Архитектура Netflix — Обзор архитектур

Netflix - пожалуй самая известная компания по стриммингу видео. В этой статье попробуем разобраться, то как построена архитектура Netflix и что они используют для поддержания true highload'а
Немножко статистики
Подписота Netflix
По состоянию на февраль 2021 года подписчики Netflix распределены следующим образом:
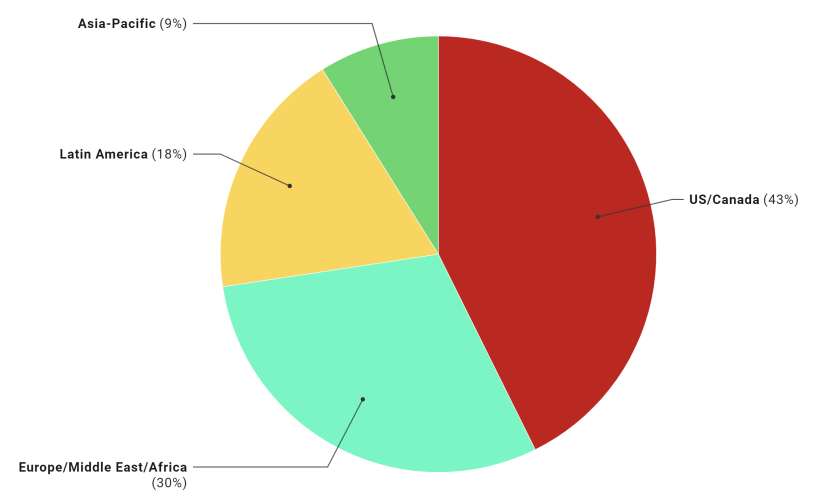
- США и Канада (UCAN): 73 миллиона
- Европа, Ближний Восток и Африка (EMEA): 66 миллионов
- Латинская Америка (LATAM): 37 миллионов
- Азиатско-Тихоокеанский регион (APAC): 25 миллионов
По данным Leichtman Research Group, по крайней мере 62% американских семей теперь имеют учетную запись Netflix. В 2010 году только 16% имели учетку Netflix. Netflix продолжает оставаться самым распространенным стримминговым сервисом в США и за рубежом.
Netflix является одним из крупнейших пользователей Amazon Web Services
По данным intricately Netflix тратит на AWS около 9,6 миллиона долларов в месяц.
Теперь давайте перейдем к архитектуре:
Big picture
Netflix работает в двух облаках: Amazon Web Services и Open Connect (Netflix content delivery network).
На хайлевеле архитектура в нетфликса выглядит следующим образом:
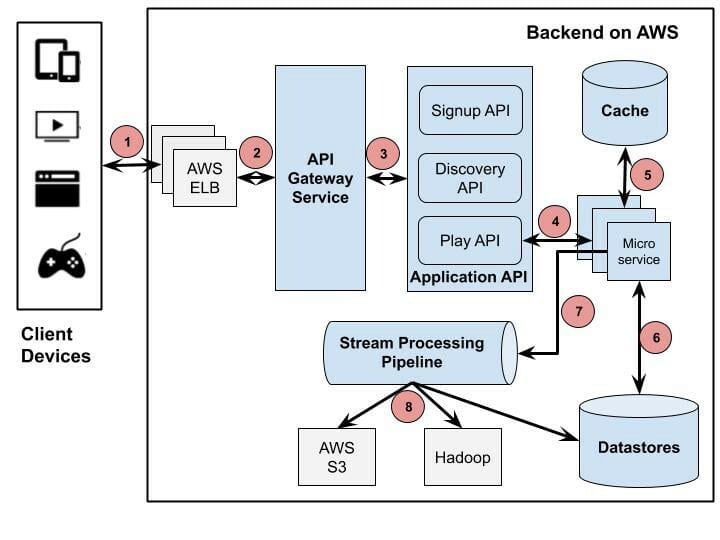
Back-end Архитектура
Backend включает сервисы, базы данных и хранилища, полностью работающие в облаке AWS. Backend в основном обрабатывает все, кроме потокового видео. Компоненты бека с соответствующими сервисами AWS перечислены ниже:
- Scalable computing instances: AWS EC2
- Scalable storage: AWS S3
- Микросервисы для бизнес логики: фреймворк созданный тимой Netflix
- Масштабируемые распределенные БД: MySQL, Cassandra
- Работа с обработкой больших данных и аналитикой: AWS EMR, Hadoop, Spark, Flink, Kafka and и другие спец тулы сделанные командой Netflix
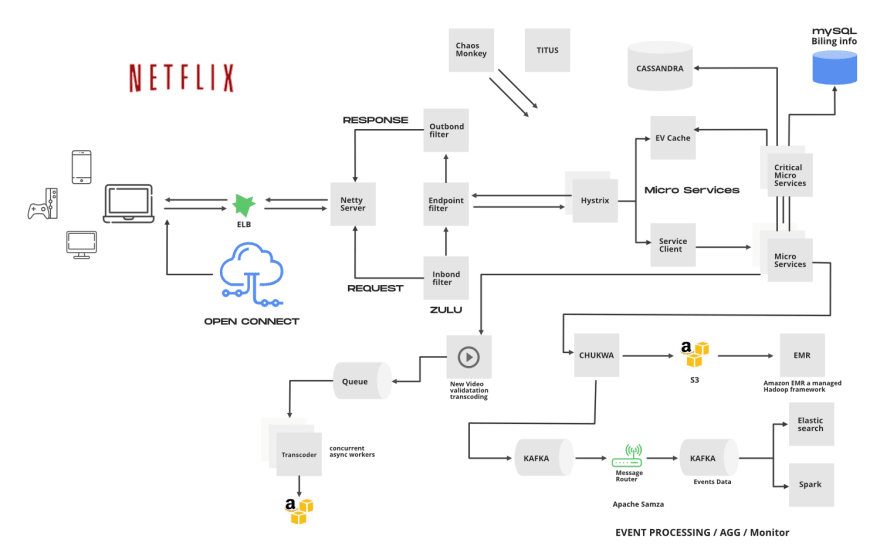
Flow работает следующим образом:
- Клиент отправляет запрос на воспроизведения видео к серверу, который работает на AWS. Netflix использует сервис Amazon Elastic Load Balancer (ELB) для маршрутизации трафика к сервисам.
- AWS ELB перенаправит этот запрос в API Gateway Service. Netflix использует Zuul в качестве API gateway, который создан для обеспечения динамического роутинга, мониторинга трафика и безопасности, а также устойчивости к сбоям на границе облачного развертывания.
- Application API component - это основная бизнес-логика операций Netflix. У нетликс несколько типов API, соответствующих различным действиям пользователя, например API регистрации, API дискавери / рекомендации для получения рекомендаций по видео. В этом сценарии перенаправленный запрос от API Gateway Service обрабатывается Play API.
- Play API вызовет микросервис или цепочку микросервисов для выполнения запроса.
- Микросервисы - в основном небольшие программы без сохранения состояния (stateless), которые также могут вызывать друг друга. Чтобы контролировать "cascading failure" и обеспечить отказоустойчивость, каждый микросервис изолируется от вызывающих процессов с помощью Hystrix.
- Микросервисы могут сохранять или получать данные из data store во время обработки.
- Микросервисы могут отправлять ивенты для отслеживания действий пользователей или другие данные в Stream Processing Pipeline для обработки персонализированных рекомендаций в реальном времени или пакетной обработки задач бизнес-аналитики.
- Данные, поступающие из Stream Processing Pipeline, могут быть постоянными для других хранилищ данных, таких как AWS S3, Hadoop HDFS, Cassandra и т.д.
Архитектура воспроизведения видео
верхнеуровнево это выглядит следующим образом:
- OCAs (Open Connect Appliances) постоянно отправляет отчеты о состоянии своей рабочей нагрузки, возможности маршрутизации и доступных видео в Cache Control сервис, работающую в AWS EC2, чтобы приложения для воспроизведения могли обновлять клиентам последние исправные OCA.
- Юзер на своем устройстве запрашивает воспроизведение (телешоу или фильма) из приложения Netflix в AWS.
- Netflix playback сервис чекает авторизацию, разрешение и лицензию пользователя, а затем выбирает файлы для обслуживания клиента с учетом текущей скорости сети и разрешения.
- Роутинг сервис выбирает OCA, из которого должны обслуживаться файлы, генерирует URL-адреса для этих OCA и возвращает его playback сервису.
- Playback сервис передает URL-адреса OCA клиенту. Клиент запрашивает видеофайлы из этого OCA.
Netflix получает видео в высоком качестве от киностудий. Поэтому перед тем, как передать видео пользователям, он выполняет некоторую предварительную обработку. Netflix поддерживает более 2200 устройств, и для каждого из них требуются разные разрешения и форматы. Чтобы видео можно было просматривать на разных устройствах, Netflix выполняет перекодирование или кодирование, которое включает в себя поиск ошибок и преобразование исходного видео в разные форматы и разрешения:
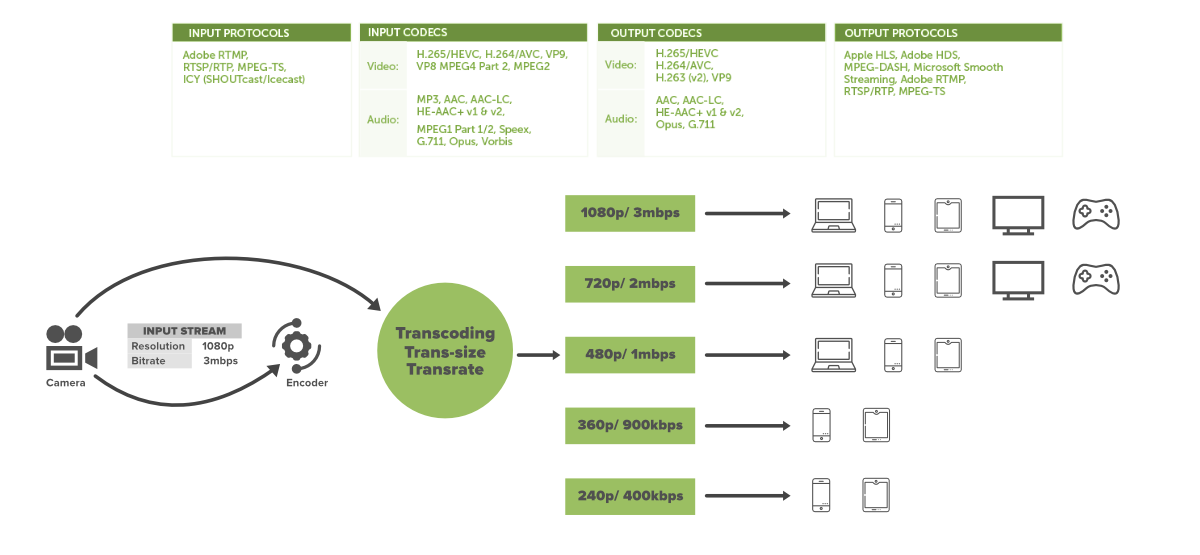
Disclaimer: картинка, которую я взял с источника старая, и конечно сейчас нетфликс суппортит уже 4k.
API Gateway
Netflix использует сервис Amazon Elastic Load Balancer (ELB) для маршрутизации трафика к сервисам. ELB настроены таким образом, что сначала нагрузка распределяется по зонам, а затем по экземплярам.
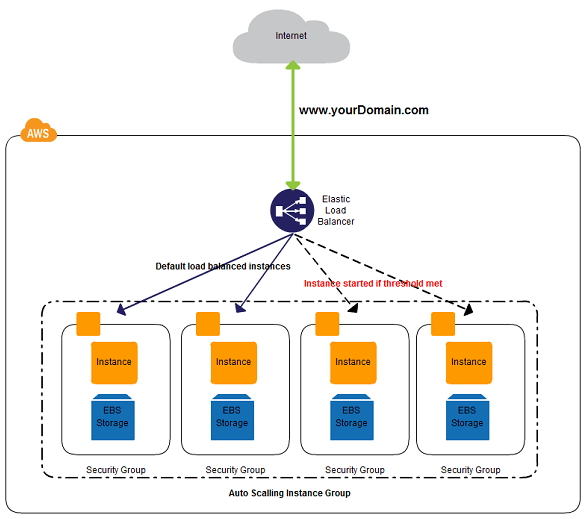
Этот балансировщик нагрузки направляет запрос на API gateway service; Netflix использует Zuul в качестве API gateway, он создан командой нетфликс. Zuul обрабатывает все запросы и выполняет динамическую маршрутизацию приложений микросервисов. Он работает как "входная дверь" для всех запросов.
Команда Cloud Gateway в Netflix запускает и управляет более чем 80 кластерами Zuul 2, отправляя трафик примерно на 100 (и постоянно растущих) серверных сервисных кластеров, которые составляют более 1 миллиона запросов в секунду.
Как работает Zuul 2
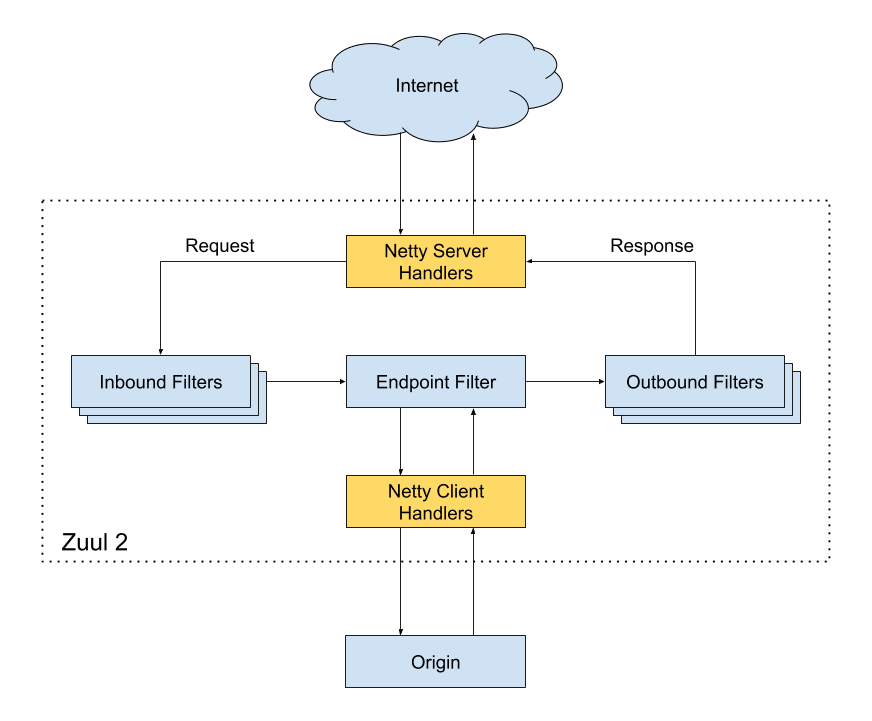
- Netty Server – берет на себя ответственность за работу с сетевым протоколом, веб-сервером, управлением соединениями и прокси. Когда запрос попадет на сервер Netty, он передаст запрос к Inbound filter.
