C# Collections Interview Questions and Answers (2026) – Arrays, Lists, Dictionaries & More

Welcome to the our .NET Interview Questions and Answers series exploring the ins and outs of C# and .NET! This Chapter covers data structures in .NET, their collections and implementations, and their performance characteristics.
The Answers are split into sections: What 👼 Junior, 🎓 Middle, and 👑 Senior .NET engineers should know about a particular topic.
Also, please take a look at other articles in series: C# / .NET Interview Questions and Answers
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum
Big O notation
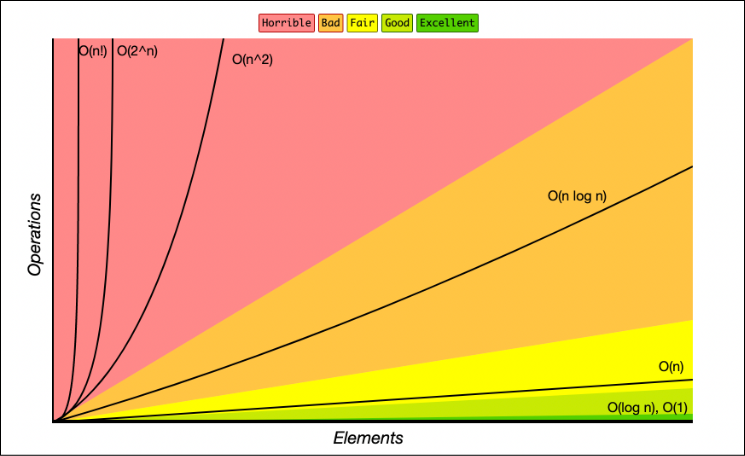
❓ What Is Big O Notation, and Why Is It Important in C# Collections?
Big O Notation is a mathematical concept used to describe the efficiency of algorithms, particularly in terms of time and space complexity. It provides a high-level understanding of how an algorithm's performance scales with the size of the input data.
Below is a table with common data structures and their speed:
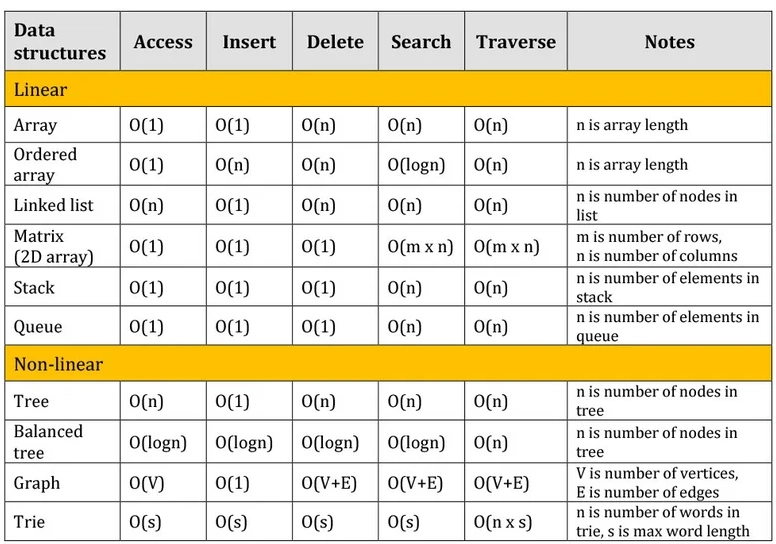
What .NET Engineers Should Know
- 👼 Junior: Recognize basic complexities like O(1), O(n), O(log n), and O(n²). Understand that different collections have different performance characteristics.
- 🎓 Middle: Choose appropriate data structures based on performance needs.
- 👑 Senior: Design systems with scalability in mind, considering algorithmic complexity. Mentor others in writing efficient, performant code.
📚 Resources
- Collections in .NET Through the Lens of Big O Notation
- Big-O notation, Time and Space Complexity
- Big-O Cheat Sheet
- 📹 Introduction to Big O Notation and Time Complexity (Data Structures & Algorithms #7)
❓ Can you explain and compare the efficiency of .NET collections?
| Collection | Description | Insert Time | Delete Time | Search Time | Sorted | Index Access |
|---|---|---|---|---|---|---|
| List<T> | Dynamic array with auto-resizing | O(1)* | O(n) | O(n) | ❌ | ✅ |
| LinkedList<T> | Doubly linked list | O(1) | O(1)* | O(n) | ❌ | ❌ |
| Dictionary<K;V> | Hash table | O(1)* | O(1) | O(1)* | ❌ | ❌ |
| HashSet<T> | Hash table for unique items | O(1) | O(1) | O(1) | ❌ | ❌ |
| Queue<T> | FIFO queue using circular array | O(1)* | O(1) | - | ❌ | ❌ |
| Stack<T> | LIFO stack using array | O(1)* | O(1) | - | ❌ | ❌ |
| SortedDictionary<K;V> | Sorted key-value pairs using red-black tree | O(log n) | O(log n) | O(log n) | ✅ By keys | ❌ |
| SortedList<K;V> | Sorted dynamic array | O(n)** | O(n) | O(log n) | ✅ By keys | ✅ |
| SortedSet<T> | Sorted unique items using red-black tree | O(log n) | O(log n) | O(log n) | ✅ By keys | ❌ |
| ConcurrentDictionary<K;V> | Thread-safe dictionary for concurrent access | O(1) | O(1) | O(1) | ❌ | ❌ |
| BlockingCollection<T> | Thread-safe producer-consumer queue | O(1) | O(1) | - | ❌ | ❌ |
| ImmutableList<T> | Immutable list | any change returns a new copy | O(log n)* | O(log n)* | ❌ only lookup that cost O(n) | ❌ |
| ImmutableDictionary<K;V> | Immutable dictionary | O(log n) | O(log n) | O(log n) | By keys | ❌ |
| ObservableCollection<T> | Notifies UI on collection changes | O(1) | O(1) | O(n) | ❌ | ✅ |
| ReadOnlyCollection<T> | Read-only wrapper for another collection | N/A | N/A | O(n) | ❌ | ✅ |
* - Amortized complexity — usually fast, but occasionally slower (e.g., resize in List<T>)
** - Insert may require shifting elements — performance degrades with size.
What .NET Engineers Should Know
- 👼 Junior: Familiar with
List<T>,Dictionary<TKey, TValue>, andHashSet<T>. Know thatList<T>has O(n) lookup time, whileDictionaryandHashSetoffer O(1) lookups. - 🎓 Middle: Choose collections that align with your performance needs. E.g., for frequent lookups, prefer
DictionaryorHashSet.UseSortedListorSortedDictionarywhen data needs to be sorted by keys. UsingConcurrentDictionaryin multi-threaded environments to avoid race conditions - 👑 Senior: Leverage specialized collections like
ConcurrentBag<T>,BlockingCollection<T>, or immutable collections for specific scenarios.
📚 Resources: Algorithmic complexity of collections
Arrays and Strings

This section covers arrays, their variants, and string handling, focusing on memory efficiency and collection contexts.
❓ Explain the difference between a one-dimensional and a multidimensional array in C#
In C#, arrays can be categorized based on their dimensions:
One-Dimensional Array
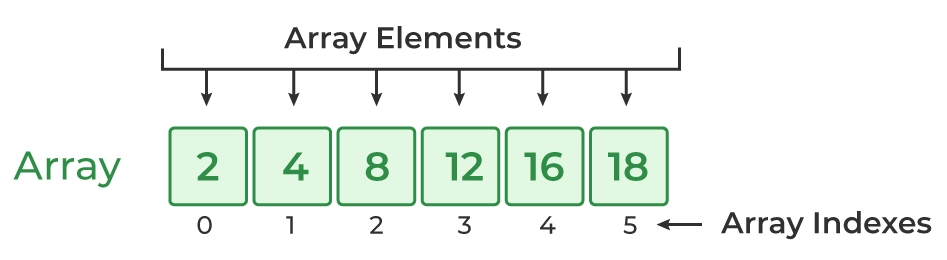
Also known as a single-dimensional array, it represents a linear collection of elements accessed using a single index.
int[] oneDimensionalArray = new int[5]; // Array of 5 integersMultidimensional Array

Represents a table-like structure with multiple dimensions, such as rows and columns. The most common form is the two-dimensional array.
int[,] twoDimensionalArray = new int[3, 4]; // 3 rows and 4 columnsIn a two-dimensional array, elements are accessed using two indices:
twoDimensionalArray[0, 0] = 1; // Sets the element at first row, first columnWhat .NET engineers should know:
- 👼 Junior: Understanding Array Basics.
- 🎓 Middle / 👑 Senior:
- Understand the memory layout and performance implications of using multidimensional arrays.
- Know jagged arrays (arrays of arrays) and their use cases compared to multidimensional arrays.
📚 Resources: Arrays in C#
❓ What are Inline Arrays in C# 12, and what advantages do they offer?
C# 12.0 enables us to define data types that support array syntax but work like normal value types in that they don't need to have their own dedicated heap objects. We can use inline array types as local variables or fields, enabling more efficient memory usage than might be possible with ordinary arrays.
[InlineArray(3)]
public struct ThreeFloats
{
private float element;
}
public struct Vector3
{
private ThreeFloats xyz;
public Vector3(float x, float y, float z)
{
xyz[0] = x;
xyz[1] = y;
xyz[2] = z;
}
public float X
{
get => xyz[0];
// In general, mutable structs are a bad idea, but the real
// Vector3 is mutable, so this example follows suit.
set => xyz[0] = value;
}
}📚 Resources C# 12.0: inline arrays
❓ What is the difference between jagged and multidimensional arrays in C#?
In C#, arrays can be structured in two primary ways: jagged and multidimensional. Understanding their differences is crucial for selecting the appropriate data structure for your application.
Jagged Arrays (int[][])
A jagged array is an array of arrays, allowing each sub-array to have a different length. This structure provides flexibility, especially when dealing with data that naturally varies in size.
Example:
int[][] jaggedArray = new int[3][];
jaggedArray[0] = new int[] { 1, 2 };
jaggedArray[1] = new int[] { 3, 4, 5 };
jaggedArray[2] = new int[] { 6 };This example jaggedArray has three sub-arrays with lengths 2, 3, and 1, respectively.
🧱 Multidimensional Arrays (int[,])
A multidimensional array, often referred to as a rectangular array, has a fixed number of rows and columns. All rows and columns are of equal length, forming a consistent grid-like structure.
Example:
int[,] multiArray = new int[3, 2]
{
{ 1, 2 },
{ 3, 4 },
{ 5, 6 }
};What .NET Engineers Should Know:
👼 Junior:
- Jagged: Understand that they are arrays of arrays, allowing for rows of varying lengths.
- Multidimensional: Recognize that they represent a fixed grid structure with equal-sized rows and columns.
🎓 Middle:
- Jagged: Utilize them when dealing with data structures with varying lengths, such as rows with different numbers of elements.
- Multidimensional: Apply them in scenarios requiring a consistent grid, like representing a chessboard or a matrix.
👑 Senior:
- Jagged: Optimize memory usage and performance by choosing jagged arrays for sparse or irregular data. Due to better cache utilization, they can be more memory-efficient and faster.
- Multidimensional: Be aware of the potential performance implications due to their contiguous memory allocation and the need for additional calculations during element access.
📚 Resources
❓ What is ArrayPool<T> in C#, and how does it optimize array memory usage?
ArrayPool<T> is a high-performance, thread-safe mechanism introduced in .NET Core to minimize heap allocations by reusing arrays. It’s especially beneficial in scenarios involving frequent, short-lived array allocations, such as processing large data streams or handling numerous requests in web applications.
Example:
Instead of allocating a new array, you rent one from the pool:
var pool = ArrayPool<byte>.Shared;
byte[] buffer = pool.Rent(1024);After usage, return the array to the pool to make it available for reuse
pool.Return(buffer);Performance Benefits:
- Reduces garbage collection (GC) pressure by reusing arrays.
- Minimizes memory fragmentation.
- Improves application throughput in high-load scenarios
What .NET Engineers Should Know:
- 👼 Junior: Understand the basic usage of
ArrayPool<T>for renting and returning arrays. - 🎓 Middle: Implement
ArrayPool<T>in performance-critical sections to reduce GC overhead. - 👑 Senior: Design systems that leverage custom
ArrayPool<T>instances with tailored configurations for optimal memory management.
📚 Resources
- Memory Optimization With ArrayPool in C#
- Advanced C# Tips: Utilize ArrayPool for Frequent Array Allocations
❓ What is array covariance in C#, and its potential pitfalls?
Array covariance in C# allows an array of a derived type to be assigned to an array of its base type. For example:
string[] strings = new string[10];
object[] objects = strings; // Valid due to covarianceWhile this feature provides flexibility, it introduces potential issues:
- Assigning an incompatible type to a covariant array can lead to
ArrayTypeMismatchException
object[] objects = new string[10];
objects[0] = 42; // Throws ArrayTypeMismatch
Exception at runtime- Each write operation includes a runtime type check, which can degrade performance.
- The compiler cannot catch certain type mismatches at compile time, leading to potential bugs.
What .NET Engineers Should Know
- 👼 Junior: Recognize that arrays are covariant and understand the fundamental implications.
- 🎓 Middle: Be cautious when assigning arrays of derived types to base type references; prefer using generic collections like
List<T>for type safety. - 👑 Senior: Design APIs that avoid exposing covariant arrays; use interfaces like
IEnumerable<T>to ensure type safety and flexibility.
❓ Why are strings immutable in C#, and what are the implications for collections?
In C#, string is immutable, meaning its value cannot be changed once created. Every operation like Replace(), ToUpper(), or Substring() Returns a new string, not a modified one.
Strings are immutable due to the following reasons:
- Safe to share between threads.
- Immutable strings have stable hash codes, making them ideal for dictionaries.
- Enables efficient memory use for duplicate strings.
What .NET Engineers Should Know:
- 👼 Junior: Know that
stringis immutable; modifying it returns a new instance. - 🎓 Middle: Use
StringBuilderin performance-critical string operations. - 👑 Senior: Understand memory and GC overhead from excessive string allocations in collections or APIs.
📚 Resources:
Understanding String Immutability in C#
❓ What is the difference between String and StringBuilder in C#?
In C#, String is immutable, meaning any modification creates a new instance, which can be inefficient for frequent changes. StringBuilder is mutable, designed for scenarios requiring numerous modifications to the string content, offering better performance by minimizing memory allocations.
// Using String
string text = "Hello";
text += " World"; // Creates a new string instance
// Using StringBuilder
StringBuilder sb = new StringBuilder("Hello");
sb.Append(" World"); // Modifies the existing instanceWhat .NET engineers should know:
- 👼 Junior: Should understand that
Stringis immutable, whileStringBuilderallows for efficient modifications. - 🎓 Middle: Expected to understand when to use
StringversusStringBuilderbased on performance considerations, especially in loops or extensive concatenation operations. - 👑 Senior: Should be able to analyze and optimize code by choosing between String and StringBuilder, considering factors like memory usage, execution speed, and code readability.
📚 Resources: String and StringBuilder in C#
❓ What is string interning in C#, and when should you use String.Intern()?
String.Intern() stores only one copy of each unique string literal in memory. If two strings have duplicate content, they can share the same reference, reducing memory usage.
string s1 = String.Intern(new string("hello".ToCharArray()));
string s2 = "hello";
Console.WriteLine(object.ReferenceEquals(s1, s2)); // TrueWhen to use String.Intern():
- When you have many repeated strings (e.g., config keys, tokens).
- In memory-critical applications, reducing duplicate strings matters.
⚠️ Avoid overusing it — interned strings stay in memory for the app's lifetime, which could increase memory pressure if misused.
What .NET Engineers Should Know:
- 👼 Junior: Understand that string literals may share memory via interning.
- 🎓 Middle: Use
String.Intern()to optimize memory for repetitive strings. - 👑 Senior: Know the intern pool's lifetime and analyze memory trade-offs carefully in large-scale systems.
Lists and Linked Lists
❓ What are the differences between List<T> and arrays in C#?
In C#, both List<T> and arrays (T[]) are used to store collections of elements. While they share similarities, they have distinct characteristics that make them suitable for different scenarios:
| Feature | List<T> - Dynamic size collection | Array (T[]) - A Fixed-Size Collection |
|---|---|---|
| Size | Dynamic | Fixed |
| Performance | Slightly slower due to overhead | Faster due to contiguous memory |
| Memory Allocation | Allocates more memory to accommodate growth | Allocates exact memory needed |
| Methods Available | Extensive (Add, Remove, Find, etc.) | Limited (Length, GetValue, SetValue) |
| Use Case | When collection size varies | When collection size is constant |
What .NET Engineers Should Know about Arrays and Lists
- 👼 Junior: Understand: The basic differences between
List<T>and arrays. - 🎓 Middle: Recognize that arrays perform better for fixed-size collections due to contiguous memory allocation.
- 👑 Senior: Make informed decisions about data structures based on application requirements, considering factors like collection size, performance, and memory usage.
📚 Resources: C# Array vs List: Differences & Performance
❓ What is LinkedList<T>, and how does it differ from List<T>?
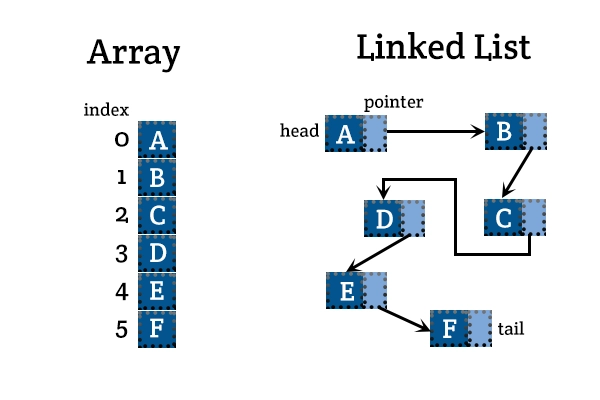
LinkedList<T> is a doubly linked list where each element points to the next and previous elements. In contrast, List<T> is a dynamic array that stores elements contiguously in memory.
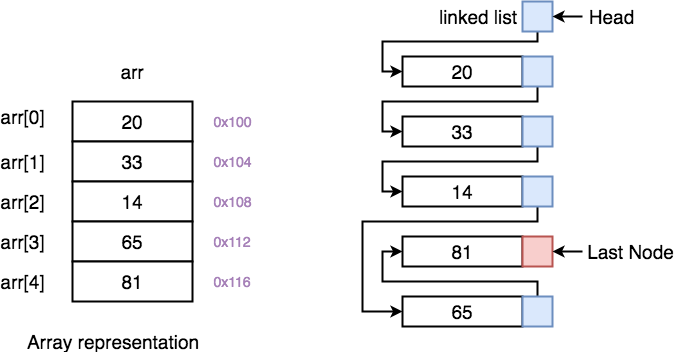
List<T> vs LinkedList<T> comparison:
| Feature | List<T> (Array) | LinkedList<T> (Nodes) |
|---|---|---|
| Access speed | Fast (O(1) index access) | Slow (O(n) to find item) |
| Insert/remove in middle | Slow (O(n) shift needed) | Fast (O(1) with reference) |
| Memory overhead | Lower | Higher (extra pointers) |
❓ When would you choose LinkedList<T> over List<T> based on performance?
Use LinkedList<T> when:
- Frequent insertions/deletions in the middle or ends are needed (
O(1)If you have a reference. - Constant-time additions to the start (
AddFirst) or removal without shifting elements.
Avoid LinkedList<T> when:
- You need fast random access (e.g., accessing by index).
- You are sensitive to memory usage.
Real world example: Implementing an LRU (Least Recently Used) Cache.
What .NET Engineers Should Know:
- 👼 Junior: Understand that
LinkedList<T>andList<T>have different performance characteristics. - 🎓 Middle: Should know when to pick
LinkedList<T>for efficient insertion/removal scenarios. - 👑 Senior: Should deeply understand trade-offs, memory implications, and when hybrid approaches (e.g., linked list + dictionary) are needed for performance-critical systems.
📚 Resources: LinkedList<T>
❓ What are the primary differences between a stack and a queue?
Both stacks and queues are fundamental data structures, but they differ in their operation principles:
- Stack: This operation operates on the Last-In-First-Out (LIFO) principle. The last element added is the first to be removed. Think of a stack of plates; you add and remove plates from the top.
- Queue: This operates on the First-In-First-Out (FIFO) principle. The first element added is the first to be removed, akin to a line of people waiting; the person who arrives first is served first.
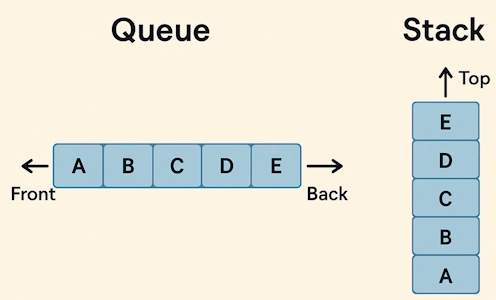
What .NET engineers should know:
- 👼 Junior: Should be able to explain the LIFO and FIFO principles and identify real-world examples of stacks and queues.
- 🎓 Middle: Expected to understand data structures' internal workings, typical use cases, and when to choose one.
- 👑 Senior: Should be adept at implementing stacks and queues from scratch, optimizing their performance, and applying them in complex algorithmic solutions.
❓ What is PriorityQueue<TElement, TPriority> collection, and how does it work?
PriorityQueue<TElement, TPriority> is a collection introduced in .NET 6. It lets you store elements with an associated priority, always dequeuing the element with the smallest priority value first.
Internally, it uses a binary heap for efficient insertion and removal:
- Enqueue: O(log n)
- Dequeue: O(log n)

Example:
var priorityQueue = new PriorityQueue<string, int>();
priorityQueue.Enqueue("Low priority task", 5);
priorityQueue.Enqueue("High priority task", 1);
Console.WriteLine(priorityQueue.Dequeue()); // Outputs: "High priority task"Lower priority value = higher processing priority.
Use Cases:
- Task Scheduling: Managing tasks where specific tasks need to be prioritized over others
- Pathfinding Algorithms: Implementing algorithms like Dijkstra's or A* that require processing nodes based on priority.
- Event Simulation: Handling events at different times, where events with earlier times are processed first.
What .NET Engineers Should Know:
- 👼 Junior: Understand that
PriorityQueue<TElement, TPriority>dequeues items are based on priority, not the insertion order. - 🎓 Middle: Should be able to use
PriorityQueueIn scheduling, Dijkstra’s algorithm or anytime priority-based processing is required. - 👑 Senior: Should understand internal implementation (heap), optimize custom comparers, and know when to prefer alternative data structures.
📚 Resources:
- PriorityQueue<TElement, TPriority> Class
- 📽️ Master the PriorityQueue
- Behind the implementation of .NET's PriorityQueue
Dictionaries and Sets
❓ What is a Dictionary, and when should we use it?
A Dictionary<TKey, TValue> in C#, a hash-based collection stores key-value pairs, allowing fast access to values via their unique keys. It’s part of System.Collections.Generic.
Use a Dictionary when:
- You want O(1) average-time key-based access.
- Each key maps to a single, unique value.
- You don’t need elements to be in any particular order.
Example:
var capitals = new Dictionary<string, string>
{
["France"] = "Paris",
["Germany"] = "Berlin",
["Italy"] = "Rome"
};
Console.WriteLine(capitals["Italy"]); // Output: Rome
What .NET engineers should know about Dictionary:
- 👼 Junior: Should know how to create, add to, and retrieve values from a
Dictionary. Understand that keys must be unique. - 🎓 Middle: Should understand how
Dictionaryuses hashing for fast lookups, and know how to check for key existence (ContainsKey) and handle exceptions safely. - 👑 Senior: Should understand how hash codes and equality affect performance, be able to implement
IEqualityComparer<TKey>for custom key types, and understand memory/performance trade-offs in high-scale scenarios.
📚 Resources:
❓ What is SortedDictionary<TKey, TValue>, and how does it differ from Dictionary<TKey, TValue>?
SortedDictionary<TKey, TValue> is a key-value collection in C# that maintains its elements in sorted order based on the keys.
Unlike Dictionary<TKey, TValue>, which stores items in an unordered hash table, SortedDictionary uses a balanced binary search tree internally (typically a Red-Black Tree), meaning all operations like insert, delete, and lookup take O(log n) time instead of average O(1) with a hash table.
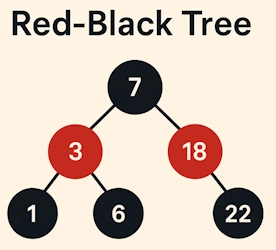
Use it when:
- You need to keep the keys in sorted order for enumeration.
- You need range queries (e.g., get all items with keys between A and F).
- You want deterministic output order for unit testing or logs.
What .NET engineers should know about SortedDictionary<TKey, TValue>
- 👼 Junior: Should understand that
SortedDictionarystores key-value pairs in sorted order and is slower thanDictionaryfor raw access, but valid when ordered keys are essential. - 🎓 Middle: Should know the O(log n) performance trade-offs, and be able to decide when to use it over
Dictionary, especially in scenarios that require in-order traversal or range-based access. - 👑 Senior: Should understand its internal implementation, how it affects CPU vs memory trade-offs, and be able to benchmark and optimize its usage in large-scale systems or high-frequency operations. Should also compare it with alternatives like
SortedListor custom tree structures.
📚 Resources
❓ What is SortedSet<T>, and how does it differ from HashSet<T>?
If you’ve ever used a HashSet<T> in C#, you already know it’s great for checking whether something exists — fast, efficient, no duplicates. But it doesn't care about order.
Enter SortedSet<T>. It also keeps unique values, but in sorted order. Internally, it's built on a balanced tree, so operations like Add, Remove, and Contains are O(log n), not O(1). That tradeoff gives you ordered traversal and access to range-based methods like GetViewBetween.
var tags = new HashSet<string> { "dotnet", "csharp", "backend" };
var sortedTags = new SortedSet<string>(tags);
foreach (var tag in sortedTags)
Console.WriteLine(tag); // Outputs in alphabetical order
- If you need fast set lookups → use
HashSet. - If you need sorted iteration or range queries → use
SortedSet.
What .NET engineers should know about SortedSet<T>
- 👼 Junior: Should know it's a collection of unique items that maintains order.
- 🎓 Middle: Should understand it's slower than HashSet, but sorted. Useful when you need ordered sets or range-based access.
- 👑 Senior: Should know it’s backed by a red-black tree, how to implement custom comparers, and when to use
SortedSetoverHashSet,List, or LINQ-based sorting.
📚 Resources
❓ How do you implement a custom key type for a Dictionary<TKey, TValue>?
Using your class or struct as a dictionary key in C# is valid but comes with a catch. The dictionary needs a way to compare keys and compute hash codes. That means your custom type should properly override both Equals() and GetHashCode().
If you skip this, the dictionary won’t behave as expected. Keys might not be found even if they look identical.
Example
public class Coordinate
{
public int X { get; }
public int Y { get; }
public Coordinate(int x, int y)
{
X = x; Y = y;
}
public override bool Equals(object obj)
{
// your logic to compare objects
}
public override int GetHashCode()
{
return HashCode.Combine(X, Y);
}
}
Now you can safely use Coordinate as a key:
var map = new Dictionary<Coordinate, string>();
map[new Coordinate(1, 2)] = "A point";
Console.WriteLine(map[new Coordinate(1, 2)]); // ✅ Works!
You could also implement IEqualityComparer<T> separately if you can’t or don’t want to override in the class.
What .NET engineers should know about custom keys
- 👼 Junior: Should understand that using a class as a key without
EqualsandGetHashCodebreaks dictionary lookups. - 🎓 Middle: Should be able to override both methods correctly and understand value vs. reference equality. Also, know when to use a custom
IEqualityComparer<T>. - 👑 Senior: Should deeply understand hash collisions, custom equality strategies, and performance implications. Should know when to use
recordtypes for automatic implementation or switch toSortedDictionarywith a customIComparer<T>instead.
📚 Resources: Object.GetHashCode Method
❓ What is a binary search tree, and how would you implement one in C#?
A binary search tree (BST) is a tree where each node has up to two children. The key rule: for any node, values in the left subtree are smaller, and values in the right subtree are larger. This makes search operations faster — ideally O(log n) if the tree is balanced.
BSTs are the backbone of many sorted data structures, like SortedSet<T> and SortedDictionary<TKey, TValue>.
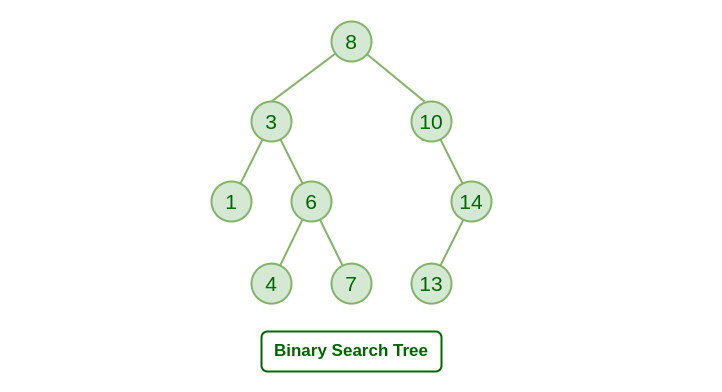
What .NET engineers should know about binary search trees
- 👼 Junior: Should understand the concept — left is smaller, right is bigger. Know that it improves search speed over linear structures.
- 🎓 Middle: Should be able to implement insert/search operations, and understand why an unbalanced BST can degrade to a linked list (O(n)).
- 👑 Senior: Should understand balancing strategies (e.g., red-black, AVL), memory layout, and when a tree structure is more appropriate than arrays or hash tables. Should know that production code typically uses built-in, tested versions like
SortedSet.
📚 Resources: Binary Search Tree
Collections
❓ What are the differences between IEnumerable<T>, ICollection<T>, and IList<T> interfaces?

In C#, these interfaces build on each other like nesting dolls (Matryoshka doll).
Each one adds more functionality on top of the previous:
IEnumerable<T>is the base — it lets you iterate through a collection withforeach.ICollection<T>adds count, add, remove, and containment checks.IList<T>gives full index-based access, like an array.
Quick Breakdown:
| Interface | Supports foreach | Count | Add/Remove | Indexing |
|---|---|---|---|---|
IEnumerable<T> | ✅ | ❌ | ❌ | ❌ |
ICollection<T> | ✅ | ✅ | ✅ | ❌ |
IList<T> | ✅ | ✅ | ✅ | ✅ |
Example
IEnumerable<int> numbers = new List<int> { 1, 2, 3 }; // Can only iterate
ICollection<int> collection = new List<int> { 1, 2, 3 }; // Can Add/Remove
IList<int> list = new List<int> { 1, 2, 3 }; // Can Add/Remove and index
Console.WriteLine(list[0]); // 1
Think of it this way:
- Use
IEnumerable<T>when you're just reading or streaming data. - Use
ICollection<T>when you need to modify the collection (add/remove). - Use
IList<T>when you also need to access items by position.
What .NET engineers should know about collection interfaces
- 👼 Junior: Should understand that
IEnumerable<T>is for iteration and is read-only. Should know when to useIList<T>instead. - 🎓 Middle: Should know the method differences between all three, and that
IList<T>inherit bothIEnumerable<T>andICollection<T>. - 👑 Senior: Should be able to implement custom collections using these interfaces. You should also know where performance matters, e.g.,
IEnumerable<T>for streaming,IList<T>for fast indexed access, and how to hide unnecessary methods via interface segregation.
📚 Resources
❓ What is IReadOnlyCollection<T>, and when would you use it?
IReadOnlyCollection<T> is a read-only interface that represents a collection you can iterate over and count — but not modify.
It’s often used in public APIs to expose internal collections safely, without letting consumers Add, Remove, or Clear.
Internally, you might use a List<T> or HashSet<T>, but return it as IReadOnlyCollection<T> to prevent external mutation.
What .NET engineers should know about IReadOnlyCollection<T>
- 👼 Junior: Should know it provides safe, read-only access to a collection with
Countand iteration. - 🎓 Middle: Understand when to expose
IReadOnlyCollection<T>in APIs to enforce immutability from the outside. Should also know how it differs fromICollection<T>. - 👑 Senior: Should consider immutability as part of API design. Should know when to choose between
IEnumerable<T>,IReadOnlyCollection<T>, andIReadOnlyList<T>to control capabilities and improve code safety and clarity.
📚 Resources
❓ What is IReadOnlyList<T>, and how does it differ from IReadOnlyCollection<T>?
IReadOnlyList<T> is like a read-only array or list — you can access items by index and iterate, but you can’t modify it.
It extends IReadOnlyCollection<T>, so it includes the Count property and enumeration, but adds indexing support (this[int index]).
Think of it this way:
IReadOnlyCollection<T>- For when you only care about the total number and iteration.IReadOnlyList<T>- This is for when you should access items by position.
What .NET engineers should know about IReadOnlyList<T>
- 👼 Junior: Should know it’s a read-only collection that allows indexed access but doesn’t allow changes.
- 🎓 Middle: Should understand how it's helpful in safely exposing internal lists. Knows when to prefer it over
IEnumerable<T>orIReadOnlyCollection<T>for APIs that require indexed access. - 👑 Senior: Should use it to enforce API immutability while preserving performance and usability. Should understand how to return or construct efficient projections (
.ToList()vsArray.Empty<T>()) and avoid exposing internal state directly.
📚 Resources
❓ How does managing List<T> initial capacity improve performance?
Setting an initial capacity List<T> can prevent hidden performance traps in high-throughput or memory-sensitive scenarios.
By default, a List<T> starts with a small internal array. As you add elements, it resizes, doubling the capacity each time it overflows. That resizing involves:
- Allocating a new, larger array.
- Copying existing elements.
- Releasing the old one.
This is fine in small apps, but in performance-critical code, resizing creates unnecessary memory pressure and CPU overhead.
If you know you'll be adding 10,000 items — tell the list up front:
var users = new List<User>(10_000);
This avoids multiple resize steps and improves both speed and memory efficiency.
Example
var list = new List<int>(1000); // pre-allocate space for 1000 items
for (int i = 0; i < 1000; i++)
list.Add(i);
Without that 1000, it would resize repeatedly — from 4 to 8 to 16 to 32... up.
You can also inspect or control capacity later:
list.Capacity = 2000; // manually increase
list.TrimExcess(); // reduce to match CountWhat .NET engineers should know about List<T> capacity
- 👼 Junior: Should know that
List<T>grows automatically, but it’s more efficient to set the capacity if you know the size in advance. - 🎓 Middle: Should understand how resizing works internally (doubling strategy), and how it affects memory and performance. Should know about
.Capacityand.TrimExcess(). - 👑 Senior: Should be able to benchmark large allocations, manage memory proactively, and make tradeoffs between allocation upfront vs. flexibility. Should consider using
ArrayPool<T>orSpan<T>for even finer control when needed.
❓ What is HashSet<T>, and when would you choose it over List<T>?
HashSet<T> is a collection that stores unique elements and offers fast lookups. A hash table backs it, so Add, Remove, and Contains operations are typically O(1) — much faster than searching in a List<T>, which is O(n).
It doesn’t maintain order like a list, but it's often a better fit if you care about uniqueness and performance.
Example
var tags = new HashSet<string> { "csharp", "dotnet" };
tags.Add("csharp"); // Ignored – already exists
tags.Add("collections");
Console.WriteLine(string.Join(", ", tags)); // Unordered outputCompare with List<string>:
var list = new List<string> { "csharp", "dotnet" };
list.Add("csharp"); // Adds a duplicateSo if you're constantly checking "Is this item already here?" — use HashSet<T>.
For ordered data or duplicates → stick with List<T>
What .NET engineers should know about HashSet<T>
- 👼 Junior: Should know it prevents duplicates and is faster than
List<T>for checking if an item exists. - 🎓 Middle: Should understand that it uses hashing, offers O(1) performance for key operations, and is unordered. Should know how to use
SetEquals,IntersectWith, etc. - 👑 Senior: Should understand hashing internals, custom
IEqualityComparer<T>usage, memory behavior, and howHashSet<T>compares withSortedSet<T>,Dictionary<T>, andImmutableHashSet<T>in larger systems.
📚 Resources
❓ How does Dictionary<TKey, TValue> handle key collisions??
When two keys produce the same hash code (a hash collision), Dictionary<TKey, TValue> handles it behind the scenes using chaining — essentially, it stores multiple entries in the same bucket.
Below is a diagram to explain how the dictionary handles it:
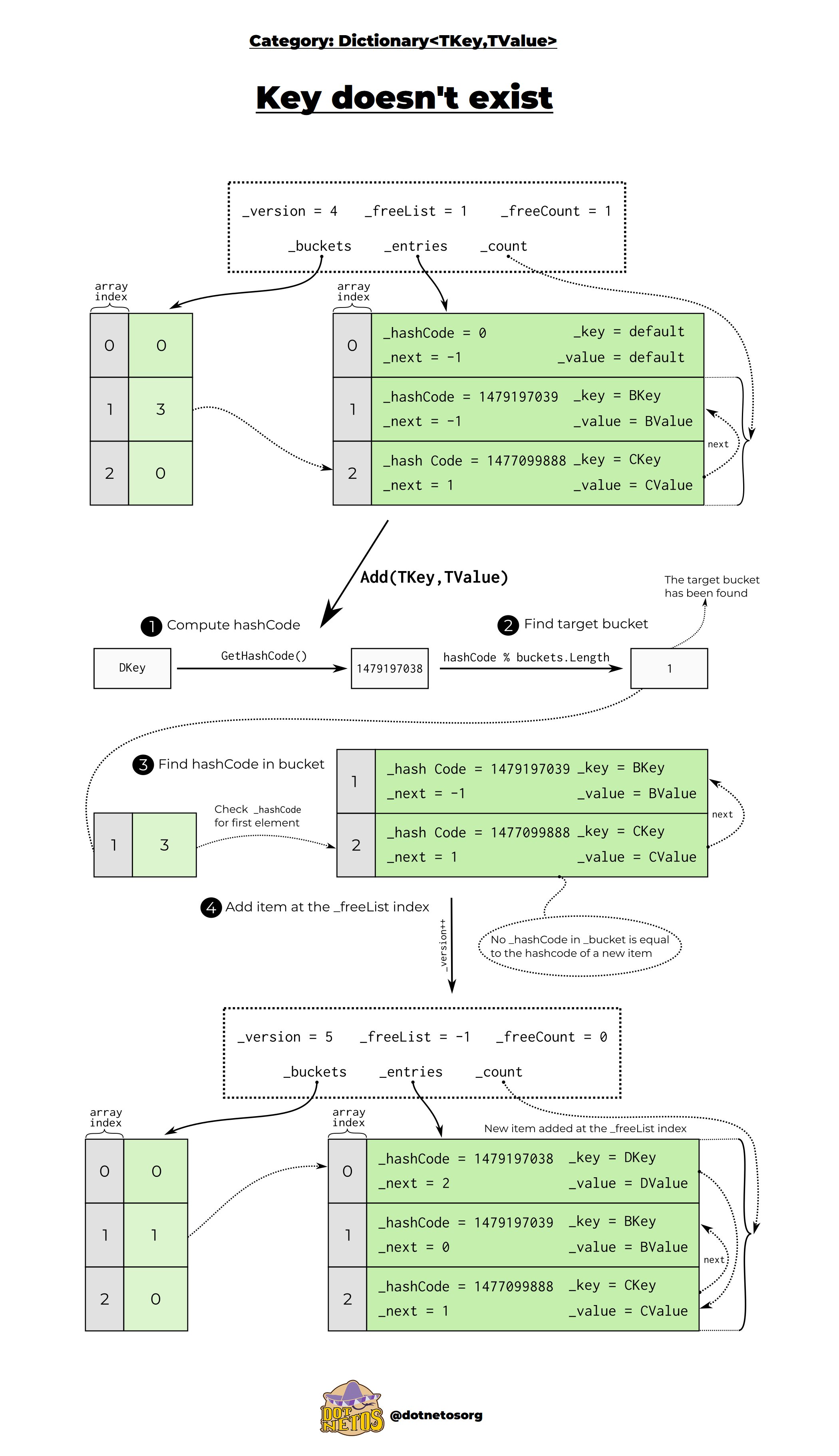
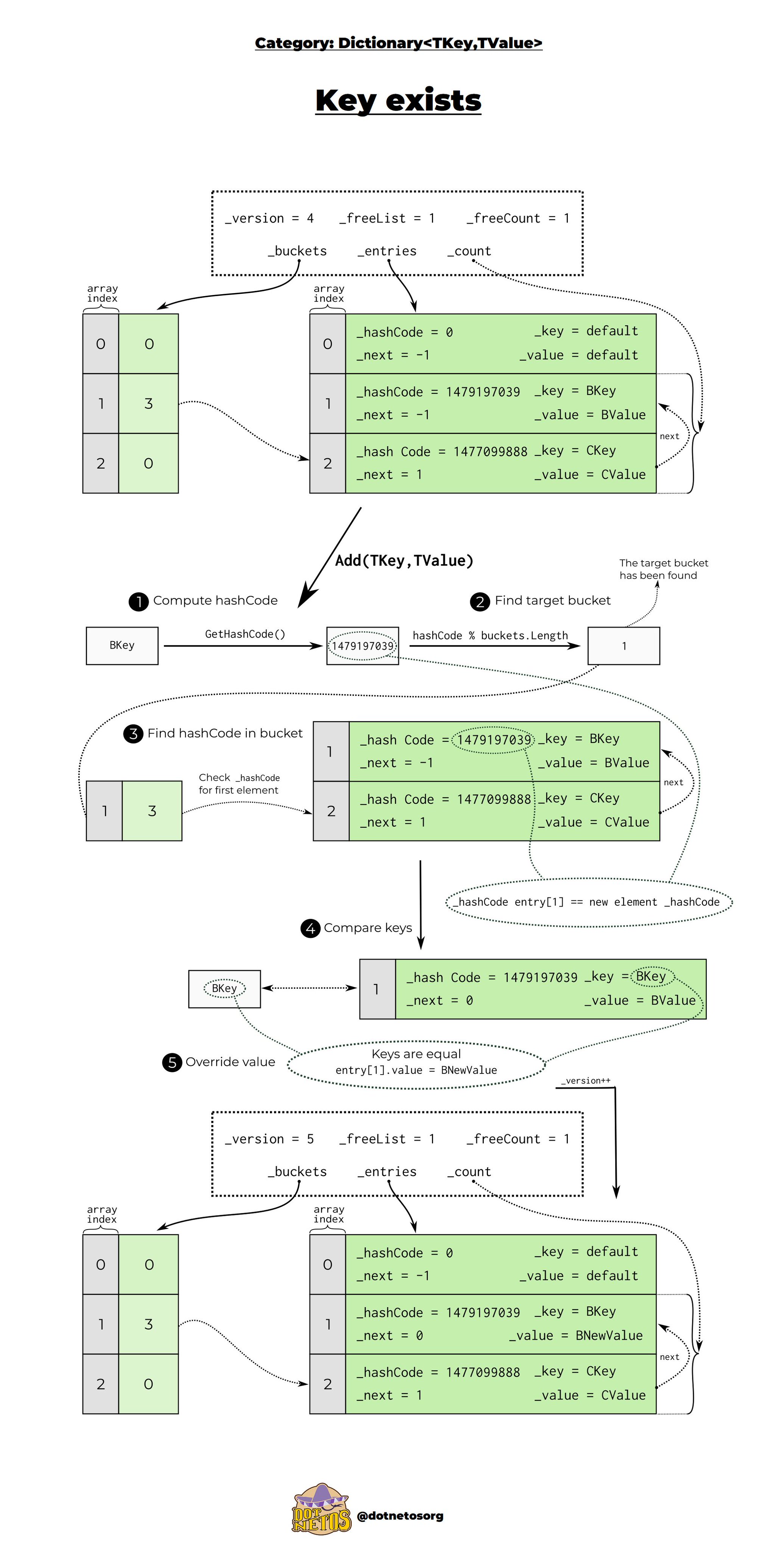
What .NET engineers should know about key collisions in Dictionary<TKey, TValue>
- 👼 Junior: Should know collisions happen when different keys produce the same hash. Dictionary handles this and still works.
- 🎓 Middle: Should understand how hash buckets and
.Equals()help resolve collisions. Should be cautious when overridingGetHashCode()andEquals(). - 👑 Senior: Should know how high collision rates degrade performance (O(n)). Should consider using
Dictionarywith custom comparers or switching toConcurrentDictionary,SortedDictionary, or evenImmutableDictionaryin specific scenarios.
📚 Resources
Dictionary implementation in C#
Specialized and Concurrent Collections
Addresses immutable, observable, and thread-safe collections for advanced scenarios.
❓ What is ImmutableList<T>, and when should you use it in C#?
ImmutableList<T> is a collection that never changes after it’s created. Every operation that would usually modify the list — like Add, Remove, or Insert — Instead, it returns a new list with the change applied.
This makes it thread-safe by design and an excellent fit for functional programming, concurrent systems, or situations where state changes must be controlled or predictable.
Example
using System.Collections.Immutable;
var original = ImmutableList.Create<string>("A", "B");
var updated = original.Add("C");
Console.WriteLine(string.Join(", ", original)); // A, B
Console.WriteLine(string.Join(", ", updated)); // A, B, CYou're not modifying original — you're creating a new version. Think of it as copy-on-write, but internally optimized to avoid complete duplication unless necessary.
When should you use ImmutableList<T>?
- You need safe shared state across threads.
- You're working in functional or event-sourced systems.
- You want predictable behavior without worrying about someone mutating a collection.
- You're exposing public API results that must remain unchanged.
For internal use in performance-sensitive areas, mutable List<T> is still faster. But for safety and clarity, ImmutableList<T> wins.
What .NET engineers should know about ImmutableList<T>
- 👼 Junior: You should know it’s a list you can’t change — all changes return a new one.
- 🎓 Middle: Should understand it’s helpful in multi-threaded and functional scenarios, and that
Add,Remove, etc., return new instances. - 👑 Senior: Should know internal optimizations (structural sharing), trade-offs vs.
List<T>, and when to useImmutableList<T>vs.ReadOnlyCollection<T>. Should also know how to compose immutable collections in record types or with copy semantics.
📚 Resources: ImmutableList<T> Class
❓ What is ObservableCollection<T>, and how does it differ from List<T> in the UI applications?
ObservableCollection<T> is like List<T>, but with a "superpower": it notifies UI frameworks (like WPF or MAUI) when its contents change. Add, remove, or move an item — the UI instantly knows about it.
That’s the key difference. List<T> Doesn’t raise change events. If you update a List<T> bound to the UI, nothing happens visually — you have to refresh it manually.
ObservableCollection<T> implements INotifyCollectionChanged and INotifyPropertyChanged, making it the go-to for dynamic data binding in .NET UI frameworks.
Example
public ObservableCollection<string> Items { get; } = new();
Items.Add("Apples"); // UI will automatically update
Items.Remove("Apples"); // UI updates again
In XAML:
<ListBox ItemsSource="{Binding Items}" />
Bind it once, and you're done — the UI will stay in sync with your data as it changes.
What .NET engineers should know about ObservableCollection<T>
- 👼 Junior: Should know it’s like a list, but notifies the UI when items are added or removed. Essential for live updates in data-bound controls.
- 🎓 Middle: Should understand how it implements
INotifyCollectionChanged, and when to use it in WPF, MAUI, or MVVM patterns. It should also be noted that it has limitations — no batch update support is available out of the box. - 👑 Senior: Should know how to handle performance issues in significant updates (e.g., using
CollectionView, custom batch notifications, orRangeObservableCollection). Should also manage threading carefully when updating from background tasks (e.g., Dispatcher usage).
📚 Resources
❓ What is ConcurrentDictionary<TKey, TValue>, and how does it differ from Dictionary<TKey, TValue>?
ConcurrentDictionary<TKey, TValue> is a thread-safe alternative to Dictionary<TKey, TValue>. It's designed for concurrent access, meaning multiple threads can read and write to it safely, without needing external locks.
In contrast, Dictionary<TKey, TValue> is not thread-safe. If you try to update it from multiple threads, you’ll likely hit exceptions or data corruption unless you manage synchronization manually (e.g., with lock).
Example
var dict = new ConcurrentDictionary<string, int>();
dict["users"] = 1;
dict.AddOrUpdate("users", 1, (key, oldValue) => oldValue + 1);
Console.WriteLine(dict["users"]); // 2
It includes atomic methods like:
TryAddTryUpdateGetOrAddAddOrUpdate
These eliminate the need for lock blocks and reduce complexity in multithreaded code.
Use ConcurrentDictionary when:
- You need shared state across multiple threads.
- You want to avoid managing locks manually.
- Performance matters under concurrency, and correctness is critical.
What .NET engineers should know about ConcurrentDictionary<TKey, TValue>
- 👼 Junior: Should know it behaves like a dictionary but is safe for multithreaded use.
- 🎓 Middle: Should understand it’s optimized for concurrent reads/writes and includes atomic operations that simplify thread-safe updates.
- 👑 Senior: Should know internal partitioning strategy, how contention affects performance, and when to switch to other concurrency-safe structures like
Channel<T>or immutable collections. Should also be aware of the trade-offs versus manual locking for fine-grained control.
📚 Resources
- ConcurrentDictionary<TKey, TValue> – Microsoft Docs
- Thread-safe collections in .NET
- [RU] Dictionary in .NET
❓ How do atomic operations like GetOrAdd work in ConcurrentDictionary<TKey, TValue>?
One of the biggest headaches in multi-threaded code is race conditions — two threads checking and adding the same key simultaneously. That’s where atomic methods like GetOrAdd come in.
ConcurrentDictionary is often described as “lock-free”, but that is only half-true:
- Reads are lock-free. Operations such as
TryGetValueor the indexer getter use atomic instructions and never acquire a lock. - Writes use tiny, per-bucket locks. The dictionary is internally divided into segments (buckets). When an operation like
GetOrAdd,AddOrUpdate, orTryRemovemodifies an entry, it locks only the affected bucket, leaving the rest of the dictionary available to other threads.
| Operation | Locking strategy | Typical complexity |
|---|---|---|
TryGetValue, indexer get | Lock-free | O(1) |
GetOrAdd, AddOrUpdate, TryAdd, TryRemove | Locks one bucket | O(1) amortised |
| Enumeration | Takes a point-in-time snapshot (no lock while iterating) | O(n) |
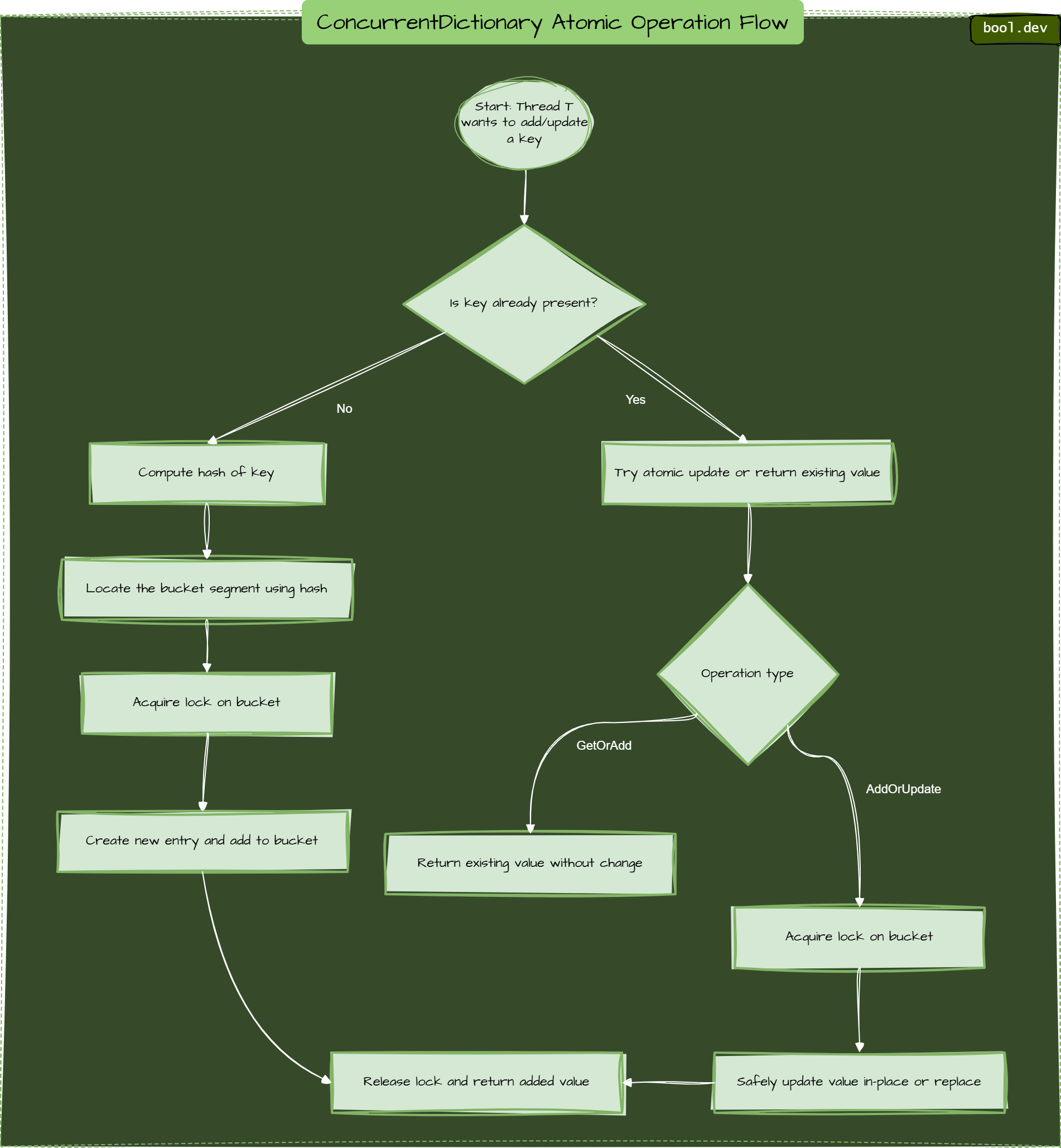
Under the hood, ConcurrentDictionary:
- Hashes the key and maps it to a bucket.
- Lock only that bucket, not the whole dictionary.
- Checks if the key exists. If not, it calls the value factory.
- Stores the result, unlocks, and returns the value.
What .NET engineers should know
- 👼 Junior: Should know the basics about how
ConcurrentDictionarymethods work - 🎓 Middle: Should understand it's atomic and avoids race conditions. You should know when to use overload with a delegate vs. a static value.
- 👑 Senior: Should be aware of potential performance bottlenecks in the value factory (e.g., slow I/O), and that it can be called multiple times if exceptions occur. Should know how
GetOrAddintegrates into caching, lazy loading, and task memoization patterns.
❓ What is ConcurrentQueue<T>, and when would you use it in multi-threaded scenarios?
ConcurrentQueue<T> is a thread-safe, FIFO (first-in, first-out) queue built for multi-threaded applications. It lets multiple threads safely enqueue and dequeue items without requiring locks.
It's ideal for scenarios where:
- One or more threads produce data (enqueue).
- One or more threads consume data (dequeue).
- You want fast, non-blocking coordination between threads.
Unlike traditional Queue<T>, which throws exceptions or causes race conditions if used concurrently, ConcurrentQueue<T> handles synchronization under the hood.
Example
var queue = new ConcurrentQueue<string>();
queue.Enqueue("task1");
queue.Enqueue("task2");
if (queue.TryDequeue(out var result))
Console.WriteLine($"Processing: {result}");All operations (Enqueue, TryDequeue, TryPeek) are atomic and lock-free, meaning they're optimized for high concurrency.
Common use cases
- Background processing: producer/consumer patterns
- Logging: queue log messages from multiple sources
- Job queues: lightweight task scheduling across threads
It’s beneficial in apps with Task-based parallelism, background workers, or thread-safe pipelines.
What .NET engineers should know about ConcurrentQueue<T>
- 👼 Junior: Should know it’s like
Queue<T>but safe for use by multiple threads. - 🎓 Middle: Should understand it's FIFO and supports atomic
Enqueue/TryDequeue. Ideal for producer-consumer problems. - 👑 Senior: Should know internal structure (segment-based array buffers), memory trade-offs, and when to prefer it over
BlockingCollection<T>,Channel<T>, orConcurrentBag<T>. Should also know it’s non-blocking — if you need blocking behavior, useBlockingCollection<T>overConcurrentQueue<T>.
❓ What is ImmutableArray<T>, and how does it differ from List<T>?
ImmutableArray<T> It is a fixed-size, read-only array that can’t be changed after creation. Unlike List<T>, which you can grow, shrink, or modify freely, ImmutableArray<T> is all about predictability, safety, and performance — especially in multi-threaded or functional-style code.
It's a great fit when:
- You want value semantics (like structs).
- You need array-level performance, but with immutability guarantees.
- You want to avoid allocations that come from cloning lists for defensive copies.
Example
using System.Collections.Immutable;
var original = ImmutableArray.Create("a", "b");
var updated = original.Add("c");
Console.WriteLine(string.Join(", ", original)); // a, b
Console.WriteLine(string.Join(", ", updated)); // a, b, c
There is no in-place modification. Every change creates a new array, but it uses optimizations internally to avoid full copies when possible.
List<T> vs ImmutableArray<T>
| Feature | List<T> | ImmutableArray<T> |
|---|---|---|
| Mutable? | ✅ Yes | ❌ No |
| Thread-safe by design? | ❌ No | ✅ Yes |
| Performance | Fast, flexible | Fast, optimized read-heavy |
| Memory allocation | Resizes on growth | Fixed-size after creation |
| Use case | General purpose | Immutable collections, APIs, multithreading |
What .NET engineers should know about ImmutableArray<T>
- 👼 Junior: Should know it's a read-only version of an array that can't be changed.
- 🎓 Middle: Should understand the immutability concept, performance benefits, and how it differs from
List<T>andImmutableList<T>. - 👑 Senior: Should know when to choose
ImmutableArray<T>overImmutableList<T>, how it avoids unnecessary allocations via pooling or struct-based usage, and how to use it in high-performance, thread-safe, and functional code patterns.
📚 Resources
❓ What is ReadOnlyCollection<T>, and what are its limitations?
ReadOnlyCollection<T> is a wrapper around an existing list that prevents modification through its public API. It’s useful when you want to expose a collection as read-only, but still keep full control internally.
Under the hood, it just wraps another IList<T>. If someone holds a reference to the original list, they can still change it — and the changes will reflect in the ReadOnlyCollection<T>. So it’s not truly immutable.
Example
var list = new List<string> { "apple", "banana" };
var readOnly = new ReadOnlyCollection<string>(list);
Console.WriteLine(readOnly[0]); // apple
// readOnly.Add("orange"); ❌ Compile error
list.Add("orange"); // Modifies the underlying list
Console.WriteLine(readOnly[2]); // orange – still shows up
So while ReadOnlyCollection<T> prevents accidental changes via the wrapper, it doesn't protect the underlying data if it’s still accessible.
Common limitations
- Not truly immutable — internal modifications to the original list are reflected.
- No thread safety — you're still at risk if multiple threads access the underlying list.
- No
Add,Remove, orClearmethods (by design). - No easy support for value equality or cloning.
If you need stronger guarantees, consider ImmutableList<T> instead.
What .NET engineers should know about ReadOnlyCollection<T>
- 👼 Junior: Should know it wraps a list and makes it appear read-only — helpful for exposing public APIs safely.
- 🎓 Middle: Should understand the limitation: changes to the underlying list affect the read-only view. Knows when to use
ReadOnlyCollection<T>vsToList()copy. - 👑 Senior: Should be aware of memory trade-offs, mutation risks, and how
ReadOnlyCollection<T>compares toImmutableList<T>in terms of API guarantees, concurrency, and safety.
📚 Resources
Advanced Topics
❓ How does LINQ interact with collections, and what are common performance pitfalls?
LINQ (Language Integrated Query) provides a clean way to query and transform collections in C#. It works with any type that implements IEnumerable<T> or IQueryable<T>. That includes arrays, lists, sets, dictionaries — anything you can loop over.
However, behind the syntactic sugar lies a significant amount of deferred execution, temporary allocations, and occasionally, invisible performance traps.
Common performance pitfalls
1. Multiple enumeration
var filtered = list.Where(x => x > 10);
Console.WriteLine(filtered.Count()); // Iterates once
Console.WriteLine(filtered.First()); // Iterates again
2. Deferred execution surprises
Your query result may change or break if the underlying collection changes before you iterate.
3. Boxing in LINQ to object
Using non-generic LINQ (Cast, OfType) can result in boxing value types, which is detrimental to performance-sensitive code.
4. Materializing significant intermediate results
Using .ToList() after every step, it creates unnecessary allocations and memory pressure.
5. Querying large IEnumerable<T> instead of using optimized collections
LINQ on a List<T> is fine. LINQ on a custom IEnumerable<T> with no index access? It could be slow.
What .NET engineers should know about LINQ and collections
- 👼 Junior: Should know LINQ is a way to query collections. Understand basics like
Where,Select, andToList. - 🎓 Middle: Should understand deferred execution, multiple enumeration, and memory implications of intermediate materializations.
- 👑 Senior: Should know when to avoid LINQ in hot paths, how to profile its impact, and when to switch to loops or
Span<T>for performance. Should also understand how LINQ behaves differently withIQueryablevsIEnumerable.
📚 Resources
Basic Instincts: Increase LINQ Query Performance
❓ What is Memory<T>, and how does it enhance collection performance?
Memory<T> is a powerful .NET type that lets you work with slices of data without copying it. It’s like Span<T>, but with one big difference: it’s safe to use asynchronously and can be stored in fields, returned from methods, and awaited across calls.
You get all the benefits of Span<T> — slicing, fast access, zero allocations — without its limitations.
With traditional collections, slicing or subsetting often means copying:
var sublist = list.GetRange(0, 5); // allocates new listWith Memory<T>, you can point to a segment of the original array, and work with it directly:
int[] data = Enumerable.Range(0, 100).ToArray();
Memory<int> window = data.AsMemory(10, 20); // no copy
for (int i = 0; i < window.Length; i++)
Console.WriteLine(window.Span[i]); // fast, zero allocThis reduces GC pressure and improves cache locality, especially useful in high-performance, real-time, or data-processing code.
Use cases:
- Buffer slicing (e.g., in I/O or image processing)
- Avoiding allocations in inner loops
- Streaming/parsing extensive data without copies
- Anywhere
Span<T>would be used, but asynchronously
What .NET engineers should know about Memory<T>
- 👼 Junior: Should know it’s a way to efficiently work with parts of an array or collection.
- 🎓 Middle: Should understand how
Memory<T>differs fromSpan<T>(e.g., async support, heap-allocable). Knows when to use.Spanfor fast access. - 👑 Senior: Should deeply understand stack vs heap semantics, pooling strategies, how
Memory<T>helps in high-throughput pipelines (e.g., System.IO.Pipelines), and how to design APIs that return or acceptMemory<T>safely.
📚 Resources
- Memory-related and span types
- Memory<T> Struct
- 📽️ Turbocharged: Writing High-performance C# and .NET code, by Steve Gordon
❓ What are the implications of value vs. reference types in collection performance?
In C#, value types (struct) and reference types (class) behave very differently, especially when used in collections. These differences affect memory layout, CPU usage, GC pressure, and comparisons.
Key differences that impact collection performance:
1. Memory allocation
- Value types are stored in-line (e.g., inside arrays or lists).
- Reference types are stored on the heap, and collections hold references (pointers) to them.
👉 With value types, collections like List<T> store raw values. No indirection, better cache locality.
var points = new List<Point>(); // struct Point — data is stored in-place
var users = new List<User>(); // class User — only references are storedLarge-Object Heap:
If a single array (of either value or reference types) exceeds ~85,000 bytes, it is allocated on the Large Object Heap (LOH).
One enormous value-type array can be moved directly to the Large Object Heap (LOH), where collections occur only at Gen-2 GC, allowing it to stay alive longer while utilizing contiguous memory, which provides good cache locality.
Many small reference-type objects remain in Gen 0/1, but each incurs its own header, potentially fragmenting memory.
2. Boxing
When value types are used in non-generic collections (e.g., ArrayList, IEnumerable), they're boxed — copied into a heap-allocated object.
Boxing adds allocations and GC pressure.
ArrayList list = new ArrayList();
list.Add(123); // boxing!✅ Use List<int> instead — no boxing.
3. Copying behavior
- Value types are copied by value — each assignment or method call creates a copy.
- Reference types are copied by reference — all references point to the same object.
This matters when passing items into methods or iterating:
foreach (var point in points) // value type
point.X = 100; // modifies copy, not the original✅ Be cautious when using struct in collections, if the mutation is needed.
4. Equality and lookups
- Value types use value equality by default — unless overridden.
- Reference types use reference equality, unless
Equals()orIEquatable<T>is implemented.
For sets and dictionaries, this affects how keys and lookups behave.
When are value types better?
- You have small, immutable data structures.
- You're working in performance-critical code (e.g., real-time, low-latency)
- You want to avoid GC pressure
When to prefer reference types?
- The object is large or contains lots of data
- You need polymorphism or shared references
- You care more about developer productivity than raw performance
What .NET engineers should know about value vs. reference types in collections
- 👼 Junior: Understand that structs are copied, classes are referenced. Prefer
List<int>overArrayListto avoid boxing. - 🎓 Middle: Recognise that structs improve cache locality and reduce heap allocations, but copying and mutation can be tricky.
- 👑 Senior: Know how memory layout, CPU caches, GC generations, and the LOH influence struct vs. class trade-offs. Benchmark and profile collection-heavy code for boxing, layout, and allocation patterns.
📚 Resources
❓ What are FrozenDictionary<TKey,TValue> and FrozenSet<T>, and when should you use them?
Both ship in .NET 8 under System.Collections.Frozen. They are read-only collections optimized for lookup speed. You build them once, then read from them many times.
The tradeoff is simple: construction is slower than a regular Dictionary or HashSet. Lookup is faster. Use them for data that loads at startup and never changes.
using System.Collections.Frozen;
// Build once at startup
var allowedRoles = new HashSet<string> { "Admin", "Editor", "Viewer" }
.ToFrozenSet();
var errorCodes = new Dictionary<int, string>
{
[400] = "Bad Request",
[401] = "Unauthorized",
[404] = "Not Found",
[500] = "Internal Server Error"
}.ToFrozenDictionary();
// Read many times, fast
bool isAllowed = allowedRoles.Contains("Admin");
string description = errorCodes[404];Register as singletons in ASP.NET Core:
builder.Services.AddSingleton(
new Dictionary<string, string>
{
["support-copilot"] = "You are a support assistant...",
["code-review"] = "You are a code review assistant..."
}.ToFrozenDictionary());When to use vs regular collections
| Scenario | Use |
|---|---|
| Data changes at runtime | Dictionary / HashSet |
| Data loads once, read frequently | FrozenDictionary / FrozenSet |
| Config, lookup tables, prompt stores | FrozenDictionary |
| Permission sets, feature flags | FrozenSet |
What .NET engineers should know
- 👼 Junior:
FrozenDictionaryandFrozenSetare read-only collections. Build them from existing collections with.ToFrozenDictionary()or.ToFrozenSet(). - 🎓 Middle: Use them for static lookup tables in AI pipelines: model name mappings, prompt templates, token limits per model. Faster lookups in hot paths with zero thread-safety concerns.
- 👑 Senior: Prefer
FrozenDictionaryoverConcurrentDictionaryfor read-heavy static data.ConcurrentDictionaryadds locking overhead you do not need when data never changes after startup.
❓ FrozenDictionary vs Dictionary vs ImmutableDictionary vs ReadOnlyDictionary. When should you choose each?
| Type | Mutable | Thread-safe | Lookup speed | Use when |
|---|---|---|---|---|
Dictionary | Yes | No | Fast | Data changes at runtime |
ReadOnlyDictionary | Wrapper only | No | Fast | Exposing internal dict without write access |
ImmutableDictionary | New instance | Yes | Slower | Shared state needing safe functional updates |
FrozenDictionary | No | Yes | Fastest | Static data is loaded once and read constantly |
What .NET engineers should know
- 👼 Junior: Start with
Dictionary. Switch toReadOnlyDictionarywhen you expose internal collections through a public API and want to prevent external writes. - 🎓 Middle: Use
ImmutableDictionaryfor shared state passed across threads or async boundaries, where callers need to derive modified versions without affecting the original. - 👑 Senior: Replace
ConcurrentDictionarywithFrozenDictionaryfor static lookup tables loaded at startup.ConcurrentDictionaryadds locking overhead you do not need when data never changes.
❓ What is Lookup<TKey,TElement>, and how does it differ from Dictionary<TKey,List<T>>?
Lookup<TKey,TElement> groups elements by key, like a Dictionary<TKey,List<T>>, but with three practical differences: it is immutable, it never throws on missing keys, and you build it only via LINQ.
var orders = new[]
{
new Order { CustomerId = "C1", Total = 100 },
new Order { CustomerId = "C1", Total = 200 },
new Order { CustomerId = "C2", Total = 300 }
};
// Lookup: built via LINQ, read-only
var lookup = orders.ToLookup(o => o.CustomerId);
var c1Orders = lookup["C1"]; // returns 2 orders
var c3Orders = lookup["C3"]; // returns empty sequence, no exception
// Dictionary<TKey,List<T>>: mutable, throws on missing key
var dict = orders
.GroupBy(o => o.CustomerId)
.ToDictionary(g => g.Key, g => g.ToList());
var c1List = dict["C1"]; // works
var c3List = dict["C3"]; // KeyNotFoundExceptionMissing key behavior is the biggest practical difference. Lookup returns an empty sequence. Dictionary throws.
| Scenario | Use |
|---|---|
| Build once, read many times | Lookup |
| Need to add or remove keys at runtime | Dictionary<TKey,List<T>> |
| Querying grouped data in memory | Lookup |
| Need safe missing-key access without try-catch | Lookup |
What .NET engineers should know
- 👼 Junior: Use
Lookupwhen you group items by a key and read them later. Missing keys return empty, not an exception. - 🎓 Middle: Prefer
LookupoverDictionary<TKey,List<T>>in read-only grouping scenarios. Less code, safer access, and no manual list initialization. - 👑 Senior:
Lookupfits in-memory join operations in data pipelines. For AI features that group retrieved chunks by document ID or tenant before injecting into a prompt,Lookupremoves defensive null checks across the pipeline.
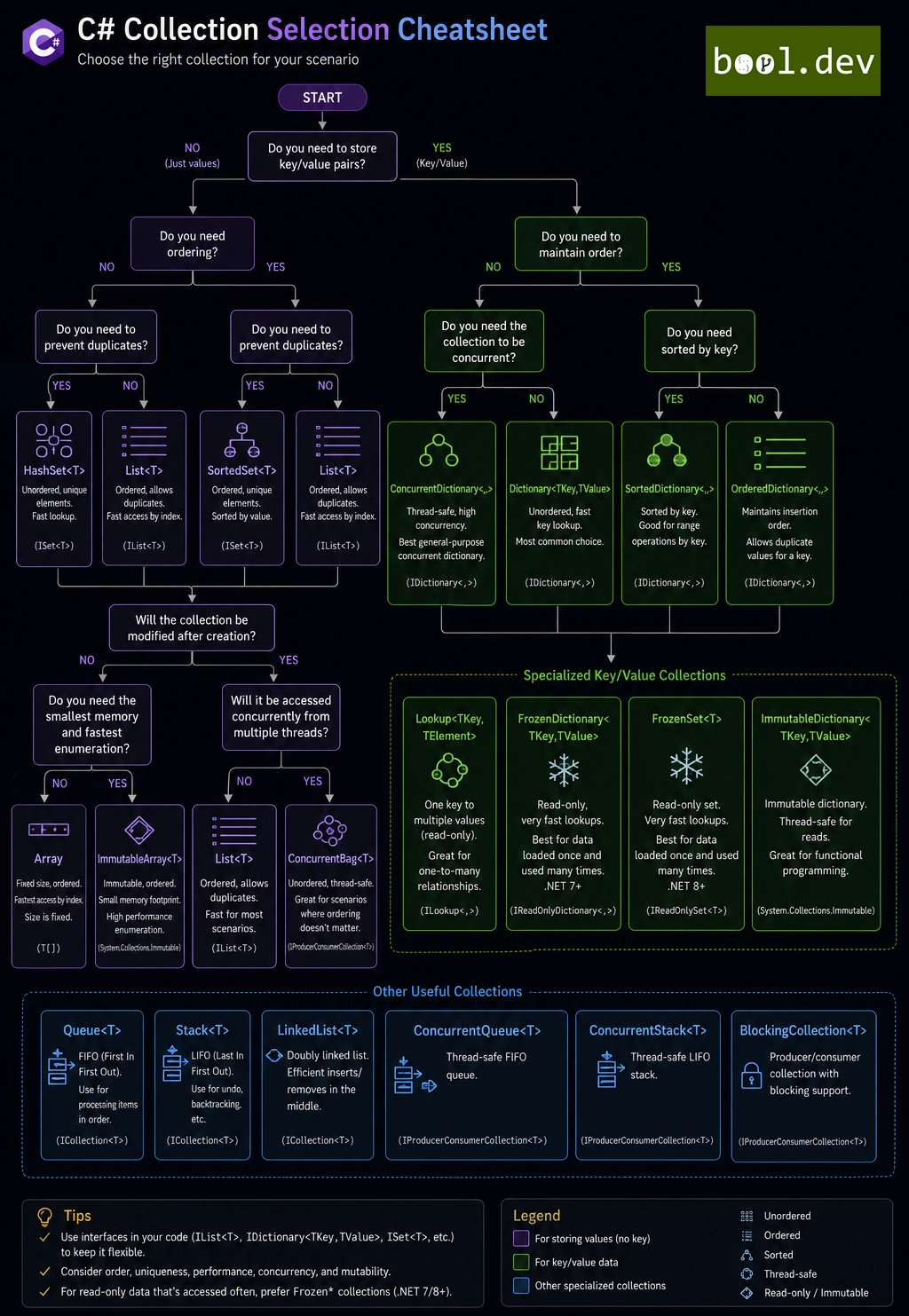
C# Collection selection CheatSheet
📖 Read Next:
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 4: Async & Parallel Programming
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum