10 ADR Anti-Patterns and ADR Best Practices for Developers, Tech Leads and Architects

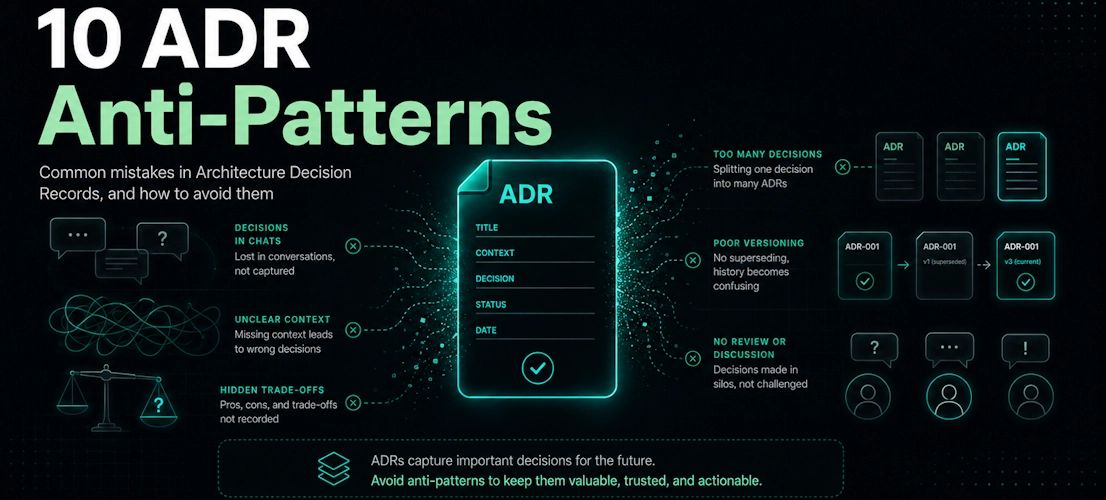
In this article, I will explain 10 anti-patterns in Architecture Decision Records and how to avoid them. Consider this article a guide to following Best Practices and creating a good Architecture Decision Record (ADR).
What Is an ADR?
An ADR, or Architecture Decision Record, is a short document that captures a single architectural decision.
It answers one question:
Why did we decide this?
A good ADR does not try to explain the whole system. It does not replace diagrams, onboarding guides, API documentation, or implementation notes. It records the reasoning behind a decision while the context is still fresh.
The real audience is not only your current team. The real audience is the person who joins your team two years later, finds a strange design choice, and asks:
Also, please check our article to know which Effective Software Architecture Documentation you can use for which use case.
Architecture Decision Records Anti-patterns:
Anti-Pattern 1: Not writing ADRs at all

The decision still gets made. It just lives in someone's head, or in a Chat thread that's gone in a week. Later, nobody remembers why you picked that queue, that database, that weird workaround. The person who knew has left. New joiners can't tell a careful choice from an accident, so they're scared to touch anything, or they rip it out and hit the exact wall you already hit once.
An ADR is cheap insurance against all of that. One page, written once, saves the team from having to re-argue the same thing every year. If you take nothing else from this post, start writing them. Then worry about the nine ways to do it better.
Anti-Pattern 2: Using ADRs as Developer Documentation

An ADR should not explain how to run the project, how the authentication flow works, or which class does what. Those belong in developer documentation. Developer documentation changes often.
An ADR explains why you made a decision.
Use the right document for the right job:
- README for setup and local development
- Wiki for team processes and operational notes
- C4 diagrams for system structure
- Architecture views for architecture documentation
- ADRs for architectural decisions
Docs explain how. ADRs explain why.
- If someone needs setup steps, runtime behavior, or API usage information, put that in the README, wiki, or technical documentation.
- If someone needs to know why you chose PostgreSQL over MongoDB, write an ADR.
Anti-Pattern 3: Using ADRs as an Architecture Overview

Diagrams, C4 models, and system maps show how your system looks today. Those are living documents.
ADRs work differently. An ADR is a snapshot of a decision made at a specific moment.
An ADR says:
On this date, with this context, we chose X.
Use a separate design document mechanism to explore alternative options thoroughly. Reference these design documents within the ADR, adhering to the principles of invention and simplification.
Anti-Pattern 4: Combining Many Decisions Into One ADR

