Обзор архитектуры: Real-Time Streaming Processing в Linkedin


Перевод статьи с блога Linkedin, как они построили Real-Time Streaming Processing который суппортит нагрузку в 4 триллиона ивентов в день.
Background
В LinkedIn Apache Beam играет ключевую роль в инфраструктуре stream processing'а, которая ежедневно обрабатывает более 4 триллионов событий с помощью 3000+ пайплайнов в нескольких прод дата центрах. Этот фреймворк обеспечивает обработку данных практически в режиме реального времени для критически важных сервисов и платформ, начиная с машинного обучения и уведомлений и заканчивая моделированием искусственного интеллекта для защиты от злоупотреблений. С более чем 950 миллионами пользователей, обеспечение бесперебойной работы платформы имеет решающее значение для подключения пользователей к возможностям по всему миру.
Apache Beam позволила реализовать множество сложных сценариев использования и произвела революцию в потоковой обработке данных в LinkedIn. Эта технология позволила в 2 раза оптимизировать стоимость обслуживания за счет Unified Stream и batch processing с помощью Apache Samza и Apache Spark, обеспечить генерацию функций ML в реальном времени, сократить время подготовки новых конвейеров с нескольких месяцев до нескольких дней, обрабатывать временные серии событий со скоростью более 3 миллионов запросов в секунду и многое другое.
LinkedIn Open-Source Ecosystem и путь к Beam
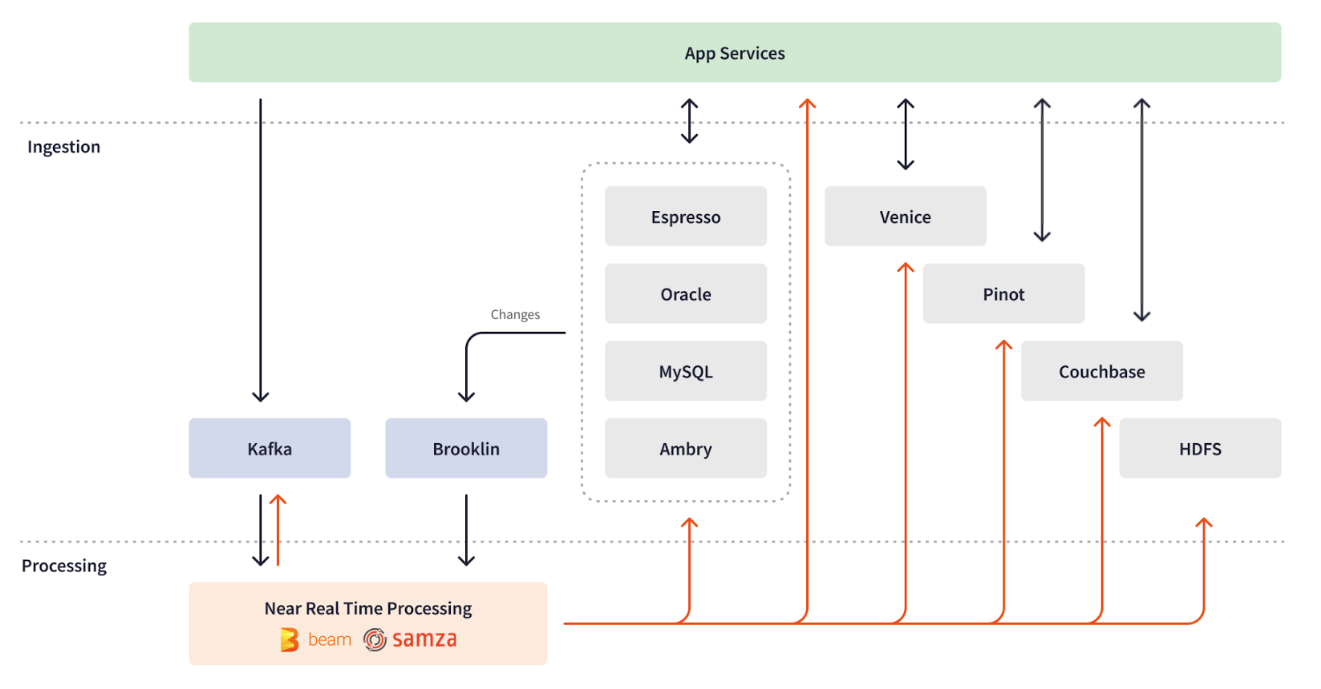
Чтобы запроцессить большое количество данных, Линкедин создала собственную систему обработки данных, которую они потом опенсорснули, вы ее знаете под названием Apache Kafka. В целом linkedin опенсорсила и контрибютила в более чем 75 опенсорс проектов. Чтобы перейти от batch processing и реагировать на события Kafka в течение нескольких минут или секунд, они создали собственный фреймворк распределенной потоковой обработки событий Apache Samza. Этот фреймворк, наряду с Apache Spark для пакетной обработки, лег в основу LinkedIn’s lambda architecture для выполнения заданий по обработке данных. Со временем команда инженеров LinkedIn расширила экосистему потоковой обработки данных, добавив в нее такие собственные инструменты, как Brooklin, обеспечивающий потоковую передачу данных через различные хранилища и системы обмена сообщениями, другие.
