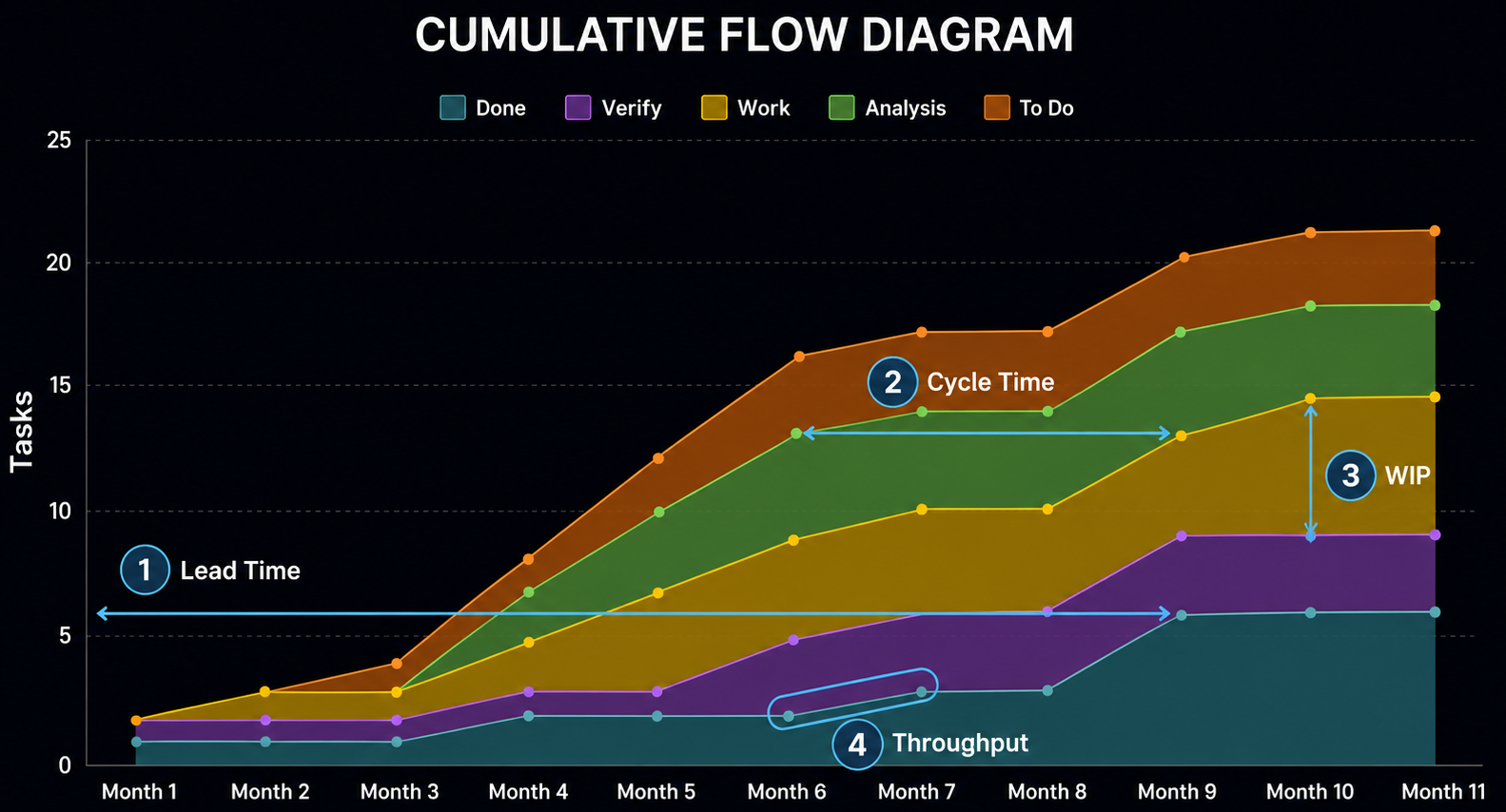
- Cycle time (how fast you execute)
- Lead time (how fast customers get value)
- Throughput (how much you deliver)
- WIP (are you overloaded?),
- Flow Efficiency (how much is wait vs. work).
❓ What anti-patterns exist in Kanban adoption?
- No WIP limits. Teams add limits to the board but ignore them. Work piles up everywhere. Context switching kills productivity. Enforce limits ruthlessly or remove them.
- Too many columns. Your board has fifteen stages: backlog, design, development, code review, testing, staging, deployment, and monitoring. Work gets lost in the pipeline. Simplify to five or six columns max.
- Ignoring bottlenecks. Testing always has ten items waiting. Development is empty. You see the problem but don't fix it. Add people to testing or reduce development WIP to match testing capacity.
- Treating Kanban like Scrum. You create two-week iterations and sprints. You plan at the start. This defeats Kanban's purpose. Kanban is continuous flow, not batched cycles.
- Never pulling from the backlog. Work sits in the backlog for months. Nobody prioritizes it. Stories become stale. Groom the backlog weekly. Pull the most valuable items to do next.
- Metrics obsession. You track lead time, throughput, and cycle time, but don't improve anything. Metrics reveal problems. Use them to identify bottlenecks and fix them.
- No visualization. Your Kanban board is cluttered. Cards lack context. Team members can't see what's happening. Keep the board clean. Write clear descriptions. Update it constantly.
- Ignoring dependencies. A story needs another team's work. You start it anyway. It blocks. Nothing moves. Identify dependencies upfront and coordinate with other teams.
Kanban works when you enforce limits, simplify the workflow, and fix bottlenecks. Without discipline, it becomes chaos.
Risk Management Interview Questions and Answers

❓ What is risk management in software projects?
Risk management identifies threats to your project and reduces their impact. Common risks include unclear requirements, technical complexity, team turnover, and tight deadlines.
- Start by listing risks. What could derail delivery? Missing key people. Technology failures. Scope creep. Dependency on external teams. Write them down.
- Assess each risk. How likely is it? What's the impact if it happens? High-probability, high-impact risks need immediate attention. Low probability risks you monitor but don't spend energy on.
- Create mitigation plans. For each major risk, decide how to prevent or reduce it. If key people leaving is a risk, cross-train the team and document decisions. If technology is untested, build a prototype early.
- Monitor risks continuously. In standups and retrospectives, ask if risks are changing. New risks emerge. Old risks disappear. Your risk list evolves throughout the project.
Agile teams manage risk better than Waterfall teams. Frequent delivery surfaces problems early. You adjust course before major damage occurs. Waterfall teams discover risks too late when fixes cost millions.
❓ What is the difference between risk, issue, blocker, and dependency?
- Risk: something that might happen and could cause harm, uncertain, future.
- Issue: something that has already happened and requires a certain action to be taken.
- Blocker: an issue that prevents progress on specific work right now.
- Dependency: a prerequisite, something that must exist or be done before your work can proceed. Managing each type requires different responses.
❓ What are the most common risks in software projects?
- Unclear requirements. Customers don't know what they want. Developers build the wrong thing. Rework costs time and money. Mitigate by involving customers early and showing working software often.
- Features keep getting added. The Product Owner prioritizes ruthlessly and says no frequently.
- Technical complexity
- Key people are leaving. Your best developer quits. Knowledge walks out the door. The team slows down. Cross-train people. Document decisions. Build a team, not a hero culture.
- Poor communication. Teams don't talk.
- Dependency on external teams.
- Technical debt.
- Insufficient testing.
❓ What is risk probability vs impact?
Probability: how likely is this risk to occur (low/medium/high or 1–5). Impact: How severe would the consequences be if it does occur? Both dimensions together determine priority. A high-probability, low-impact risk may need less attention than a low-probability, catastrophic-impact risk. Risk management is about prioritizing which risks deserve the most attention.
❓ What is a risk matrix?
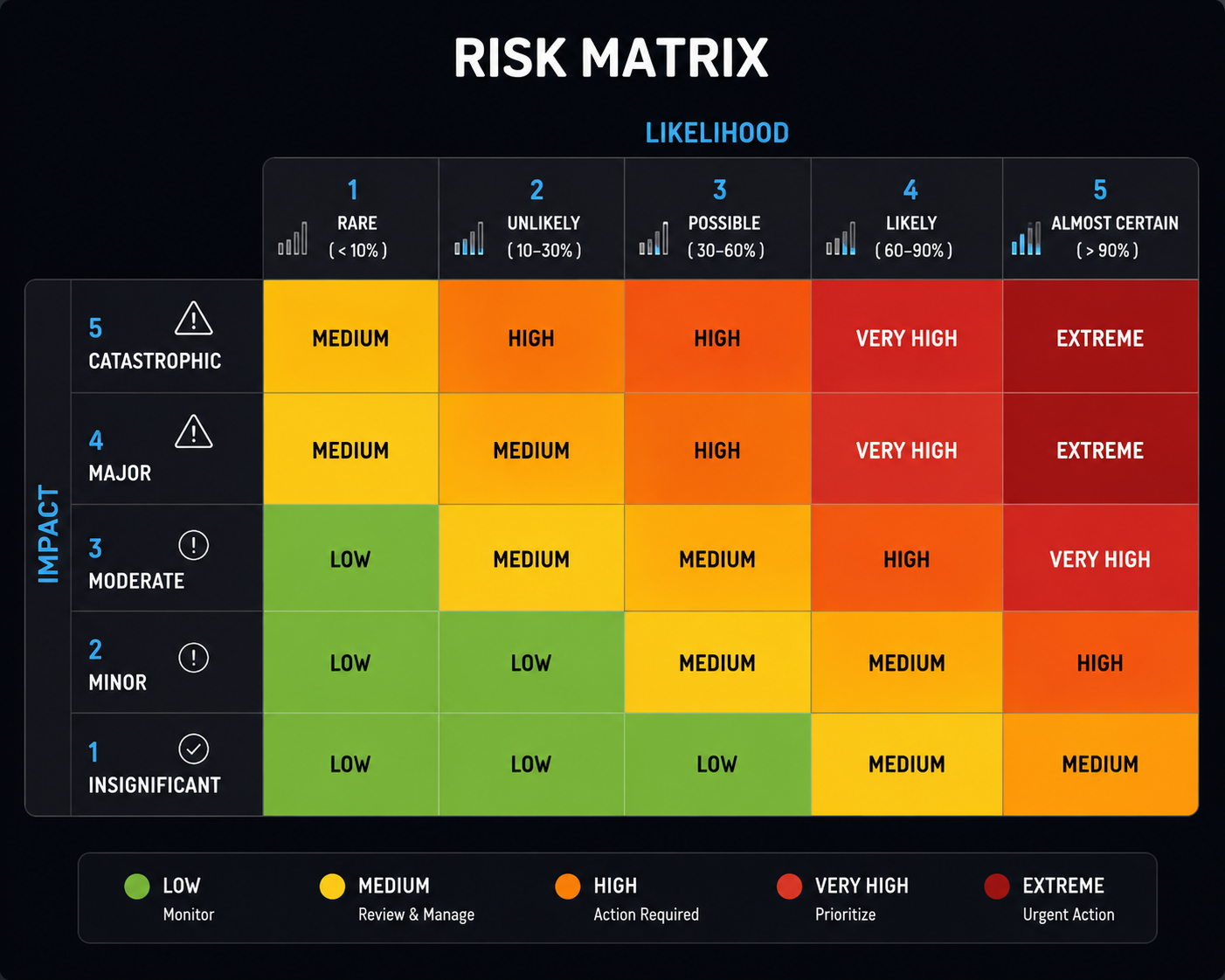
A risk matrix plots risks on a grid. One axis shows probability (low to high). The other shows impact (low to high). This creates four quadrants.
High probability, high-impact risks get immediate attention. You prevent them or have contingency plans ready. High-impact, low-probability risks you monitor but don't invest resources to prevent. Low-impact risks you accept and move on.
Create your matrix by listing all project risks. Estimate how likely each is and how much damage it would cause if it happened. Plot each risk on the grid.
Red zone (top right): act immediately. Green zone (bottom left): monitor, but don't worry. Yellow zone: assess and plan.
Update your matrix monthly. Risks change. New threats emerge. Old risks disappear. Your matrix evolves as the project progresses.
A risk matrix forces decisions. You can't treat all risks equally. You prioritize. You spend energy on what matters most.
❓ What is risk mitigation?
Actions taken to reduce the probability or impact of a risk before it occurs. Examples: writing automated tests mitigates deployment risk. Adding a second engineer to a critical area mitigates the bus factor. Using feature flags mitigates release risk. Mitigation is proactive — it's different from contingency planning, which kicks in after the risk materializes.
❓ What is risk acceptance?
A conscious decision to acknowledge a risk and take no action either because the cost of mitigation exceeds the potential impact, or the probability is acceptably low. Risk acceptance must be explicit and documented, not the result of ignoring the risk. Senior stakeholders should formally accept significant risks.
❓ What is contingency planning?
Defining in advance what you'll do if a risk materializes into an issue. "If the third-party API goes down, we'll switch to cached responses for 24 hours." Contingency planning ensures you're not improvising under pressure. It's part of risk response planning alongside mitigation and acceptance.
❓ What is residual risk?
The risk that remains after mitigation measures are applied. You rarely eliminate risk entirely — mitigation reduces it to an acceptable level. Understanding residual risk prevents overconfidence in mitigation plans. Example: automated tests reduce deployment risk, but residual risk remains (tests might not cover all cases).
❓ What is risk appetite in organizations?
Risk appetite is the level of risk your organization accepts to achieve its goals. A startup accepts high failure rates to find product-market fit. A bank accepts low failure rates because customers demand reliability.
Define your appetite explicitly. What risks will you take? What will you avoid? How much budget loss do you accept on failed projects? This clarity guides team decisions.
Misaligned appetite breaks projects. Teams want to ship fast. Leadership demands zero defects. The team cuts corners. Leadership panics. Trust collapses.
Document appetite by risk type. Technical risk (new frameworks). Market risk (new markets). Financial risk (budget overruns). Team risk (losing people). Each has a different tolerance.
Teams use appetite to decide what to build. High technical appetite means trying new technology. Low appetite means proven tools. Your appetite shapes engineering choices.
❓ How do you identify architectural risks early?
Architecture Decision Records (ADRs) to document and review decisions. Threat modeling sessions. Load testing before production. Proof of concepts for uncertain integrations. Review of Non-Functional Requirements (NFRs) early. Involve senior engineers in design reviews. Ask "what happens when X fails?" for every external dependency.
❓ What delivery risks appear in Agile projects?
Sprint scope creep. An incomplete definition of Done leads to hidden work. Weak backlog with unready stories. Team velocity is disrupted by unplanned work. External dependencies not tracked. Product Owner's unavailability blocks decisions. Retrospective findings were never acted on. Accumulating technical debt is slowing the team.
❓ What risks appear during cloud migration projects?
Underestimated data migration complexity. Performance regression due to network latency vs. on-prem. Cost overruns from misunderstood cloud pricing. Vendor lock-in. Security misconfigurations. IAM complexity. Compliance and data residency issues. Downtime during cutover. Application assumptions about the local filesystem or state.
❓ What risks appear in microservices adoption?
Distributed system complexity is replacing simpler monolith problems. Service proliferation without governance. Inconsistent deployment and monitoring standards. Data ownership confusion. Cross-service transaction management. Network overhead. Team ownership boundaries unclear. Testing complexity (contract tests, integration tests). Premature decomposition before the domain is understood.
❓ What risks appear in AI and LLM projects?
Non-deterministic outputs make testing difficult. Hallucination in production systems. Prompt injection attacks. Model performance degradation with distribution shift. High inference costs at scale. Regulatory uncertainty around AI use. Vendor dependency on model providers. Latency from model calls. Data privacy risks if user data is sent to third-party APIs. Alignment between LLM behavior and product expectations.
❓ How do dependencies between teams create delivery risks?
Shared APIs not ready on time. API contract changes are breaking consumers. Priority misalignment between teams. Different release cadences create integration windows. Unclear ownership of shared components. Teams blocked waiting on each other without visibility into status. Inter-team dependencies are a leading cause of enterprise Agile delivery failure.
❓ What risks appear from poor requirements quality?
Teams build the wrong thing. Rework discovered late (expensive). Misaligned stakeholder expectations. QA cannot write tests without clear acceptance criteria. Scope creep when requirements are vague. Disagreements about what "done" looks like. Poor requirements quality multiplies cost — the later the discovery, the more expensive the fix.
❓ What risks appear from weak observability and monitoring?
Incidents go undetected until users report them. MTTR increases dramatically when you can't diagnose without access to logs. Silent data corruption. Capacity issues were not caught before saturation. Performance regressions are invisible until it's too late. Inability to validate that deployments actually improved the system. Dark launches with no feedback loop.
❓ How do you reduce deployment risks in production systems?
Feature flags for gradual rollout. Blue-green or canary deployments. Automated rollback triggers. Comprehensive pre-deploy test suites. Deployment during low-traffic windows. Monitoring dashboards are reviewed post-deploy. Small, frequent deployments instead of large infrequent ones. Database migrations decoupled from application deployments.
❓ What risks appear in remote or distributed teams?
Communication delays slowing decisions. Timezone gaps are creating async bottlenecks. Misalignment due to a lack of informal communication. Reduced psychological safety in written-only communication. Unequal participation in remote meetings. Knowledge siloing without physical co-location. Collaboration tool fragmentation.
❓ What risks appear when scaling engineering teams?
Coordination overhead grows super-linearly. Knowledge concentration in the founding team members. Inconsistent engineering standards across teams. Architectural decisions not keeping pace with team growth. Onboarding gaps for new engineers. Communication channels are breaking down.
Conway’s Law states that software systems reflect the communication structure of the organization that builds them.
❓ How does poor communication create delivery risks?
Requirements misunderstood. Blockers not raised early. Decisions are made in silos without the affected parties. Stakeholders are surprised at the sprint review. Inter-team dependencies are uncoordinated. Post-incident learning is not shared. Poor communication is the root cause behind most "technical" delivery failures when investigated deeply.
❓ What is bus factor risk?
The number of team members who could leave (get "hit by a bus") before the team loses critical knowledge or capability. A bus factor of 1 means the entire system depends on one person — extremely high risk. Mitigation: documentation, pair programming, code reviews, cross-training, and avoiding knowledge silos.
❓ What risks appear from key-person dependency?
A single person owns critical system knowledge. Their absence (vacation, illness, attrition) causes delivery to stop. Risk escalates as systems grow without knowledge transfer. Mitigation: runbooks, pair programming, shared oncall, documentation, and explicit team norms against hero culture.
❓ What risks appear from unrealistic deadlines?
Quality shortcuts taken to meet dates. Technical debt accelerates. Team burnout and attrition. The scope was quietly cut without stakeholder awareness. False confidence in delivery estimates. Testing compressed or skipped. Regulatory or compliance steps skipped. The delivery happens on time, but the product fails in production.
❓ How do organizational politics affect project risks?
Prioritization driven by stakeholder influence rather than value. Critical risks were not raised because it's "career-limiting" to deliver bad news. Budget and resource decisions disconnected from technical reality. Teams are competing instead of collaborating. Architecture decisions made to satisfy politics, not engineering needs. Leadership not surfacing real delivery risks to executives.
❓ How do you communicate risks to leadership?
Use business language: impact on timeline, cost, user experience, or compliance, not technical detail. Be specific: "This dependency on Team X puts our Q3 launch at risk unless we align by June 1." Offer options with trade-offs. Be proactive in surface risks before they become issues. Maintain a risk register that leadership can review. Never bury bad news.
❓ What makes risk reporting ineffective?
Risks are listed as vague technical concerns that leadership can't act on. The status is always Green when the reality is Yellow or Red. Reports produced but never reviewed. No owners assigned to risks. Risks not updated as situations change. No connection to business impact. Risk registers as bureaucratic checkboxes rather than live management tools.
❓ How do experienced architects think about risks differently from junior engineers?
Juniors see technical risks in isolation. Architects see systemic risks — how one failure cascades, how org decisions create technical risk, and how today's shortcuts create tomorrow's incidents. Architects proactively identify risks before being asked. They communicate risks in business terms, not just technical terms. They accept that risk is inevitable and design systems to fail gracefully rather than trying to prevent all failure.
Agile Scaling & Enterprise Delivery
❓ What challenges appear when scaling Agile across multiple teams?
- Coordination overhead. Ten teams run independent sprints. They build features that conflict. Integration breaks. You need synchronization points. Daily standups across teams create meeting bloat.
- Dependency hell. Team A needs Team B's API. Team B prioritizes differently. Team A blocks. Dependencies paralyze progress. You spend more time waiting than building.
- Inconsistent practices. One team uses two-week sprints. Another uses three weeks. One team estimates in points. Another hour. Comparing velocity becomes meaningless. Handoffs between teams cause friction.
- Product Owner bottleneck. One Product Owner can't prioritize work for ten teams. Priorities conflict. Teams wait for decisions. You need multiple Product Owners. They must align on the roadmap.
- Communication breaks. Large organizations have silos. Teams don't talk. Knowledge doesn't flow. You duplicate work.
- Scaling the framework's complexity. SAFe, LeSS, and other scaling frameworks add ceremony. Planning at multiple levels. Quarterly planning. Program increment planning. Overhead grows faster than productivity.
- Cultural resistance. Legacy organizations fight Agile. Some teams adopt it. Others resist. You get a hybrid mess. People blame Agile for problems caused by poor execution.
- Metrics lose meaning. Velocity varies by team. You compare teams and create competition. Teams game metrics. Retrospectives become pointless.
❓ What is SAFe?
SAFe (Scaled Agile Framework) coordinates multiple Agile teams working on large products. It adds structure above Scrum to align teams, manage dependencies, and synchronize delivery across the organization.
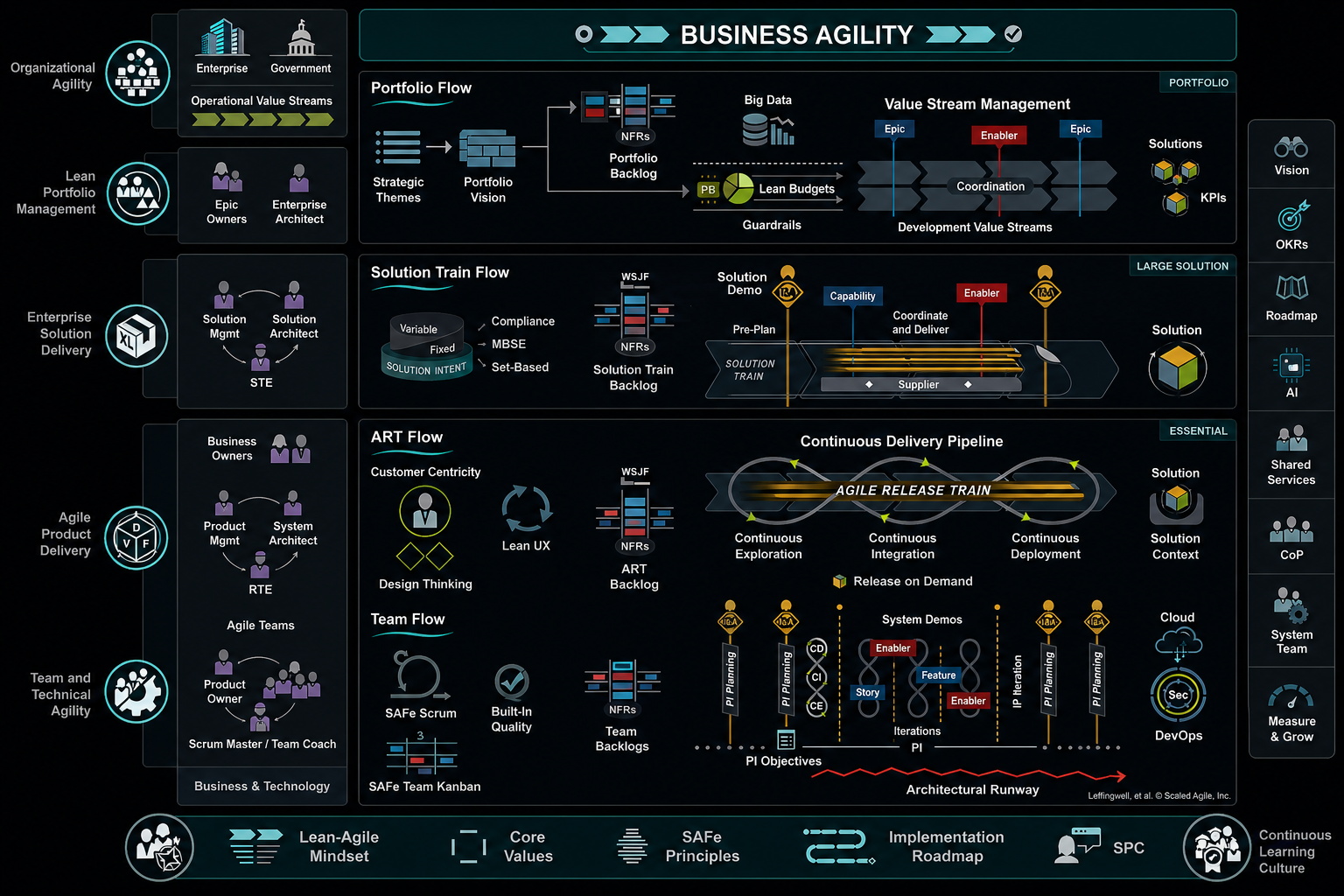
SAFe runs on a Program Increment (PI). A PI is an eight-week planning cycle that coordinates all teams. Teams plan together at the start. They execute for eight weeks. They demo and retrospect at the end.
Key roles include the Release Train Engineer (like a Scrum Master at scale), the Product Manager (who owns the roadmap), and the System Architect (who ensures technical coherence across teams).
SAFe works for large enterprises with many teams building connected products. It reduces chaos when ten teams need to coordinate. It provides cadence and visibility.
The downside: SAFe adds meetings and ceremonies. Planning takes weeks. Multiple layers of governance slow down decisions. Some teams feel constrained by forced synchronization.
Use SAFe if you have five or more teams working on related products. Smaller organizations get bogged down in overhead. Stable, mature organizations benefit. Startups waste energy on process.
❓ What is Scrum of Scrums?
Scrum of Scrums coordinates multiple Scrum teams working on related products. One representative from each team attends a Scrum of Scrums meeting. They discuss dependencies, blockers, and integration points.
The meeting happens weekly or twice weekly. Each representative answers three questions: What did your team complete? What will your team do next? What blocks your team or blocks other teams?
This structure scales Scrum beyond one team. Ten teams can't all attend the same standup. Representatives sync their work at a higher level.
Representatives go back to their teams and share what they learned. Dependencies surface early. Integration issues get caught before they become crises.
The downside: communication gets filtered. Information passes through intermediaries. Details get lost. Decisions slow down because everything must be escalated and explained.
Use Scrum of Scrums for three to ten teams. Beyond ten teams, you need SAFe or LeSS. With only two teams, direct communication works better.
❓ What coordination problems appear in large Agile organizations?
Teams with misaligned priorities. Dependencies not surfaced until they become blockers. Integration work is underestimated. No single owner of cross-team technical decisions. Competing roadmaps. Shared infrastructure teams are becoming bottlenecks. Governance and compliance processes incompatible with sprint cadences.
❓ What is dependency management between Agile teams?
The practice of identifying, tracking, and resolving work that one team needs from another. Tools: dependency boards, inter-team backlog items, shared planning sessions (PI Planning in SAFe). The goal is to make dependencies visible early so teams can coordinate without last-minute surprises. Unmanaged dependencies are a top cause of late delivery in multi-team programs.
❓ What is release train planning?
A planning event (e.g., PI Planning in SAFe) where multiple teams align on goals, identify dependencies, and plan delivery for the next program increment (typically 8–12 weeks). Creates shared commitment across teams. Reduces integration surprises. Criticized for being heavyweight and difficult to adjust mid-increment.
❓ Why do enterprise Agile transformations often fail?
Agile was imposed top-down without input from the team. Ceremonies adopted without a mindset change. Management retains command-and-control. No investment in engineering practices (CI/CD, test automation). Frameworks chosen for size, not fit. Teams not empowered to make decisions. Success is measured by "adoption," not outcomes. Consultants leave, and nothing sustains.
❓ What is "Agile theater"?
Performing the motions of Agile (standups, sprints, retrospectives) without the underlying values or benefits. Teams hold standups where nobody raises real blockers. Retrospectives where nothing is safe to say. Sprint planning that's actually a commitment to a pre-decided scope. Story points gamed for velocity KPIs. The form exists; the substance doesn't.
❓ How do you keep Agile lightweight in enterprise environments?
Start with principles, not frameworks. Add process only when a problem requires it. Protect teams from governance overhead. Push decisions down to teams where possible. Measure outcomes not ceremony compliance. Have senior leaders actively remove bureaucratic impediments. Favor direct communication over status report chains.
❓ What is the difference between being Agile and doing Agile?
Doing Agile: following the ceremonies, roles, and artifacts. Being Agile: embodying the values — welcoming change, collaborating with customers, trusting teams, delivering continuously. A team can do every Scrum ceremony perfectly and still not be Agile. A team can skip ceremonies and be deeply Agile. Mindset and culture are the substance; ceremonies are just tools.
Agile Engineering Practices Interview Questions and Answers
❓ Why are CI/CD practices critical for Agile delivery?
Agile requires frequent delivery of working software. Without CI/CD, integration happens manually and rarely, leading to large, risky releases. CI (Continuous Integration) ensures code merges frequently and is always buildable. CD (Continuous Delivery/Deployment) ensures every change can be shipped safely. CI/CD is the engineering foundation that makes short sprints meaningful.
❓ What is trunk-based development?
Trunk-based development means all developers commit code to a single main branch (trunk or main). You don't use long-lived feature branches. You commit multiple times daily.
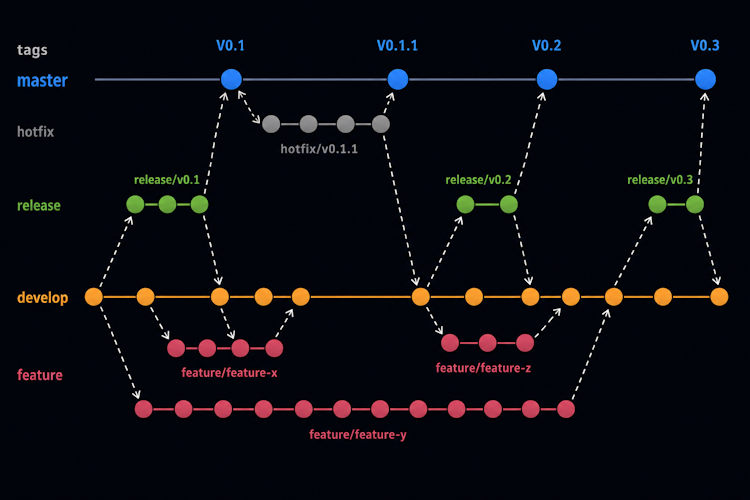
Developers pull the latest code before starting work. They commit their changes within hours. If conflicts arise, you resolve them immediately. The trunk stays deployable at all times.
This requires discipline. You write small, focused commits. You test locally before committing. You use feature flags to hide incomplete work. Code reviews happen fast, so trunk doesn't get blocked.
Benefits: integration happens constantly. You catch conflicts early when they're cheap to fix. The trunk is always production-ready. You deploy anytime without waiting for branch merges.
Downside: broken code sometimes reaches the trunk. You need fast automated tests to catch problems immediately. You need a team that cares about code quality and commits frequently.
Trunk-based development works for teams shipping continuously. Feature branches work for slower release cycles where you batch work. Choose based on your deployment frequency.
❓ What is feature flagging?
Feature flagging hides incomplete features behind a toggle. Code ships to production but stays off for users. You flip the flag when the feature is ready.
Developers commit unfinished work to the trunk. Feature flags prevent users from seeing it. Testing teams test the hidden feature in production. When quality is good, you enable the flag for all users.
Benefits: You deploy continuously without waiting for features to finish. You test in production with real data. You roll out features gradually to catch problems early. You can roll back instantly by disabling the flag.
Example: you build a new search algorithm. It ships behind a flag disabled for all users. You enable it for 10 percent of users. Monitor performance. Enable it for 50 percent. Then 100 percent. If something breaks, disable the flag immediately.
Feature flags require discipline. Too many flags clutter the code. Old flags never get cleaned up. You end up maintaining code nobody uses.
Use feature flags for continuous deployment. They let you ship incomplete work safely. You separate deployment from release. Deploy code anytime. Release features when ready.
❓ Why do long-lived branches hurt Agile teams?
They delay integration, hiding merge conflicts that compound over time. They prevent CI — code isn't integrated until the branch is merged. They create a false sense of progress (the branch is "done" but untested against the main). They make deployments riskier with larger changesets. Long-lived branches are a symptom of infrequent integration and slow deployment pipelines.
❓ What engineering anti-patterns slow Agile teams down?
- Poor code quality. Developers skip testing. Code review is shallow. Technical debt accumulates. Each new feature takes longer because developers navigate messy code. Fix it by enforcing code standards and paying down debt continuously.
- Manual testing. QA manually tests every feature. Testing takes weeks. Deployment waits. Automate tests. Run them on every commit. Shift testing left so developers test before code review.
- Long-lived feature branches. Developers work on separate branches for weeks. Integration becomes painful. Conflicts multiply. Merge hell ensues. Use trunk-based development. Commit to the main daily. Use feature flags to hide incomplete work.
- Slow deployments. Deployment takes hours. You need a special person to deploy. The process is manual and error-prone. Automate deployments. The deployment should take minutes. Any developer should be able to deploy without special access.
- Missing monitoring. Code ships without visibility into what users experience. Bugs reach production. You discover problems from angry customers. Add logging. Track errors. Monitor performance. Alert on problems immediately.
- Inconsistent environments. Development works locally. Staging works. Production breaks. Environments differ. Use containers and infrastructure as code. Dev, staging, and production are identical.
- Weak code review. Reviewers rubber-stamp changes. Bad code merges. Standards decay. Set clear expectations. Reviewers should understand the code before approving. Comments should be specific and constructive.
- No documentation. Code has no comments. Architecture decisions are unrecorded. New developers waste time reverse-engineering the system. Document decisions and complex logic. Keep documentation updated.
- Heroic efforts. Teams work nights and weekends to meet deadlines. Burnout accelerates. Quality drops. People leave. Work sustainable hours. If you need heroes regularly, something is broken with planning or scope.
Fix these patterns, or Agile fails. Process improvements matter less than engineering discipline.
❓ How do architecture decisions affect Agile delivery speed?
Good architecture enables independent deployment of components — teams can ship without coordinating with other teams. Poor architecture creates tight coupling; every change requires multi-team coordination and big-bang releases. Monoliths can be Agile-friendly early on; tightly coupled distributed systems can be worse than a monolith. Architecture should minimize the surface area of coordination needed between teams.
📖 Future reading
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI