Объектно-реляционные структурные паттерны (PoEAA)


Сегодня мы поговорим про Object-Relational Structural Patterns из каталога паттернов для архитектуры корпоративных приложений (PoEAA). Мы рассмотрим назначение каждого из них, а так же сильные и слабые стороны.
Identity Field

Identity Field – cохраняет идентификатор записи базы данных для поддержки соответствия между объектом приложения и строкой базы данных.
Назначение
Identity Field используется тогда, когда необходимо построить отображение между объектами, расположенными в оперативной памяти, и строками таблиц базы данных. Как правило, такая необходимость возникает при использовании модели предметной области или шлюза записи данных. Подобное отображение не нужно, если вы используетеTransaction Script, Table Module, или шлюз таблицы данных (Table Data Gateway). Для небольшого объекта с семантикой значения (например, для объекта, представляющего денежную величину или диапазон дат), которому не соответствует отдельная таблица, вместо поля идентификации лучше воспользоваться внедренным значением (Embedded Value, 288). В то же время для сложного графа объектов, к которому не нужно осуществлять запросов в пределах реляционной СУБД, добиться более удобного обновления и лучшей производительности можно за счет использования крупного сериализованного объекта.
Отображение внешних ключей (Foreign Key Mapping)
Отображает ассоциации между объектами на ссылки внешнего ключа между таблицами базы данных
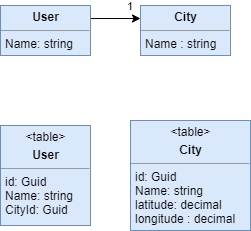
Объекты могут ссылаться непосредственно друг на друга с помощью объектных ссылок (object references). Даже самая простая объектно-ориентированная система обязательно содержит группу объектов, связанных между собой всеми возможными и невозможными способами. Разумеется, при сохранении объектов в базе данных необходимо позаботиться и о сохранении всех ссылок. К сожалению, поскольку содержимое объектов специфично для конкретного экземпляра запущенной программы, сохранение значений "в чистом виде" ничего не даст. Данную проблему еще более усложняет тот факт, что объекты могут содержать коллекции ссылок на другие объекты. Подобная структура нарушает определение первой нормальной формы реляционных баз данных. Типовое решение отображение внешних ключей отображает объектную ссылку на внешний ключ базы данных.
Назначение
Отображение внешних ключей может применяться для моделирования практически всех видов связей между классами. Наиболее распространенный случай, когда отображение внешних ключей применить нельзя, — это связи типа "многие ко многим". Внешние ключи являются одномерными значениями, а из определения первой нормальной формы следует, что в одном поле нельзя хранить множественные значения внешних ключей. В этом случае вместо отображения внешних ключей необходимо воспользоваться отображением с помощью таблицы ассоциаций (см. Association Table Mapping). Если у вас есть поле коллекции без обратного указателя, подумайте о том, не сделать ли "множественную сторону" ссылки отображением зависимых объектов. Это значительно упростит обработку коллекции. Если связанный объект является объектом-значением (см. Value Object), вместо отображения внешних ключей следует воспользоваться внедренным значением (см. Embedded Value).
Пример использования Foreign Key Mapping в C#
public class Object1
{
public int Property1{ get; set; }
public string Property2 { get; set; }
//Foreign key for Object2
public int FK_Object2_Property { get; set; }
[ForeignKey("FK_Object2_Property")]
public Object2 Object2 { get; set; }
}
public class Object2
{
public int Property1{ get; set; }
public string Property2 { get; set; }
public ICollection<Object1> Objects { get; set; }
}Отображение с помощью таблицы ассоциаций (Association Table Mapping)
Сохраняет множество ассоциаций в виде таблицы, содержащей внешние ключи таблиц, связанных ассоциациями
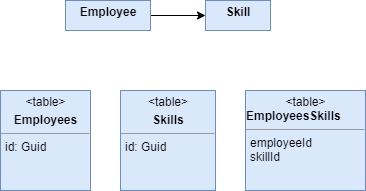
Назначение
Каноническим примером использования отображения с помощью таблицы ассоциаций является связь типа "многие ко многим", поскольку альтернативы данному решению просто нет. Отображение с помощью таблицы ассоциаций может быть использовано и для других типов связей. Разумеется, поскольку данное типовое решение является более сложным, чем отображение внешних ключей, а также требует дополнительной операции соединения, его выбор не всегда может быть удачным. Впрочем, оно незаменимо в ситуациях, когда у разработчика нет полного контроля над схемой базы данных. Иногда вам может понадобиться связать две существующие таблицы, к которым нельзя добавить новые столбцы. В этом случае вы можете создать новую таблицу и воспользоваться отображением с помощью таблицы ассоциаций. Другой возможный вариант использования данного типового решения состоит в том, что существующая схема базы данных включает в себя таблицу отношений, даже если эта таблица на самом деле не нужна. В этом случае для представления отношений легче воспользоваться отображением с помощью таблицы ассоциаций, чем пытаться упростить схему базы данных. Иногда таблицу отношений проектируют таким образом, чтобы она содержала в себе некоторые сведения об отношении. В качестве примера можно привести таблицу отношений "служащие—компании", которая помимо внешних ключей будет содержать информацию о должности, занимаемой служащим в данной компании. В этом случае таблица "служащие-компании" будет соответствовать полноценному объекту домена.
Отображение зависимых объектов (Dependent Mapping)
Передает некоторому классу полномочия по выполнению отображения для дочернего класса
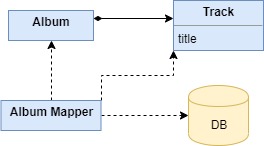
Некоторые объекты в силу своей семантики применяются в контексте других объектов. Например, композиции альбома могут загружаться или сохраняться тогда же, когда и сам альбом. Если на композиции альбома не ссылается никакая другая таблица базы данных, процедуру отображения можно значительно упростить, передав полномочия по выполнению отображения для композиций объекту, выполняющему отображение для альбома. Подобная схема получила название отображения зависимых объектов (dependent mapping).
Назначение
Отображение зависимых объектов используется тогда, когда в приложении есть ооъетсг, на который ссылается только какой-нибудь другой объект (например, когда у объекта есть коллекция зависимых от него объектов). Данное типовое решение прекрасно подходит для ситуаций, при которых у объекта-владельца есть коллекция ссылок на зависимые объекты, однако нет обратных указателей. Если в приложении есть множество объектов, которым не нужны собственные идентификаторы, использование отображения зависимых объектов значительно облегчает управление или в базе данных. Отображение зависимых объектов может применяться только при соблюдении следующих условий:
- у каждого зависимого объекта должен быть строго один владелец;
- на зависимый объект может ссылаться только его владелец.
Внедренное значение (Embedded Value)
Отображает объект на несколько полей таблицы, соответствующей другому объекту

В приложениях часто встречаются небольшие объекты, которые имеют смысл в объектной модели, однако совершенно бесполезны в качестве таблиц базы данных. Хорошим примером таких объектов являются деньги в определенной валюте или диапазоны дат. Хотя общепринятая практика предусматривает сохранение объектов в виде таблиц, разработчик не станет создавать таблицу денежных значений. Типовое решение внедренное значение отображает значения полей объекта на поля записи его владельца. В качестве примера можно привести объект-должность, который ссылается на такие объекты, как диапазон дат и денежное значение.
Назначение
Понять принцип действия внедренного значения легко, а вот определить область его применения гораздо труднее. Наиболее очевидными кандидатами для применения внедренного значения являются простые и понятные объекты-значения (см Value Object) наподобие денежных значений и диапазонов дат. Поскольку у объектов-значений нет идентификаторов, их можно свободно создавать и уничтожать, не беспокоясь о таких вещах, как синхронизация с помощью коллекций объектов (Identity Map). Вообще говоря, все объекты-значения должны храниться в виде внедренных значений, поскольку им никогда не понадобятся отдельные таблицы.
Сериализованный крупный объект (Serialized LOB)
Сохраняет граф объектов путем их сериализациив единый крупный объект(Large Object — LOB) и помещает его в поле базы данных
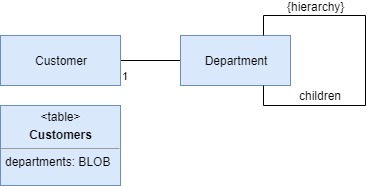
Существует два вида крупных объектов: крупный двоичный объект (binary LOB — BLOB) и крупный символьный объект (character LOB— CLOB). Объекты BLOB проще создавать, поскольку многие платформы включают в себя возможность автоматической сериализации графов объектов. В этом случае сохранение графа представляет собой простую сериализацию содержимого буфера и последующее сохранение этого буфера в соответствующем поле таблицы.
В лучае CLOB граф объектов сериализуется в текстовую строку, содержащую всю необходимую информацию. Полученный текст вполне читабелен, что заметно облегчает работу при простом просмотре базы данных. Тем не менее сериализованный объект в текстовом формате занимает гораздо больший объем памяти и может потребовать написания специального анализатора. Кроме того, обработка символьных объектов обычно занимает больше времени, чем обработка двоичных
Назначение
Крупный сериализованный объект применяется далеко не так часто, как можно было бы подумать. Привлекательность данного типового решения подкрепляется возможностью сериализации в формат XML, существенным образом упрощающей кодирование. Тем не менее данный подход имеет большой недостаток, поскольку к содержимому подобной структуры нельзя осуществлять запросы средствами SQL В последние годы на рынке программного обеспечения появились расширения языка SQL, позволяющие извлекать XML-данные в пределах поля, однако это еще не то, что нужно (по крайней мере подобные решения не обеспечивают переносимости). Данное типовое решение хорошо применять тогда, когда требуется сохранить сложный фрагмент объектной модели в виде единого целого (в частности, объекта LOB). Для большей наглядности LOB можно рассматривать как способ сохранения группы объектов, к которым не будут поступать SQL-запросы из-за пределов данного приложения. В этом случае сохраненный граф объектов может быть описан с помощью SQL-схемы.
Наследование с одной таблицей (Single Table Inheritance)
Представляет иерархию наследования классов в виде одной таблицы, столбцы которой соответствуют всем полям классов, входящих в иерархию
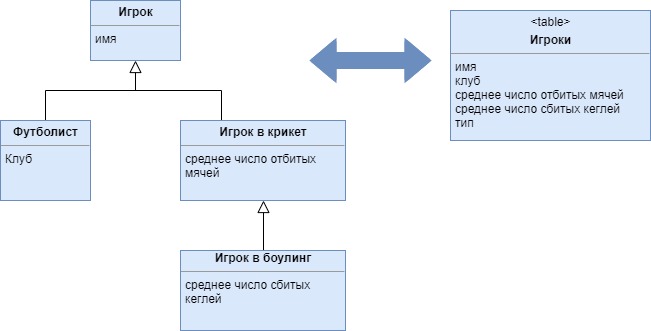
Реляционные базы данных не поддерживают наследование. Выполняя отображение объектной модели на базу данных, необходимо найти способ, позволяющий отобразить структуру наследования. Разумеется, крайне важно минимизировать количество соединений, которое стремительно возрастает при попытке отображения структуры наследования на разные таблицы. На помощь приходит типовое решение наследование с одной таблицей, отображающее все поля всех классов структуры наследования на столбцы одной и той же таблицы.
Назначение
Наследование с одной таблицей является одним из вариантов отображения иерархии наследования на реляционную базу данных. В число других возможных вариантов входят наследование с таблицами для каждого класса (см. Class Table Inheritance) и наследование с Concrete Table Inheritance.
Преимущества Single Table Inheritance
- В структуру базы данных добавляется только одна таблица.
- Для извлечения данных не нужно выполнять join таблиц.
- Перемещение полей в производный класс или суперкласс не требует внесения из менений в структуру базы данных.
Недостатки Single Table Inheritance
- Не все поля соответствуют содержимому каждого конкретного объекта, что может приводить в замешательство людей, работающих только с таблицами.
- Некоторые столбцы используются только одним-двумя производными классами, что приводит к бессмысленной трате свободного места. Критичность данной проблемы зависит от характеристик конкретных данных, а также от того, насколько хорошо сжимаются пустые поля.
- Полученная таблица может оказаться слишком большой, с множеством индексов и частыми блокировками, что будет оказывать негативное влияние на производи тельность базы данных. Во избежание этой проблемы можно создать отдельные таблицы индексов, которые будут содержать ключи строк, имеющих определенное свойство, или же копии подмножеств полей, имеющих отношение к индексам.
- Все имена столбцов таблицы принадлежат единому пространству имен, поэтому необходимо следить за тем, чтобы у полей разных классов не было одинаковых имен. Для облегчения работы рекомендую называть поля составными именами с указанием имени содержащего их класса в качестве префикса или суффикса.
Пример на псевдо-C#:
class Mapper...
protected DataTable table {
get {return Gateway.Data.Tables [TableName ];}
}
protected Gateway Gateway;
abstract protected String TableName {g et;}Поскольку таблица всего одна, ее можно определить в абстрактном классе
class AbstractPlayerMapper...
protected override String TableName {
get {return "Players";}Каждому классу нужно поставить в соответствие код типа класса, чтобы преобразователь знал, с каким игроком он имеет дело. Код типа определяется в родительском классе и реализуется в производных классах.
class AbstractPlayerMapper...
abstract public String TypeCode {get;}
class CricketerMapper...
public const String TYPE_CODE = "C";
public override String TypeCode { get
{return TYPE_CODE;}Класс playerMapper содержит по одному полю на каждый из трех конкретных классов преобразователей (и соответственно на каждый из трех типов игроков).
class PlayerMapper...
private BowlerMapper bmapper;
private CricketerMapper cmapper;
private FootballerMapper fmapper;
public PlayerMapper (Gateway gateway) : base (gateway) {
bmapper = new BowlerMapper(Gateway) ;
cmapper = new CricketerMapper(Gateway) ;
fmapper = new FootballerMapper(Gateway) ; }Загрузка объекта из базы данных:
Каждый конкретный класс преобразователя содержит метод поиска для извлечения объекта из базы данных
class CricketerMapper.. .
public Cricketer Find(long id) {
return (Cricketer)AbstractFind(id);
}
Для выполнения поиска данный метод вызывает универсальный метод родительского класса.
class Mapper...
protected DomainObject AbstractFind(long id) {
DataRow row = FindRow(id); return (row ==
null) ? null : Find(row);
}
protected DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results [0];
}
public DomainObject Find (DataRow row) {
DomainObject result = CreateDomainObject();
Load(result, row);
return result;
}
abstract protected DomainObject CreateDomainObject();
class CricketerMapper...
protected override DomainObject CreateDomainObject() {
return new CricketerO; }
Для загрузки данных в новый объект Мартин приминяет группу методов загрузки — по одному в каждом классе иерархии.
class CricketerMapper...
protected override void Load(DomainObject obj,
DataRow row) {
base.Load(obj,row);
Cricketer cricketer = (Cricketer) obj;
cricketer.battingAverage = (double)row[
"battingAverage"]; }
class AbstractPlayerMapper. . .
protected override void Load(DomainObject obj,
DataRow row) {
base.Load (obj, row); Player player =
(Player) obj; player.name =
(String)row["name"]; }
class Mapper...
protected virtual void Load(DomainObject obj,
DataRow row) {
obj.Id = (int) row ["id"];
}
Вместо этого мы можем загрузить сведения об игроке с помощью преобразователя PlayerMapper. Он считывает данные и использует код типа класса, чтобы определить, какой конкретный преобразователь нужно использовать в данном случае
class PlayerMapper...
public Player Find (long key) {
DataRow row = FindRow(key); if
(row == null) return null; else
{
String typecode = (String) row["type"];
switch (typecode){
case BowlerMapper.TYPE_C0DE:
return (Player) bmapper.Find(row);
case CricketerMapper.TYPE_CODE:
return (Player) cmapper.Find(row);
case FootballerMapper.TYPE_CODE:
return (Player) fmapper.Find(row);
default:
throw new Exception("unknown type"); } } }Update
Суть операции обновления одинакова для всех классов, поэтому ее можно определить В Mapper,
class Mapper...
public virtual void Update (DomainObject arg){
Save (arg,FindRow(arg.Id));
}Метод сохранения аналогичен методу загрузки, т.е. определен в каждом производном классе для сохранения соответствующих данных.
class CricketerMapper...
protected override void Save(DomainObject obj,
DataRow row) {
base.Save(obj, row); Cricketer cricketer = (Cricketer)
obj; row["battingAverage"] = cricketer.battingAverage;
}
class AbstractPlayerMapper...
protected override void Save(DomainObject obj,
DataRow row) {
Player player = (Player) obj;
row["name"] = player.name;
row["type"] = TypeCode; }
Мапрер playerMapper обращается к нужному конкретному мапперу
class PiayerMapper...
public override void Update (DomainObject obj) {
MapperFor(obj).Update(obj);
}
private Mapper MapperFor(DomainObject obj) {
if (obj is Footballer)
return fmapper; if
(obj is Bowler) return
brnapper; if (obj is
Cricketer)
return cmapper;
throw new Exception("No mapper available"); }Insert
Выполнение вставки аналогично обновлению; единственная существенная разница состоит в том, что перед сохранением данных в таблице нужно создать новую строку.
class Mapper...
public virtual long Insert (DomainObject arg) {
DataRow row = table.NewRow();
arg. Id = GetNextlDO ;
row["id"] = arg.Id;
Save (arg, row);
table.Rows.Add(row);
return arg.Id;
}
class PlayerMapper...
public override long Insert (DomainObject obj) {
return MapperFor(obj).Insert(obj);
}Delete
Удаление объекта Удалить объект очень просто. Операции удаления определены на абстрактном уровне, а также в классе-оболочке PlayerMapper.
class Mapper...
public virtual void Delete(DomainObject obj) {
DataRow row = FindRow(obj.Id);
row.Delete();
}
class PlayerMapper...
public override void Delete (DomainObject obj) {
MapperFor(obj).Delete(obj); }Наследование с таблицами для каждого класса (Class Table Inheritance)
Представляет иерархию наследования классов, используя по одной таблице для каждого класса
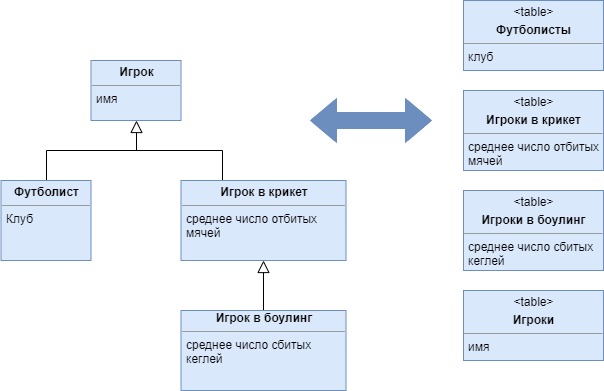
Одним из наиболее очевидных несоответствий объектной и реляционной моделей является то, что реляционные базы данных не поддерживают наследование. Между тем требуется создать такую структуру базы данных, которая бы хорошо отображалась на объекты и сохраняла все возможные связи объектной модели. Для этого применяется типовое решение наследование с таблицами для каждого класса, которое использует по одной таблице на каждый класс структуры наследования
Идея наследования с таблицами для каждого класса довольно проста: каждому классу модели соответствует своя таблица базы данных. Поля класса домена отображаются непосредственно на столбцы соответствующей таблицы. Как и в других схемах отображения иерархии наследования, в данном типовом решении применяется фундаментальный принцип преобразователей наследования (Inheritance Mappers)
Преимущества:
- Все поля таблицы соответствуют содержимому каждой ее строки (т.е. в каждом описываемом объекте), поэтому таблицы легки в понимании и не занимают лишнего места.
- Взаимосвязь между моделью домена и схемой базы данных проста и понятна.
Недостатки
- Загрузка объекта охватывает сразу несколько таблиц, что требует их соединения либо множества обращений к базе данных с последующим "сшиванием" результатов в памяти.
- Перемещение полей в производный класс или родительский класс требует изменения структуры базы данных.
- Таблицы родительских классов могут стать "узким местом" в вопросах производительности, поскольку доступ к таким таблицам будет осуществляться слишком часто.
- Высокая степень нормализации может стать препятствием для выполнения запросов, не хранящихся в базе данных (ad hoc queries).
Помните, вы вовсе не обязаны использовать единственную форму отображения для всей иерархии наследования. Например, вы можете применить наследование с таблицами для каждого класса для классов, находящихся на верхних уровнях иерархии, и несколько наследований с таблицами для каждого конкретного класса для классов на более низких уровнях.
Наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance)
Представляет иерархию наследования классов, используя по одной таблице для каждого конкретного класса этой иерархии
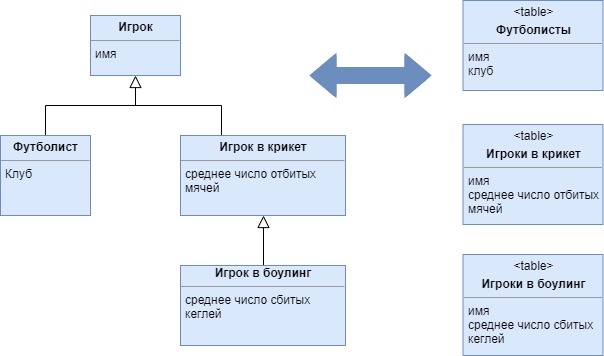
Данное типовое решение подразумевает создание отдельной таблицы для каждого конкретного класса иерархии наследования. При этом каждая таблица содержит столбцы, соответствующие полям конкретного класса и всех его "предков", а потому поля родительского класса дублируются во всех таблицах его производных классов. Как и остальные схемы отображения иерархии наследования, данное типовое решение основано на фундаментальном принципе Inheritance Mappers.
Назначение
Для отображения иерархии наследования на реляционную базу данных могут применяться наследование с таблицами для Concrete Table Inheritance, Class Table Inheritance, Single Table Inheritance.
Преимущества
- Каждая таблица является замкнутой и не содержит ненужных полей, вследствие чего ее удобно использовать в других приложениях, не работающих с объектами.
- При считывании данных посредством конкретных преобразователей не нужно выполнять соединений.
- Доступ к таблице осуществляется только в случае доступа к конкретному классу, что позволяет распределить нагрузку по всей базе данных.
Недостатки
- Первичные ключи могут быть неудобны в обработке.
- Отсутствует возможность моделировать отношения между абстрактными классами
- Если поля классов домена перемещаются в родительские классы или производные классы, придется вносить изменения в определения таблиц. Эти изменения будут не так часты, как в случае наследования с таблицами для каждого класса, однако их нельзя просто игнорировать, как было в случае с наследованием с одной таблицей.
- Если в родительском классе будет изменено какое-нибудь поле, понадобится изменить каждую таблицу, имеющую данное поле, поскольку поля родительского класса дублируются во всех таблицах его производных классов.
- Абстрактному методу поиска придется просматривать все таблицы производных классов, что потребует большого количества обращений к базе данных.
Преобразователи наследования (Inheritance Mappers)
Структура, предназначенная для организации преобразователей, которые работают с иерархиями наследования
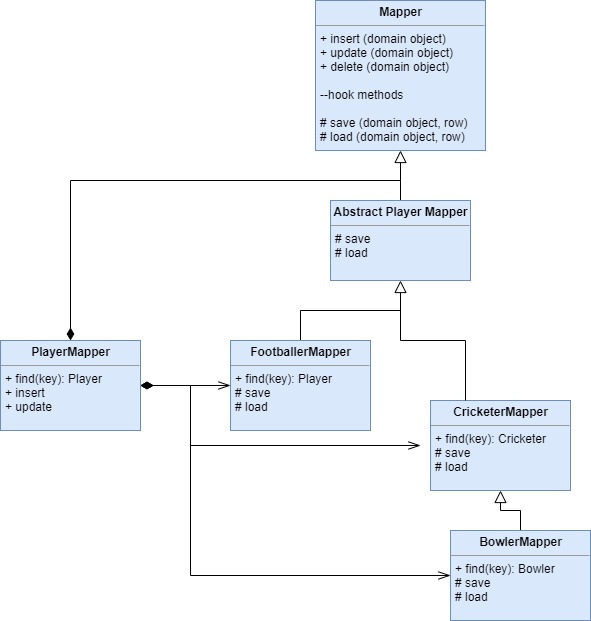
Данная схема может применяться для всех типов отображения иерархии наследования на реляционную базу данных. Возможные альтернативы включают в себя дублирование кода абстрактного маппера во всех конкретных мапперах либо вынесение содержимого класса PlayerMapper В класс AbstractPlayerMapper. Первый из этих способов иначе как "гнусным преступлением против человечества" и не назовешь. Второй способ более реален, однако использовать общий (и довольно запутанный) класс PlayerMapper крайне неудобно. Вообще говоря, придумать действительно удачную альтернативу мапперам наследования практически невозможно.
При отображении объектно-ориентированной иерархии наследования на реляционную базу данных крайне важно минимизировать количество кода, необходимого для загрузки и сохранения содержимого базы данных. Кроме того, необходимо реализовать и абстрактное, и конкретное поведение, что позволит сохранять или загружать как экземпляр родительского класса, так и экземпляры производных классов.
Мапперы можно организовать в иерархию, так, чтобы у каждого класса домена был свой преобразователь, который будет загружать и сохранять данные этого класса. В этом случае у нас есть одна точка, в которой можно изменить принцип отображения. Данный подход хорошо применять для конкретных преобразователей, которые "знают", как отображать конкретные объекты иерархии. Тем не менее иногда мапперы нужны и для абстрактных классов. Это можно реализовать с помощью специальных преобразователей, которые находятся за пределами базовой иерархии, однако делегируют выполнение операций соответствующим конкретным преобразователям.
Источник: Martin Fowler