The default is one decision per ADR.
You decided on a database, a message broker, and an authentication provider in one meeting. Usually, you need three ADRs.
Why?
- Each decision has its own lifecycle.
- The choice of database might change next year. The message broker might stay for five years. The authentication provider might get replaced by a company-wide platform.
- Put all three in one ADR, and you lose traceability.
Bad ADR split and title:
ADR-001: Database and Messaging StrategyBetter: Each decision gets its own status, date, context, alternatives, and consequences.
ADR-001: Use PostgreSQL for Order Storage
ADR-002: Use Kafka for Order Event Streaming
ADR-003: Use Auth0 for Customer AuthenticationThe Exception: Tight Corollaries
Sometimes a decision and its direct corollary only make sense together. Choosing PostgreSQL forces you to choose a specific migration tool. The choice of tool has no independent life. Split them and you produce an artificial second ADR nobody reads alone.
Ask:
Will these two choices change independently?
If yes, split them. If no, you have one decision with two parts. Keep them together.
When Decisions Belong Together
Sometimes several ADRs share the same architecture area but make independent decisions. Do not merge them into one large ADR. Create an architecture view instead.
Example:
Architecture View: Recommendation Engine
This page explains:
- What the recommendation engine does
- Which components take part
- How data flows through the system
- Which quality attributes matter
- Which ADRs explain the key choices
Then each real decision becomes a separate ADR:
- ADR-0012: Use a Feature Store for User Signals
- ADR-0013: Serve Recommendations With a Two-Tower Model
- ADR-0014: Stream User Events Through Kafka
- ADR-0015: Cache Recommendations in Redis
- ADR-0016: Fall Back to Popularity-Based Recommendations on Cold Start
- ADR-0017: Run A/B Tests Through the Existing Experimentation Platform
Supersede ADR-0015 next year; the other decisions remain unchanged.
The view gives the big picture. The ADRs preserve the decision history.
Anti-Pattern 5: Editing ADRs and Changing the Decision

You don't rewrite an ADR when the decision changes.
Think about it like a log from your app. You log
"log 1: user creates profile"
"log 2: user updated profile."
"log 3: user updated profile (2)"
You don't go back and delete the old log line. You add a new one. The history is the whole point.
Same with ADRs. If you change your mind, you write a new ADR that replaces the old one. The old one stays. You just mark it as "Superseded by ADR-0042."
Anti-Pattern 6: Recording the Decision but Not the Alternatives

The most valuable part of an ADR is often the road you did not take.
Two years later, someone asks:
Why did they skip Redis? Why did they skip MongoDB? Why did they skip Kafka? Why did they skip the platform standard?
List those options and explain why you rejected them. You save future people from having to repeat the same debate.
Record only the winner, and the old discussion comes back.
A weak ADR says:
We chose PostgreSQL.
A better ADR says:
We chose PostgreSQL because we need relational constraints, transactional consistency, and strong reporting support. We considered MongoDB and rejected it because the domain has many relational queries and reporting use cases. We considered DynamoDB but rejected it because the team lacks operational experience and the query model does not align with current access patterns.
So that's why I prefer ADR templates that include the considered options.
Anti-Pattern 7: Only Selling the Decision and Hiding the Tradeoffs

A good ADR stays honest. Every architecture decision costs something. List only the benefits, and you do not have a decision record. You have internal marketing.
Bad:
We chose Kafka because it scales, stays reliable, and stays popular.
Better:
We chose Kafka because we need high-throughput event streaming and replay. This gives us better decoupling and event history. This also adds operational complexity, schema governance, consumer-lag monitoring, and a longer learning curve for the team.
This is a real ADR.
Good ADRs answer both sides:
- What gets easier?
- What gets harder?
- What risk do you accept?
- What future change gets harder?
- What operational cost appears?
- What skill gap do you create?
Anti-Pattern 8: Letting AI Make the Tradeoff for You

Be careful. The AI doesn't know your real context, your team's skills, your budget, your deadlines, that one weird legacy system, the politics, what you discussed with your colleague in the elevator, or the thing your biggest customer needs. It's working off general patterns, not your situation. It can list options and spell out generic pros and cons very well. That part is useful. But the actual call, the tradeoff that fits your world, is yours to make and yours to own. Use AI to draft and to widen your thinking. Don't let it sign the decision for you.
Anti-Pattern 9: Writing ADRs After the Fact

If you write the ADR six months later to tick a box, the context is already gone. You don't remember the forces, the constraints, the pressure you were under. Write it when you decide, while the "why" is still fresh.
Example:
Status: Accepted (reconstructed)
Decided: ~2023 (exact date unknown)
Documented: 2026-06-21
Note: This ADR was written after the fact. The decision and
its main alternatives are well understood. Some original
constraints are inferred from commit history and team memory.Anti-Pattern 10: Writing and Approving ADRs Alone

Architectural decisions should not appear out of nowhere.
One architect writes an ADR alone, accepts it, and expects everyone to follow. The team treats the file as paperwork.
For decisions across multiple teams or decisions that shape the system for years, treat ADRs like code. Establish the discussion. Let people (architects/tech leads/team members) comment. Discuss alternatives. Capture the decision. Mark's decision has been accepted. The discussion is part of the value. A decision the team never saw is not a team decision.
Architecture Decision Record (ADR) Template and Example
Architecture Decision Record (ADR) Template
Let's take a look at what an ADR example usually follows:
##Status
Draft / Proposed / Accepted / Rejected / Superseded
## Decision
Proceed with option 1 [name of option]
## Proposed by
username
## Context and Problem Statement
Briefly describe the context or problem that led to this decision:
* Why are we making this decision?
* What situation or concern prompted it?
## Considered Options
- Option 1 name of option
- Option 2 name of option
## Option 1 name of option
Description, diagrams, etc
### Pros
- first
- second
### Cons
- first
- second
## Option 2 name of option
Description, diagrams, etc
### Pros
- first
- second
### Cons
- first
- second
##References
Link to supporting docs, tickets, and other ADR'sArchitecture Decision Record (ADR) Example:
# ADR-0016: Fall Back to Popularity-Based Recommendations on Cold Start
## Status
Accepted
## Decision
Proceed with Option 1: serve popularity-based recommendations on cold start.
## Proposed by
Artem P
## Context and Problem Statement
The two-tower model (ADR-0013) ranks items using user signals from the
feature store (ADR-0012). A new user has no signal history. With no
signals, the model returns weak or empty results. The first session
decides whether we keep a new user, so an empty shelf is the worst
outcome.
We need a fallback with these properties:
- returns useful recommendations with zero user history
- responds within the same latency budget as the main model
- needs little new infrastructure
- hands off to the personalized model as soon as signals arrive
Cold start covers two cases: a brand-new user, and a user with too few
events for the model to rank well.
## Considered Options
- Option 1: Popularity-based recommendations
- Option 2: Content-based recommendations from item metadata
## Option 1: Popularity-based recommendations
Serve the top items by recent engagement. Compute popularity offline per
segment (region, language, device) and refresh on a schedule. Cache the
lists in Redis (ADR-0015). On cold start, the service returns the segment
list instead of calling the model.
### Pros
- Simple. A batch job and a cached list, nothing more.
- Fast. A cache read, no model inference.
- Always returns something. No empty shelf.
- Reuses the Redis cache already in place.
- Easy to reason about and easy to explain to stakeholders.
### Cons
- Not personalized. Every new user in a segment sees the same items.
- Popularity bias. Popular items gain more exposure and stay popular.
- Goes stale between refreshes during fast trend shifts.
## Option 2: Content-based recommendations from item metadata
Recommend items similar to whatever the new user views or clicks first,
using item metadata such as category, tags, and embeddings. The first
interaction seeds the recommendations.
### Pros
- More relevant than global popularity once the user acts once.
- Reduces popularity bias. Surfaces items from the long tail.
- Works for new items too, not only new users.
### Cons
- Needs clean, complete item metadata. Gaps lower quality fast.
- Returns nothing before the first interaction, so the empty state still needs a popularity fallback.
- More to build and maintain: a similarity index and an embedding pipeline.
- Higher latency than a cached list.
## References
- ADR-0012: Use a Feature Store for User Signals
- ADR-0013: Serve Recommendations With a Two-Tower Model
- ADR-0015: Cache Recommendations in Redis With a 15-Minute TTL
- RECS-208: Cold-start handling for new users
- Internal doc: Recommendation Engine architecture view