Экосистема с Apache Samza в качестве основы позволяла обрабатывать данные в больших масштабах, постоянно растущие требования LinkedIn требовали большей масштабируемости и эффективности, а также снижения задержек в потоках данных. Lambda architecture приводила к сложностям в эксплуатации и неэффективности из-за необходимости поддерживать два кодбейза и два разных движка для batch и stream обработки данных. Чтобы решить эти проблемы, инженеры искали более высокий уровень абстракции для stream processing и встроенную поддержку сложных агрегаций и преобразований. Им также была нужна возможность экспериментировать с потоковыми пайплайнами в batch режиме и поддержка мультиязычности, особенно для машинного обучения на Python.
Выпуск Apache Beam в 2016 году стал переломным моментом для LinkedIn. Apache Beam предоставляет открытую, унифицированную модель программирования для batch и stream обработки, позволяя создавать общую инфраструктуру данных в различных приложениях. С поддержкой SDK для Python, Go и Java, а также универсальным API, Apache Beam хорошо подошел для создания сложных мультиязычных пайплайнов и их запуска на любом движке.
Поняв преимущества унифицированного API обработки данных Apache Beam, его продвинутых возможностей и поддержки множества языков, LinkedIn начал применять его для первых задач и разработал Samza runner для Beam в 2018 году. К 2019 году пайплайны Apache Beam обеспечивали работу нескольких критически важных задач
Варианты использования Apache Beam в LinkedIn
Unified Streaming And Batch Pipelines
Некоторые из первых задач, которые LinkedIn перенес на пайплайны Apache Beam, включали как вычисления в реальном времени, так и периодическое наполнение данными. Примером может служить процесс стандартизации LinkedIn, включающий в себя серию пайплайнов, использующих сложные AI модели для преобразования пользовательских данных, таких как должность, навыки или образование, в предопределенные внутренние идентификаторы. Например, должность пользователя "Chief Data Scientist" стандартизируется для релевантных рекомендаций по работе.
Процесс стандартизации LinkedIn требует как обработки в реальном времени для отражения немедленных обновлений пользователей, так и данных при введении новых AI моделей. Перед переходом на Apache Beam, выполнение наполнения данных для потоковой задачи требовало более 5,000 GB-часов памяти и почти 4,000 часов общего времени CPU. Эта нагрузка приводила к увеличенному времени работы джобы и проблемам масштабирования, из-за чего пайплайн становился "шумным соседом" для соседних stream пайплайнов, не справляясь с требованиями к задержке и пропускной способности. Хотя инженеры LinkedIn рассматривали возможность переноса логики наполнения данными на пакетный пайплайн Spark, они отказались от этой идеи из-за ненужной нагрузки на поддержку двух разных код бейзов.
Чел с линкедин:
«Мы пришли к вопросу: возможно ли поддерживать только одну кодовую базу, но с возможностью запуска ее как в пакетном, так и в потоковом режиме? Решением стала унифицированная модель Apache Beam.
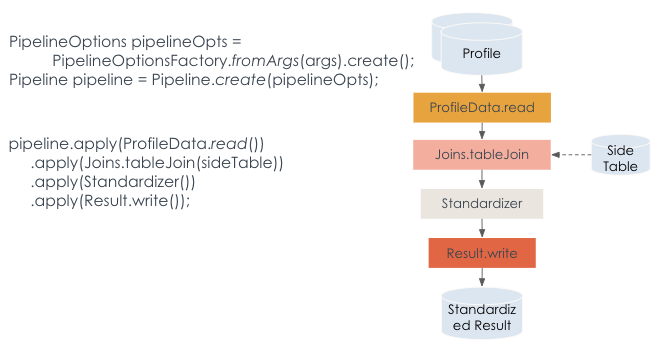
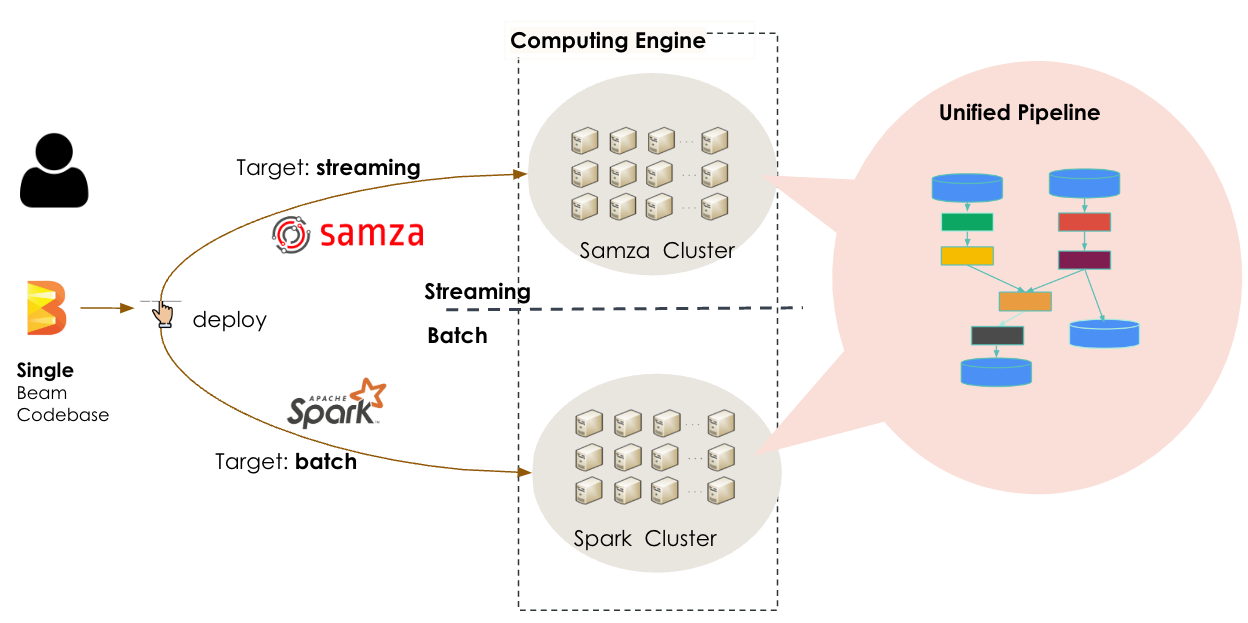
API Apache Beam позволил инженерам LinkedIn реализовать бизнес-логику один раз в унифицированном пайплайне, эффективно обрабатывая как стандартизацию в реальном времени, так и наполнение данных. Apache Beam предлагает PipelineOptions для настройки различных аспектов, например, исполнителя пайплайна и специфических настроек. Расширяемость трансформаций Apache Beam позволила LinkedIn создать настраиваемую композитную трансформацию для абстракции от различий ввода/вывода и переключения целевой обработки на лету в зависимости от типа источника данных bounded/unbounded. Кроме того, абстракция от базовой инфраструктуры и возможность "написать один раз и запустить где угодно" дали LinkedIn возможность без проблем переключаться между движками обработки данных. В зависимости от типа обработки, потоковой или пакетной, унифицированный пайплайн стандартизации Apache Beam может быть развернут через кластер Samza как потоковая задача или через кластер Spark как пакетная задача по заполнению данных.
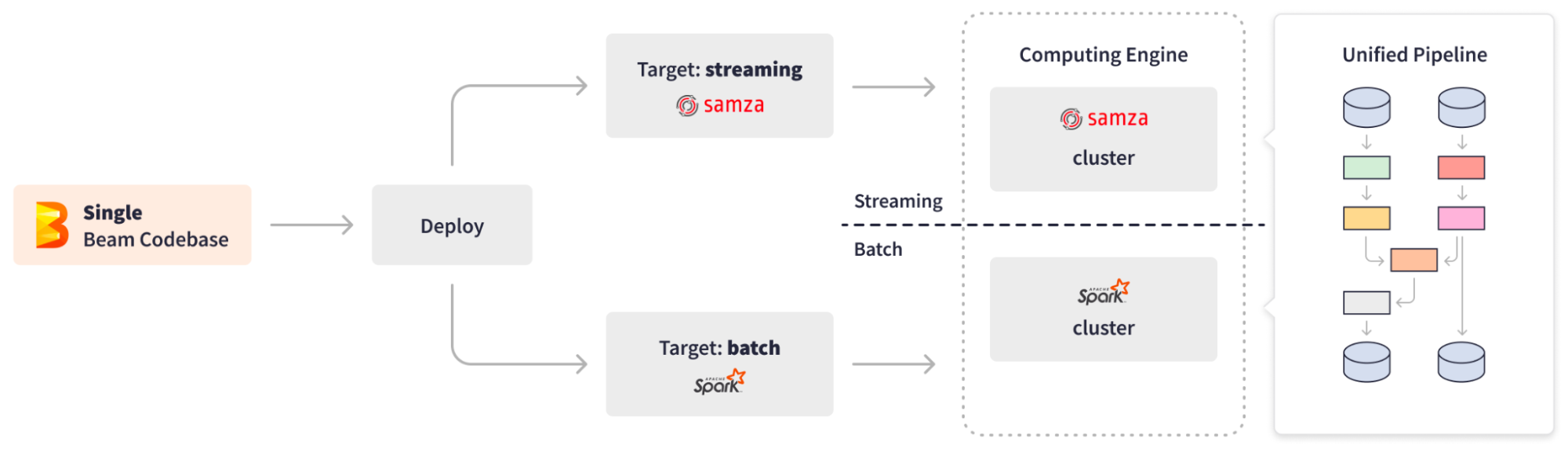
Сотни streaming jobs в Apache Beam теперь обеспечивают стандартизацию в реальном времени, отслеживая события 24/7, обогащая потоки дополнительными данными из удаленных таблиц, выполняя необходимую обработку и записывая результаты в выходные базы данных. Пакетная задача Apache Beam выполняется еженедельно, эффективно обрабатывая 950 миллионов профилей пользователей со скоростью более 40,000 профилей в секунду. Apache Beam вносит данные в сложные AI и машинные модели обучения и соединяет сложные данные, такие как типы работ и профессиональный опыт, стандартизируя данные пользователей для индексации поиска или запуска рекомендательных моделей.
Перенос логики заполнения данных на унифицированный пайплайн Apache Beam и его выполнение в пакетном режиме привело к значительному улучшению эффективности использования памяти и CPU на 50% (с ~5000 GB-часов и ~4000 часов CPU до ~2000 GB-часов и ~1700 часов CPU) и впечатляющему ускорению времени обработки на 94% (с 7.5 часов до 25 минут). Больше деталей об этом случае использования можно в блоге LinkedIn.
Anti-Abuse & Near Real-Time AI Modeling
LinkedIn настроен на создание надежной среды для пользователей. Чтобы достичь этого, команда по борьбе со злоупотреблениями AI в LinkedIn играет ключевую роль в создании, развертывании и поддержке моделей искусственного интеллекта и глубокого обучения, способных обнаруживать и предотвращать различные формы злоупотреблений, такие как создание фальшивых аккаунтов, скрапинг профилей пользователей, автоматизированный спам и захват аккаунтов.
Apache Beam укрепляет внутреннюю платформу LinkedIn, Chronos, позволяя обнаруживать и предотвращать злоупотребления почти в реальном времени. Chronos использует два stream пайплайна Apache Beam: пайплайн фильтрации и пайплайн модели. filter job читает события пользовательской активности из Kafka, извлекает релевантные поля, агрегирует и фильтрует события, а затем генерирует отфильтрованные сообщения Kafka для последующей обработки AI. Затем model job потребляет эти отфильтрованные сообщения, агрегирует активность пользователей в определенных временных окнах, запускает модели оценки AI и записывает полученные результаты злоупотреблений в различные внутренние приложения, сервисы и хранилища для офлайн-обработки.
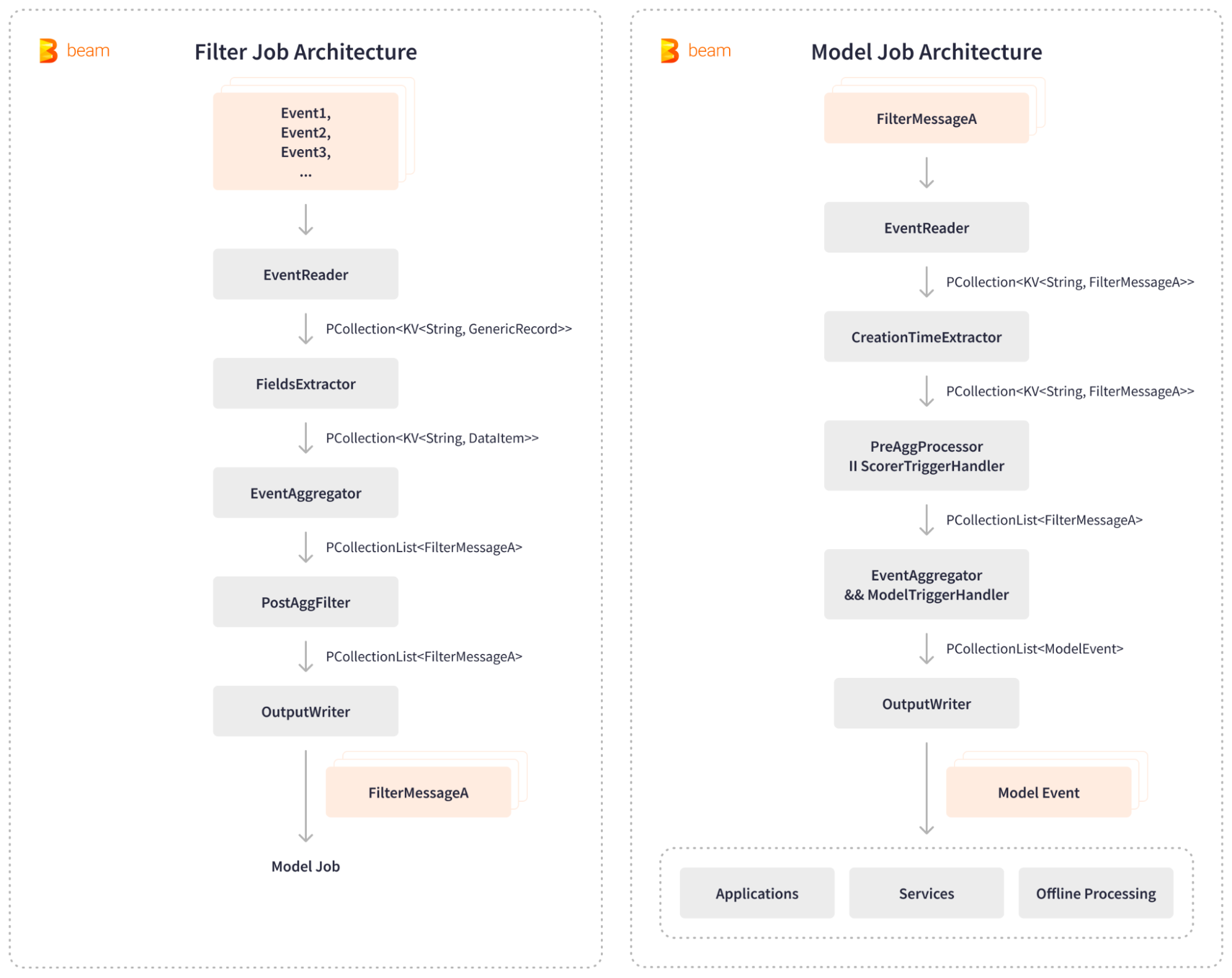
Гибкость подключаемой архитектуры Apache Beam и наличие вариации в I/O позволили легко интегрировать пайплайны Anti-Abuse системы с Kafka и хранилищами ключевых значений. LinkedIn значительно сократила время, необходимое для маркировки оскорбительных действий, с 1 дня до 5 минут и обрабатывает события со скоростью более 3 миллионов запросов в секунду. Apache Beam обеспечивает обработку данных в режиме, близком к реальному времени, что значительно повышает эффективность защиты LinkedIn от злоупотреблений. Система защиты, работающая в режиме близком к реальному времени, способна отлавливать скреперов в течение нескольких минут после того, как они начинают активность, что приводит к улучшению обнаружения залогиненных скреперов более чем на 6 %.
Платформа для уведомлений
Apache Beam pipelines помогают линкедину процесить механизм нотификаций для 950 милионов юзеров.
Real-Time ML Feature Generation
Функции в LinkedIn, такие, как рекомендации по работе и поисковая лента зависят от ML-моделей, которые используют тысячи функций, связанных с различными сущностями, такими как компании, вакансии и пользователи. Однако до внедрения Apache Beam первоначальный пайплайн генерации ML-функций страдал от задержки в 24-48 часов между действиями пользователей и влиянием этих действий на систему рекомендаций. Эта задержка приводила к упущенным возможностям, поскольку система не имела достаточных данных о нечастых пользователях и не могла уловить все ченджы. В ответ на растущий спрос на масштабируемую платформу для создания ML-функций в режиме реального времени LinkedIn обратилась к Apache Beam для решения этой проблемы.
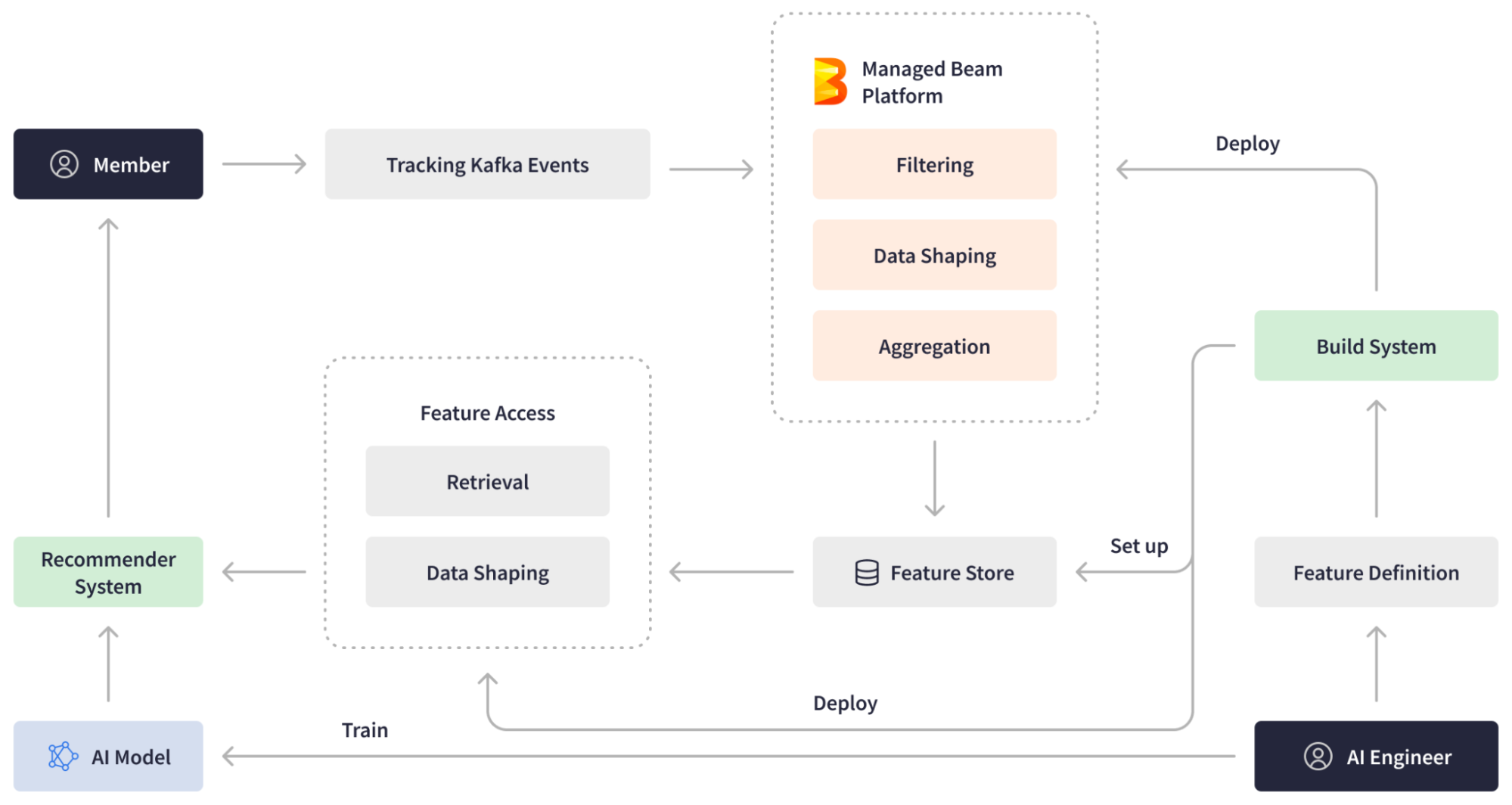
Используя Managed Beam в качестве основы, LinkedIn разработала платформу для генерации ML-функций. Платформа ML предоставляет инженерам ИИ функции в режиме реального времени и эффективный опыт создания конвейеров, при этом абстрагируясь от сложностей развертывания и эксплуатации. Инженеры ИИ создают определения функций и развертывают их с помощью Managed Beam. Когда пользователи LinkedIn совершают действия на платформе, Apache Beam streaming pipeline генерирует более свежие данные для машинного обучения, фильтруя, обрабатывая и агрегируя события, поступающие в Kafka в режиме реального времени, и записывает их в хранилище функций. Кроме того, LinkedIn внедрила другие пайплайны Apache Beam, отвечающие за получение данных из feature store, их обработку и передачу в рекомендательную систему.
Managed Streaming Processing Platform
По мере того как инфраструктура данных LinkedIn выросла до более чем 3,000 пайплайнов Apache Beam, команды AI и инженерии данных LinkedIn оказались перегружены управлением этими потоковыми приложениями 24/7. Инженеры AI столкнулись с несколькими техническими проблемами при создании новых пайплайнов, включая сложность интеграции множества streaming инструментов и инфраструктур в их фреймворки, а также ограниченные знания базовой инфраструктуры при развертывании, мониторинге и операциях. Эти проблемы приводили к долгому циклу разработки пайплайнов, который часто занимал от одного до двух месяцев. Apache Beam позволил LinkedIn создать Managed Beam — управляемую платформу обработки потоковых данных, которая призвана упростить и автоматизировать внутренние процессы. Эта платформа облегчает и ускоряет разработку и эксплуатацию сложных потоковых приложений, снижая при этом нагрузку на поддержку в режиме реального времени.
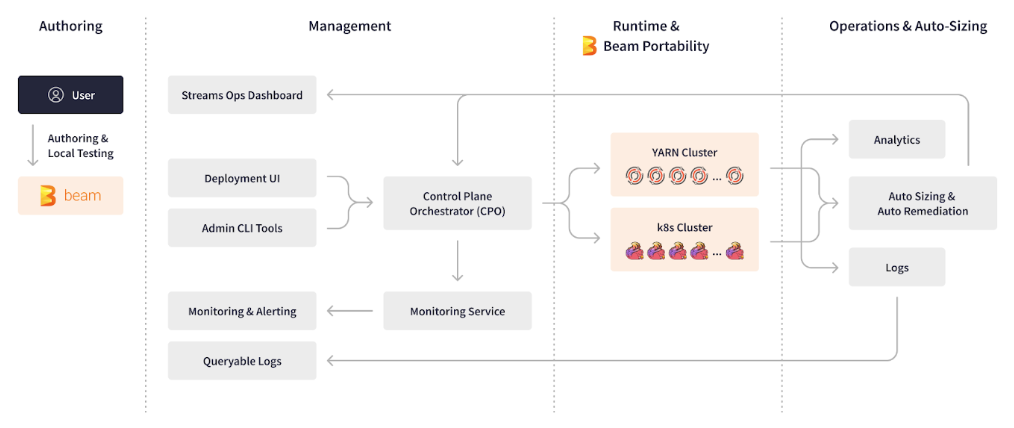
Расширяемость, подключаемость, переносимость и абстрактность Apache Beam легли в основу платформы LinkedIn Managed Beam. Платформа Managed Beam позволила сократить время создания, тестирования и стабилизации потоковых конвейеров с нескольких месяцев до нескольких дней, способствовала быстрому проведению экспериментов и почти полностью устранила операционные расходы для инженеров по искусственному интеллекту.
Итоги
Apache Beam трансформировал и масштабировал инфраструктуру данных LinkedIn, обеспечивая реальную обработку более 4 триллионов событий в день через 3,000 пайплайнов. Эта технология ускорила разработку и развертывание новых пайплайнов, значительно улучшила производительность и эффективность использования ресурсов и укрепила борьбу с злоупотреблениями на платформе. Благодаря своей гибкости и портативности, Apache Beam обеспечивает непрерывное улучшение и адаптацию LinkedIn к будущим изменениям, укрепляя его позиции как лидера в области профессиональных сетей с более чем 950 миллионами пользователей по всему миру.