- Inbound filter – отвечает за аутентификацию, маршрутизацию или оформление запроса. Затем он пересылает запрос на endpoint filter
- Endpoint filter – используется для возврата статического ответа или для пересылки запроса на бекенд сервис (Origin на диаграмме). Получив ответ от Origin, он отправляет запрос на outbound filter.
- Outbound filter – используется для сжатия содержимого, подсчета метрик или добавления / удаления кастом хэдеров. После этого ответ отправляется обратно на сервер Netty, а затем его получает клиент.
Преемущества Zuul
- Вы можете создать несколько правил и сегментировать трафик, распределяя различную часть трафика на разные серверы.
- Разработчики также могут проводить нагрузочное тестирование недавно развернутых кластеров на некоторых машинах. Они могут направлять некоторый существующий трафик на эти кластеры и проверять, какую нагрузку может выдержать конкретный сервер.
- Тестирование новых сервисов. Когда вы обновляете сервис и хотите проверить, как она ведет себя с запросами API в реальном времени, в этом случае вы можете развернуть конкретный сервис на одном сервере и перенаправить некоторую часть трафика на этот сервис, чтобы проверить сервис в режиме реального времени.
- Фильтр 'bad request'a", можно устанавливать кастомные рулы, в эндпоинт фильтре или фаерволле.
Application API
Сейчас АПИ можно разделить на 3 категории:
- Signup API
- Discovery API
- Play API
Если мы рассмотрим пример флоу пользователя у которого есть подписка. Предположим, что пользователь нажимает кнопку воспроизведения для последней серии «Острых козырьков», запрос будет перенаправлен на Play API. В свою очередь API, вызывает под капотом несколько микросервисов. Некоторые из этих вызовов можно совершать параллельно, потому что они не зависят друг от друга. Остальные должны быть упорядочены в определенном порядке. API содержит всю логику для упорядочивания и распараллеливания вызовов по мере необходимости. Устройству, в свою очередь, не нужно ничего знать об оркестровке, которая происходит под капотом, когда юзер нажимает кнопку Play.
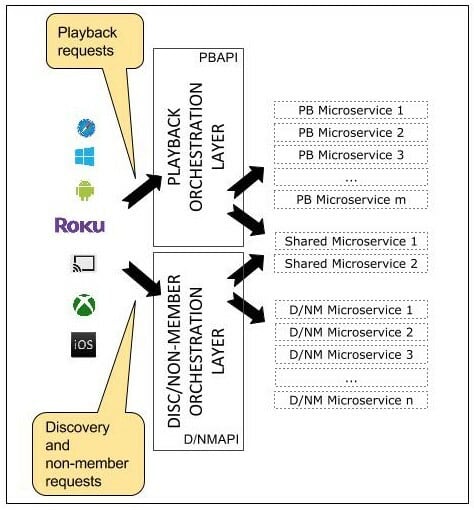
- В недавнем обновлении реализации Play API сетевой протокол между Play API и микросервисами - это gRPC / HTTP2, который позволяет работать по RPC с помощью Protocol Buffers, а клиентские библиотеки / SDK автоматически генерируются на различных языках». Это позволяет Application API интегрироваться с автоматически сгенерированными клиентами посредством "bi-directional communication" и «минимизировать повторное использование кода через service boundaries».
- Application API также предоставляет общий устойчивый механизм, основанный на командах Hystrix, про него читайте ниже.
Hystrix - Distributed API Services Management
В любых distributed системах с большим количеством зависимостей неизбежно сервисы начнут "отваливаться" Отслеживать работоспособность и состояние всех сервисов может быть сложно, поскольку все больше и больше сервисов будут запускаться, а некоторые сервисы могут быть отключены или просто выйти из строя. Hystrix предлагает удобную панель управления.
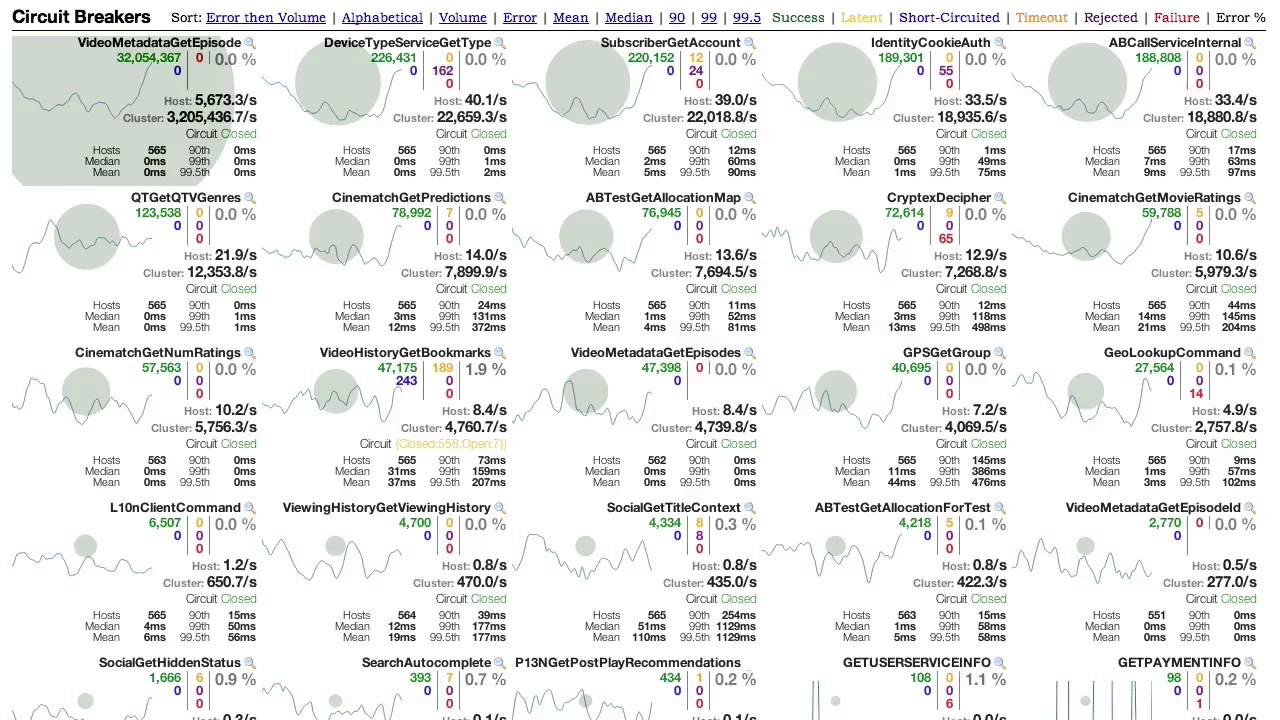
Библиотека Hystrix используется для управления взаимодействием между этими распределенными сервисами путем добавления некоторой логики устойчивости к задержкам и отказоустойчивости.
Рассмотрим этот пример от Netflix, у них есть микросервис, который предоставляет пользователю индивидуальный список фильмов. В случае сбоя сервиса они перенаправляют трафик, чтобы обойти сбой, на другой ванильный микросервис, который просто возвращает 10 лучших фильмов, подходящих для семейного просмотра. Таким образом, у них есть безопасное аварийное переключение, к которому они могут перейти, и это классический пример circuit breaking.
Microservices
Структурная составляющая микросервиса в нетфликс выглядит следующим образом:
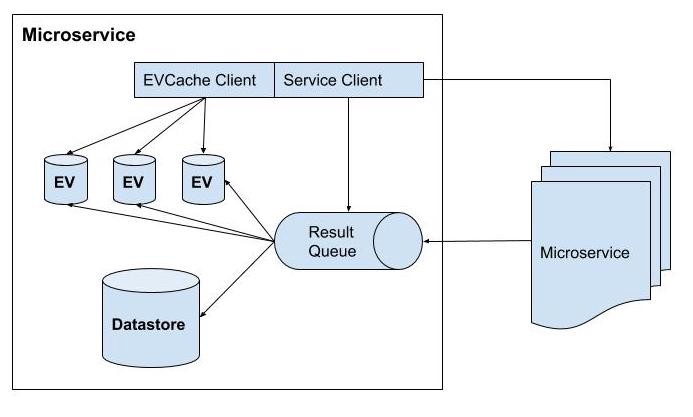
- Микросервис может работать сам по себе или вызывать другие микросервисы через REST или gRPC.
- Каждый микросервис может иметь собственное хранилище данных и несколько кеш-хранилищ последних результатов в памяти. EVCache - это основной выбор для кэширования микросервисов в Netflix.
Клиент
Технари Netflix разработали апликейшины которые работают на ноутбуках, настольных компьютерах или мобильных устройствах. Даже на некоторых смарт-телевизорах, в которых Netflix не имеет специализированного клиента, Netflix по-прежнему контролирует его производительность с помощью предоставленного SDK. Фактически, любая среда устройства должна установить платформу Netflix Ready Device Platform (NRDP), чтобы обеспечить наилучшее качество просмотра Netflix. Структура клиента выглядит следующим образом:
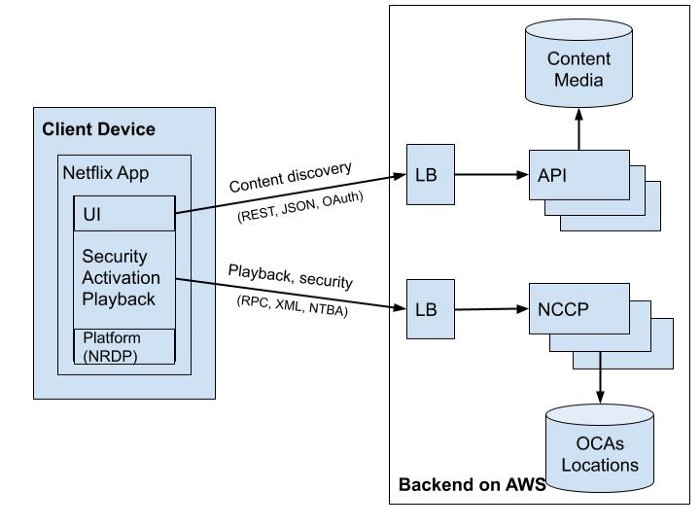
- Клиентские приложения разделяют 2 типа подключений к Backend'у: content discovery и воспроизведение контента. Клиент использует протокол NTBA для запросов на воспроизведение, чтобы обеспечить большую безопасность на своих серверах OCA и устранить задержку, вызванную handshak'ом SSL/TLS для новых подключений.
- При стримминге видео клиентское приложение может снижать качество видео или переключается на другие серверы OCA, если сетевые соединения перегружены или имеют ошибки. Даже если подключенный OCA перегружен или вышел из строя, клиентское приложение может легко переключиться на другой сервер OCA для лучшего просмотра. Все это может быть достигнуто благодаря тому, что SDK платформы Netflix на клиенте отслеживает последние исправные OCA, полученные из сервиса Playback Apps.
Хранилища данных
EVCache
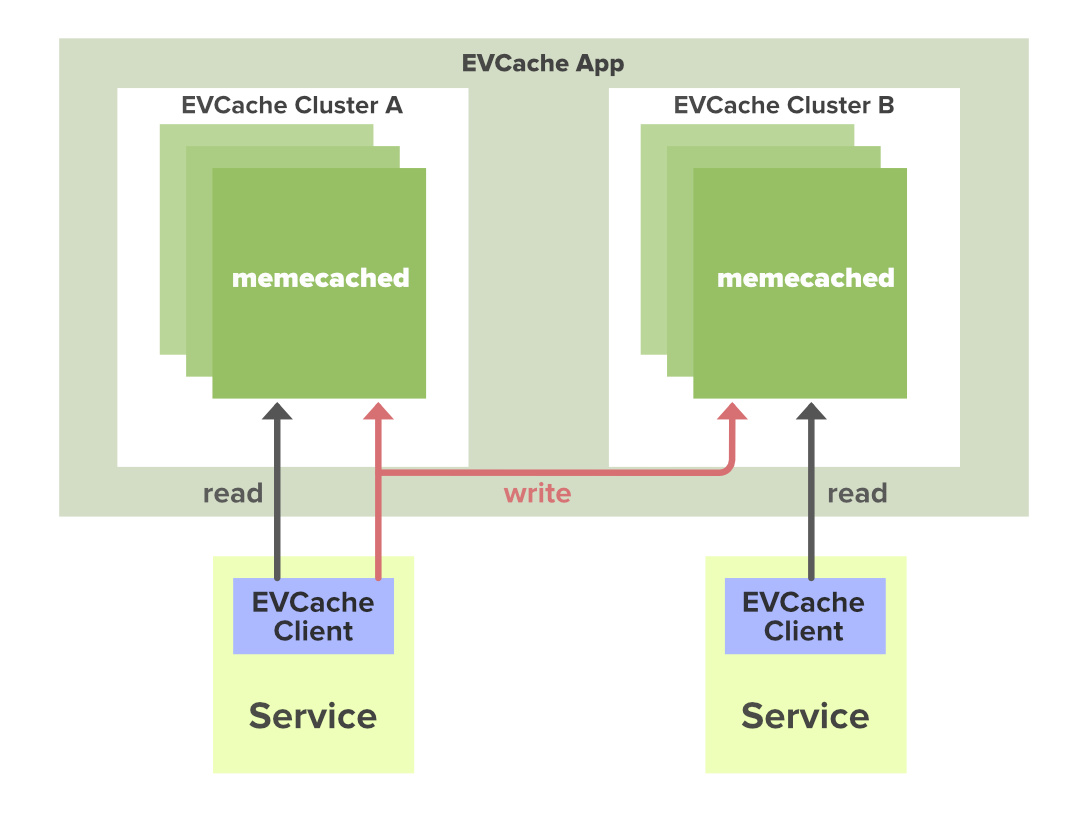
В большинстве приложений юзается БД с некоторым объем данных. Для более быстрого ответа эти данные могут быть закэшированы. Это снижает нагрузку на исходный сервер, но проблема в том, что если такой узел выходит из строя, весь кеш выходит из строя, и это может сказаться на производительности приложения. Чтобы решить эту проблему, Netflix создал собственный слой кэширования, который называется EV cache. Кэш EV основан на Memcached и фактически является "враппером" для Memcached.
EVCache - это решение для кэширования на основе memcached и spymemcached, которое в основном используется в инфраструктуре AWS EC2 для кэширования часто используемых данных.
EVCache - это сокращение от:
Ephemeral - данные хранятся в течение короткого периода времени, как указано в их TTL (время жизни).
Volatile - данные могут исчезнуть в любой момент.
Cache - хранилище ключей и значений в памяти.
Два варианта использования кеширования:
- Обеспечивает быстрый доступ к часто сохраняемым данным.
- Обеспечивает быстрый доступ к "computed data". Микросервисы Netflix используют кеши для быстрого и надежного доступа к разным типам данных, таким как история просмотров, рейтинги и персональные рекомендации для юзеров.
MySQL
Netflix использует для MySQL инстансы AWS EC2 для своей биллинговой инфраструктуры. Инфраструктура биллинга отвечает за управление состоянием биллинга юзеров Netflix. Это включает в себя отслеживание неоплаченых/ оплаченных биллингов, сумму кредита на счете участника, управление статусом оплаты участника, инициирование запросов на оплату и дату, через которую участник произвел оплату.
Netflix сохраняет такие данные, как платежная информация, информация о пользователях и транзакциях, в MySQL, поскольку для этого требуется соответствие ACID. Netflix имеет настройку master-master для MySQL.
Apache Cassandra
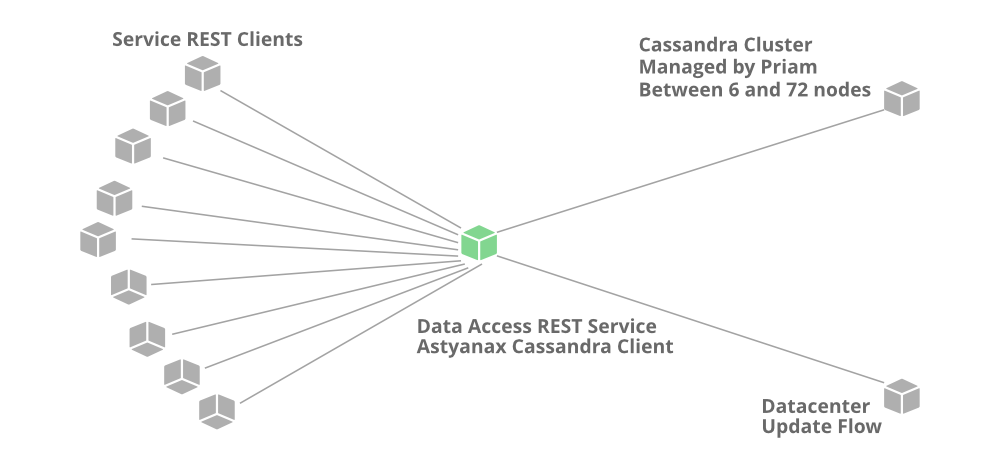
Cassandra - это бесплатная база данных NoSQL с открытым исходным кодом для распределенного хранилища данных, предназначенная для обработки больших объемов данных на многих стандартных серверах.
Netflix использует Cassandra из-за ее масштабируемости, отсутствия единых точек отказа и межрегионального развертывания. По сути, один глобальный кластер Cassandra может одновременно обслуживать приложения и асинхронно реплицировать данные в нескольких географических точках. Netflix хранит все виды данных в своих экземплярах Cassandra DB. Все ивенты собранные пользователями, хранятся в Cassandra.
Поскольку объем данных юзеров начал увеличиваться, потребовался более эффективный способ управления хранилищем данных. Netflix переработала архитектуру хранения данных с двумя основными целями:
- Меньший размер хранилища.
- Стабильная производительность чтения/записи по мере роста количества просмотров у каждого юзера.
Решением проблемы с большими объемами данных стало сжатие старых строк. Данные были разделены на два типа:
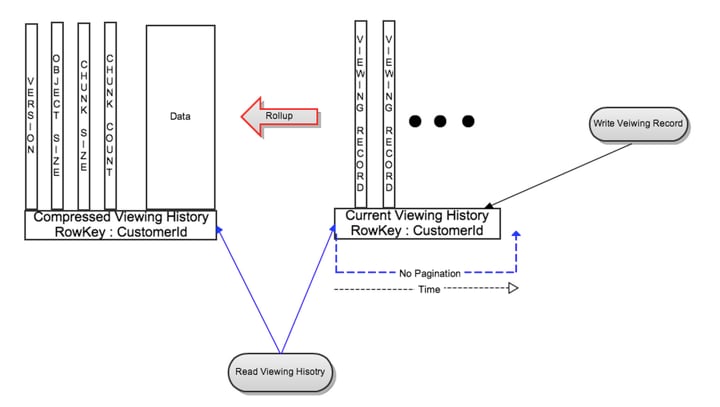
- Live Viewing History (LiveVH): небольшое количество недавних записей. Данные хранятся в несжатом виде.
- Compressed Viewing History (CompressedVH): большое количество старых записей с редкими апдейтами. Данные сжимаются, чтобы уменьшить занимаемое хранилище. Сжатая история просмотров хранится в отдельном столбце для каждого ключа строки.
Stream Processing Pipeline
Apache Kafka
Kafka - это программное обеспечение с открытым исходным кодом, которое обеспечивает основу для хранения, чтения и анализа streaming data.
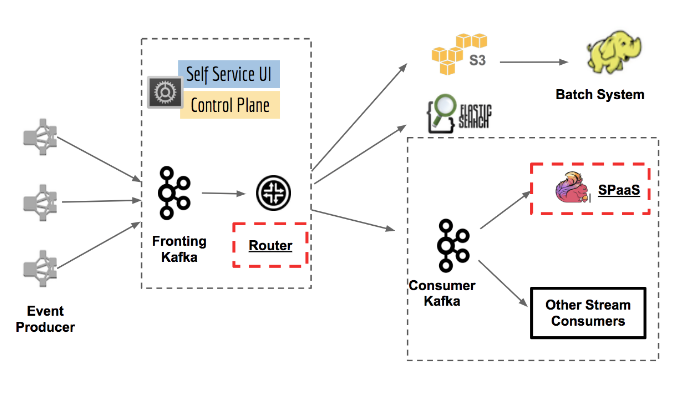
У Netflix Apache Kafka юзается как стандарт обработки ивентов, обмена сообщениями и стримминга. Платформа потоковой обработки обрабатывала триллионы событий и петабайты данных в день. Он также будет автоматически масштабироваться по мере увеличения количества подписчиков.
- Модуль Router обеспечивает маршрутизацию к различным "приемникам данных" или приложениям, в то время как Kafka отвечает за маршрутизацию сообщений, а также за буферизацию для нисходящих систем.
- Stream Processing as a Service (SPaaS) позволяет инженерам по обработке данных создавать и контролировать свои custom managed stream processing applications, в то время как платформа позаботится о масштабируемости и операциях.
Apache Chukwe
Apache Chukwe - это система сбора данных с открытым исходным кодом для сбора логов или событий из распределенной системы. Он построен на основе HDFS и фреймворка Map-reduce. Он обладает функциями масштабируемости и надежности Hadoop. Он включает в себя множество мощных и гибких инструментов для отображения, мониторинга и анализа данных. Chukwe собирает события из разных частей системы; Из Chukwe вы можете выполнять мониторинг, анализ или использовать панель управления для просмотра событий. Chukwe записывает событие в формате последовательности файлов Hadoop (S3).
Apache Spark
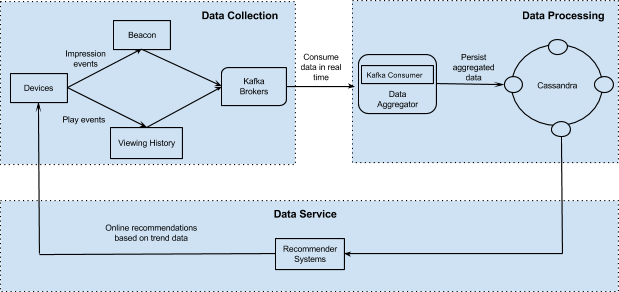
Netflix использует Apache Spark и машинное обучение для механизма рекомендации фильмов. Apache Spark - это единый аналитический движок с открытым исходным кодом для large-scale data процессинга.
По запросу пользователя в реальном времени, агрегированные данные о популярности воспроизведения (сколько раз воспроизводится видео) и скорости воспроизведения (доля событий воспроизведения по сравнению с событиями показа для данного видео) вместе с другими явными сигналами, такими как история просмотров участников и прошлые рейтинги. используются для вычисления персонализированного контента для пользователя. На изображении ниже показана сквозная инфраструктура для создания рекомендаций по фильмам для пользователей.
Elastic Search
В последние годы мы наблюдаем значительный рост использования Elasticsearch в Netflix. Netflix работает примерно со 150 кластерами эластичного поиска и 3500 хостами с инстансами.
Netflix использует Elastic Search для визуализации данных, customer support и обнаружения ошибок в системе. С помощью Elastic Search Netflix по сути трекают состояние системы и устраняют неполадки в логах ошибок и сбоях.
Источники: