DARWIN: Data Science и Artificial Intelligence Workbench в LinkedIn


За последние несколько лет data scientists и AI инженеры в LinkedIn использовали различные инструменты для работы с данными с помощью различных механизмов запросов и хранения для исследовательского анализа данных, экспериментов и визуализации. Но вскоре LinkedIn решили создать единую универсальную платформу для обработки данных, которая бы централизовала и обслуживала потребности разработки.
Решением было создать DARWIN: the Data Science and Artificial Intelligence Workbench at LinkedIn. DARWIN подходит для тех же сценариев использования, что и популярные платформы для обработки данных. Он использует экосистему Jupyter. В этой статье мы обсудим основные use-cases, где и как LinkedIn использует свою разработку и какую архитектуру она выбрала для постройки этого решения.
Мотивация для создания унифицированной data science платформы
Дата сайентисты и AI инженеры в LinkedIn использовали различные инструменты для работы с данными. Однако это создавало ряд проблем:
- Опыт разработчиков и простота использования: До появления DARWIN требовалось переключение контекста между несколькими инструментами, а совместная работа была затруднена, что снижало производительность.
- Фрагментация и разнообразие инструментов. Еще одной проблемой до DARWIN была фрагментация инструментов из-за "исторического использования" и личных предпочтений, что приводило к фрагментации знаний. Более того, приведение каждого инструмента в соответствие с политиками конфиденциальности и безопасности LinkedIn, особенно когда инструменты использовались локально, приводило к постоянно растущим накладным расходам.
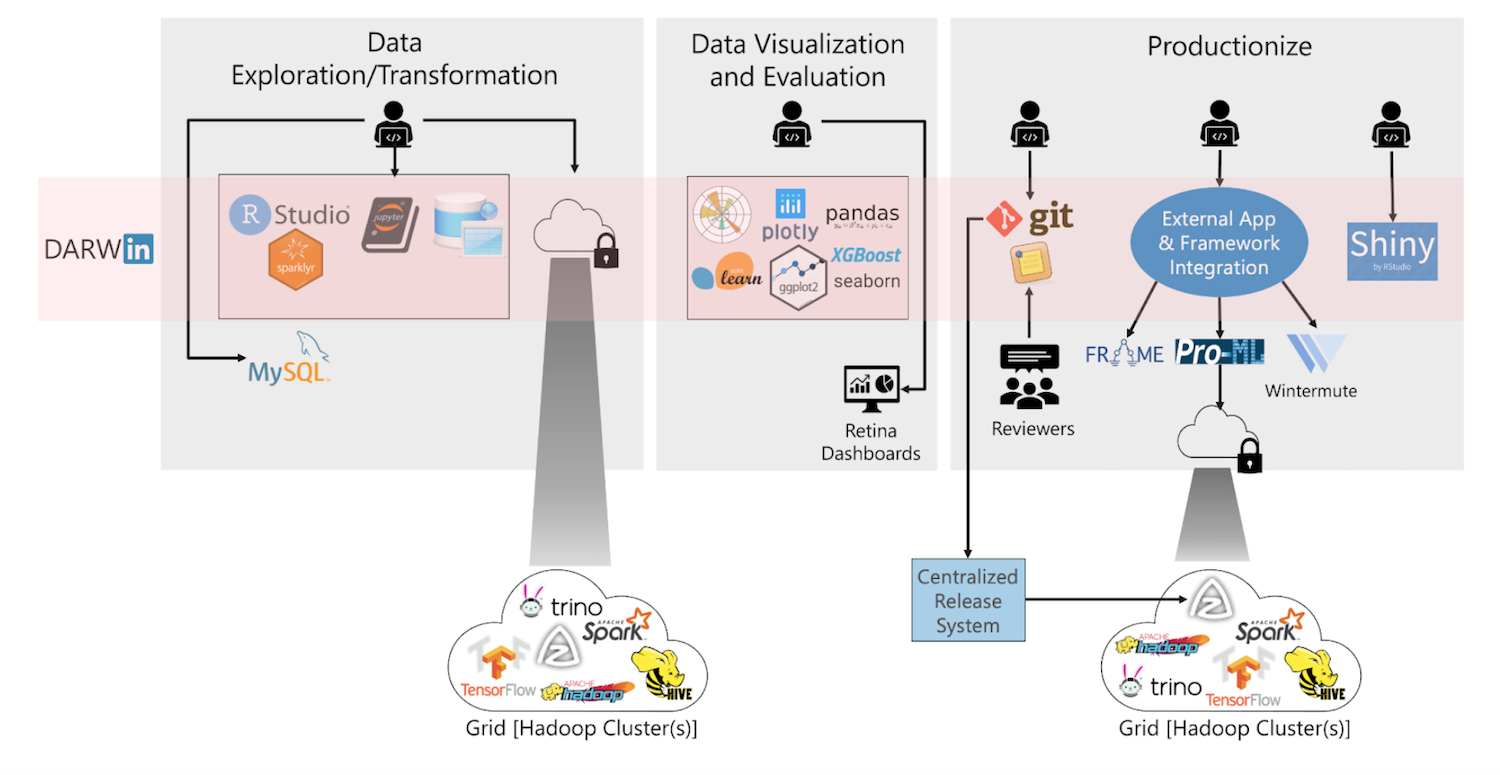
Чтобы действительно сделать DARWIN единым универсальным инструментом для всех, важно было покрыть различные этапы workflow, а также инструменты. К ним относятся:
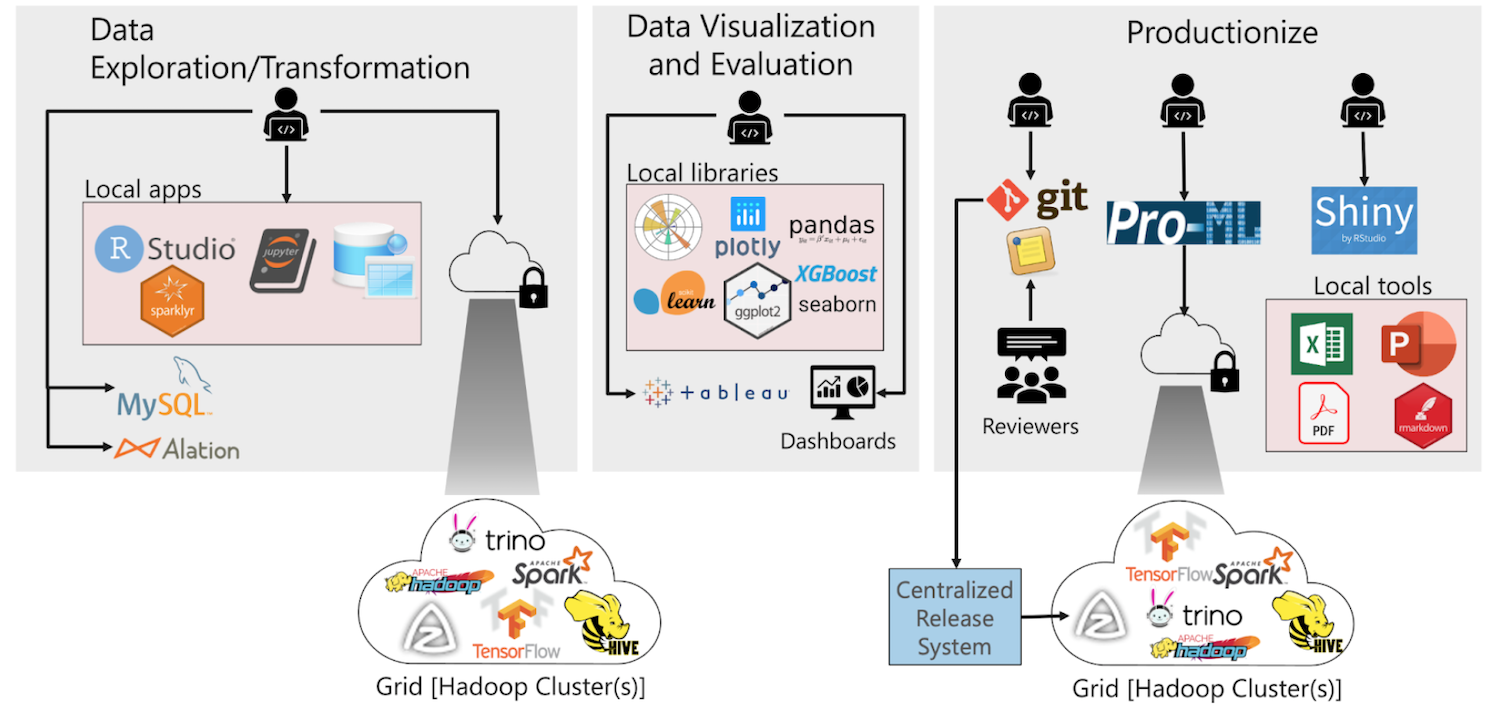
- Data exploration и transformation В то время как Дата сайентисты используют Jupyter Notebook на этом этапе и другие сотрудники как дата инженеры, менеджеры по продуктам и бизнес-аналитики используют SQL с помощью инструментов, таких как Alation и Aqua Data Studio. Некоторые бизнес-пользователи также используют Excel.
- Визуализация и оценка данных: это работает в основном на Jupyter Notebook. Инженеры ИИ также используют различные библиотеки машинного обучения, такие как GDMix , XGBoost и TensorFlow, для тренировки и оценки различных алгоритмов машинного обучения. Для визуализации данных и предоставления аналитических сведений LinkedIn юзают такие продукты, как Tableau и другие внутренние инструменты, ориентированные на разные типы пользователей, от инженеров до сейлзов.
- Productionizing: этот шаг может принимать форму планирования продакшн процесса в Azkaban или использования различных других инструментов и сред, таких как Frame или Pro-ML, для выполнения всего, от разработки функций до развертывания модели. Кроме того, написанный код должен быть проверен и помещен в репозиторий Git.
Создание DARWIN, платформы LinkedIn для анализа данных
После того как команда определила, что им нужна единая платформа для обработки и анализа данных, определили персонажей и инструменты на различных этапах разработки. Они также позиционировали DARWIN как платформу, которую партнерские команды могли бы использовать и развивать. На основании вышеизложенного был определен список ключевых требований к DARWIN:
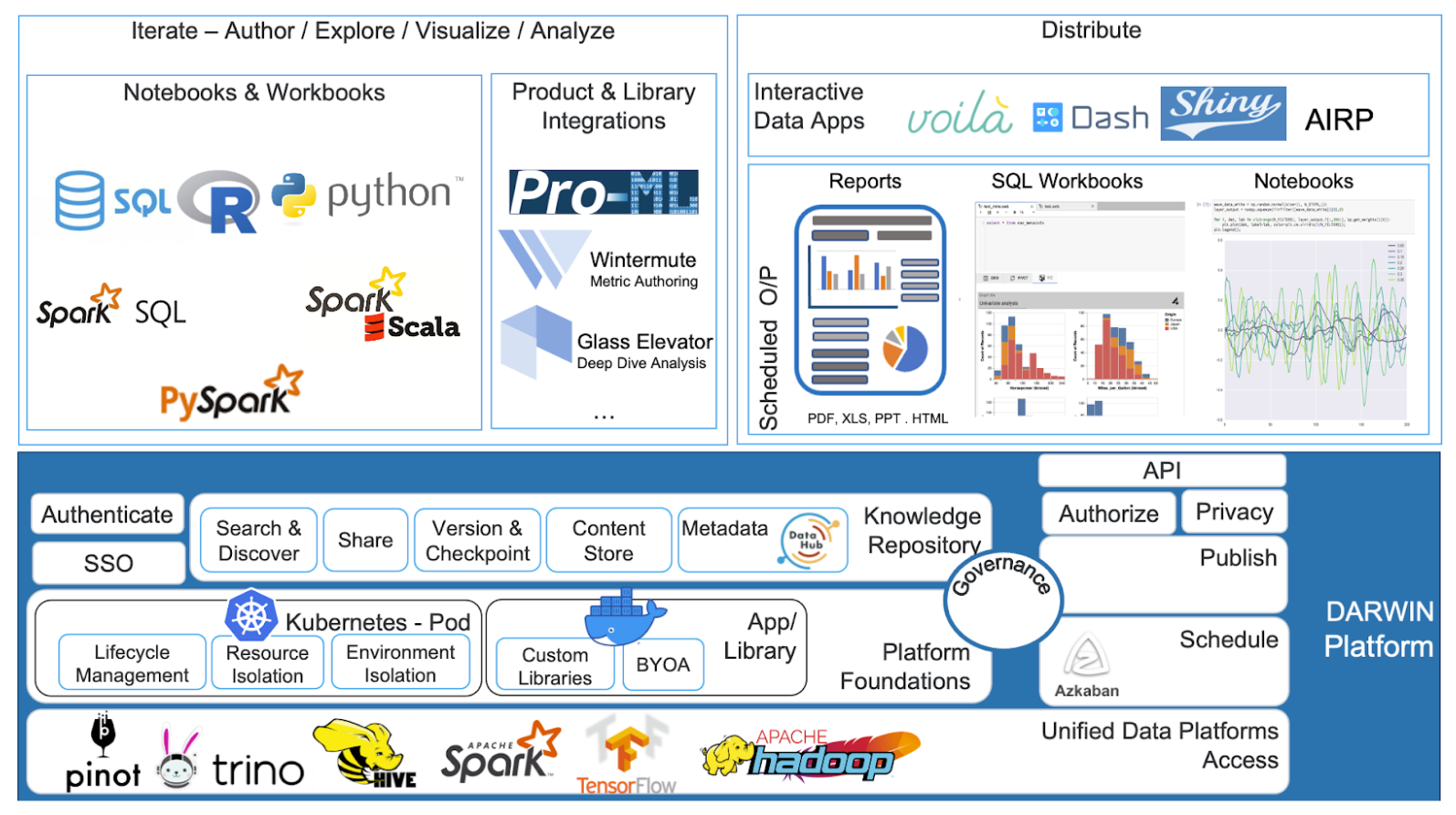
- Быть хостед платформой для анализа данных: DARWIN должна быть хостед платформой, действующей как entry point для всех механизмов обработки данных, удовлетворяя потребности исследовательского анализа данных, такие как анализ данных, визуализация данных и разработка моделей.
- Выполнять роль хранилища знаний и обеспечивать совместную работу: инженеры должны иметь возможность делиться своей работой и просматривать работу других в DARWIN. LinkedIn хотели создать возможность браузить работы других, датасеты и информацию о датасетах, а также создать каталог данных. DARWIN позволяет пользователям объединять артефакты с помощью тегов и создавать версии своих артефактов.
- Включает поддержку кода: пользователи могут кастомный код в DARWIN так же, как в среде IDE, с поддержкой нескольких языков, а также дает пользователям возможность коммитить свой код непосредственно в своих репозиториях проектов.
- Обеспечение управления, доверия, безопасности и комплаенса: DARWIN обеспечивает безопасный и соответствующий требованиям доступ к хосстед платформе в соответствии с принципом LinkedIn по созданию надежных решений.
- Управление планированием, паблишингом и дистрибуцией: пользователи должны иметь возможность планировать запуск исполняемых ресурсов DARWIN и генерировать результаты для повторяемого анализа на основе различных параметров. Пользователи также должны иметь возможность производить свою работу, публикуя окончательные результаты своего анализа в различных форматах и распространяя их среди заинтересованных сторон.
- Интеграция с другими инструментами и платформами: DARWIN использует возможности других инструментов в экосистеме и интегрировался с ними, чтобы позволить различным пользователям иметь единый опыт построения конвейеров машинного обучения, создания метрик и каталога данных в одном инструменте.
- Масштабируемый и хостед решением: наша цель состояла в том, чтобы отвлечь пользователей от автономных инструментов, многие из которых использовались на их персональных компьютерах, при этом обеспечив горизонтальное масштабирование нашего нового решения и предоставление того же опыта, что и эти инструменты, наряду с ресурсами и изоляции от окружающей среды.
- Расширяемость: Команда стремилась выйти за рамки простого создания блокнота и позволить пользователям создавать свое собственное приложение (BYOA) и интегрировать его в DARWIN. Это позволяет пользователям расширять платформу самостоятельно.
Архитектура DARWIN
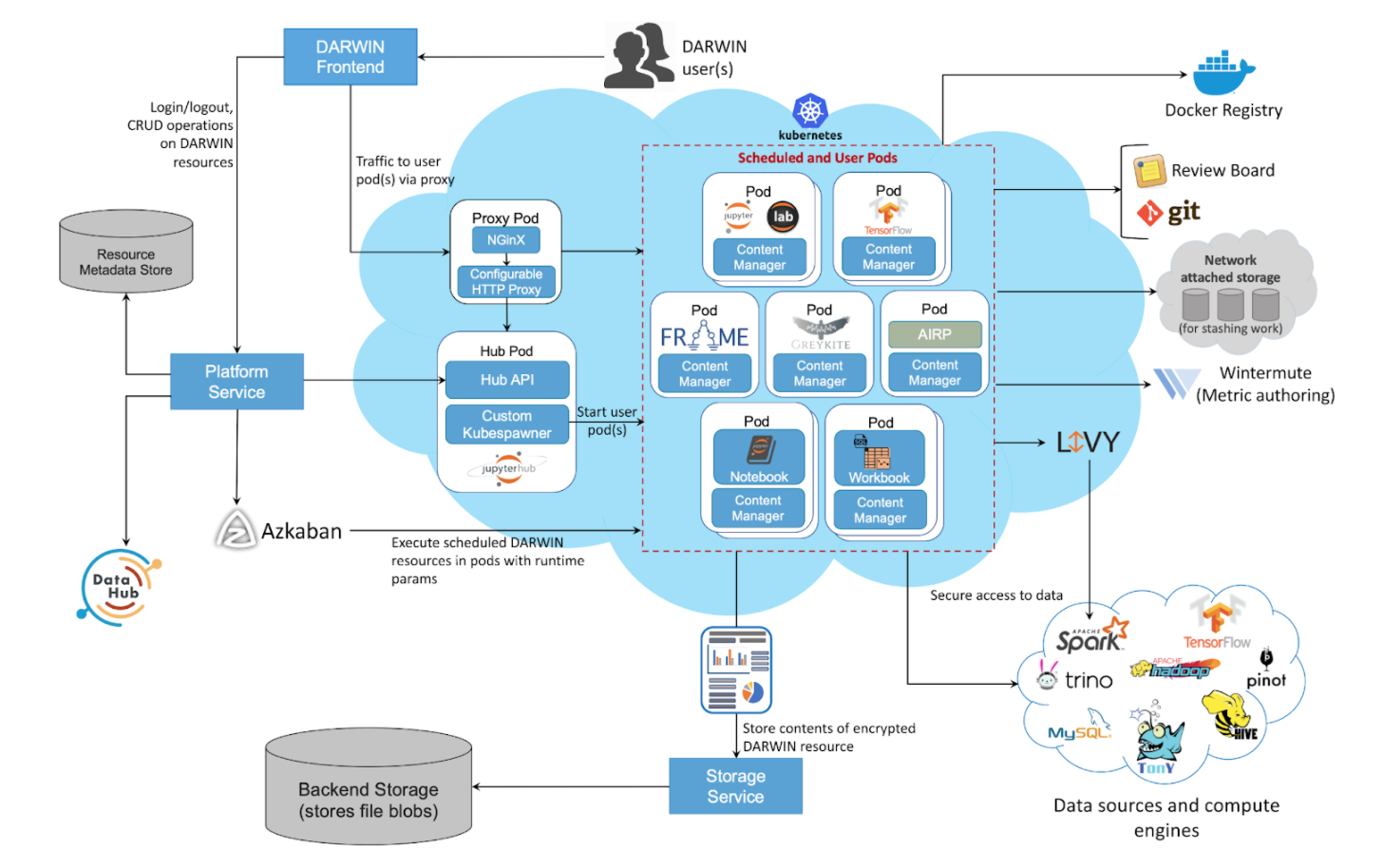
DARWIN: Единое окно для платформ данных
DARWIN поддерживает несколько механизмов для запросов датасетов в LinkedIn. Поддерживается Spark с использованием таких языков, как Python, R, Scala или Spark SQL. Более того, поддерживается доступ к Trino и MySQL. DARWIN также предоставляет прямой доступ к данным в HDFS, что полезно при использовании таких платформ, как Tensorflow.
Фундамент платформы DARWIN
Масштабирование и изоляция с помощью Kubernetes
DARWIN должен быть горизонтально масштабируемым, чтобы приспособиться к растущему числу пользователей. Более того, не менее важным было наличие у пользователей собственной выделенного и изолированного environment'a. Kubernetes помог добиться и того, и другого, а его поддержка long-running сервисов, а также фичами безопасности сделали очевидным выбором в его сторону.
Расширяемость с помощью Docker образов
Docker был выбран не только для запуска user notebook containers в Kubernetes. Кроме того, Docker позволяет пользователям упаковывать различные библиотеки и приложения благодаря своей способности изолировать среды. Таким образом, он отлично подходит для нашего видения «Принеси свое собственное приложение» (BYOA) в DARWIN. Разработчики приложений могут сосредоточиться на упаковке кода своего приложения и развертывании в DARWIN, вместо того чтобы беспокоиться о масштабировании, поддержке надежности сайта, соответствии и управлении, обнаружении, совместном использовании и тд.
Управление concurrent юзер environment'ами используя JupyterHub
JupyterHub обладает широкими возможностями настройки и может обслуживать несколько сред с подключаемой аутентификацией. JupyterHub также предоставляет Kubernetes spawner для запуска независимых пользовательских серверов в Kubernetes, тем самым предоставляя пользователям собственную изолированную среду. Гибкость, которую обеспечивает JupyterHub, помогает интегрировать его со стеком аутентификации LinkedIn и обеспечивает поддержку широкого спектра приложений в экосистеме DARWIN.
Governance: Safety, trust и compliance
DARWIN ведет аудит для каждой операции, шифруем результаты выполнения и хранит их. Кроме того, доступ к ресурсам DARWIN контролируется с помощью точного контроля доступа, что предотвращает любой несанкционированный доступ.
Ключевые фичи DARWIN
Поддержка нескольких языков
DARWIN предоставляет конечным пользователям возможности разработки на различных языках, включая Python, SQL, R и Scala для Spark, охватывая все языки, используемые дата сайентистами и инженерами по искусственному интеллекту в LinkedIn. Поддержка стольких языков дает пользователям возможность сосредоточиться на анализе не заморачиваясь обучая новый язык для того чтобы кастомизировать работу.
Возможности Intellisense
Поддержка таких языков, таких как SQL, Python, R и Scala.
SQL workbooks
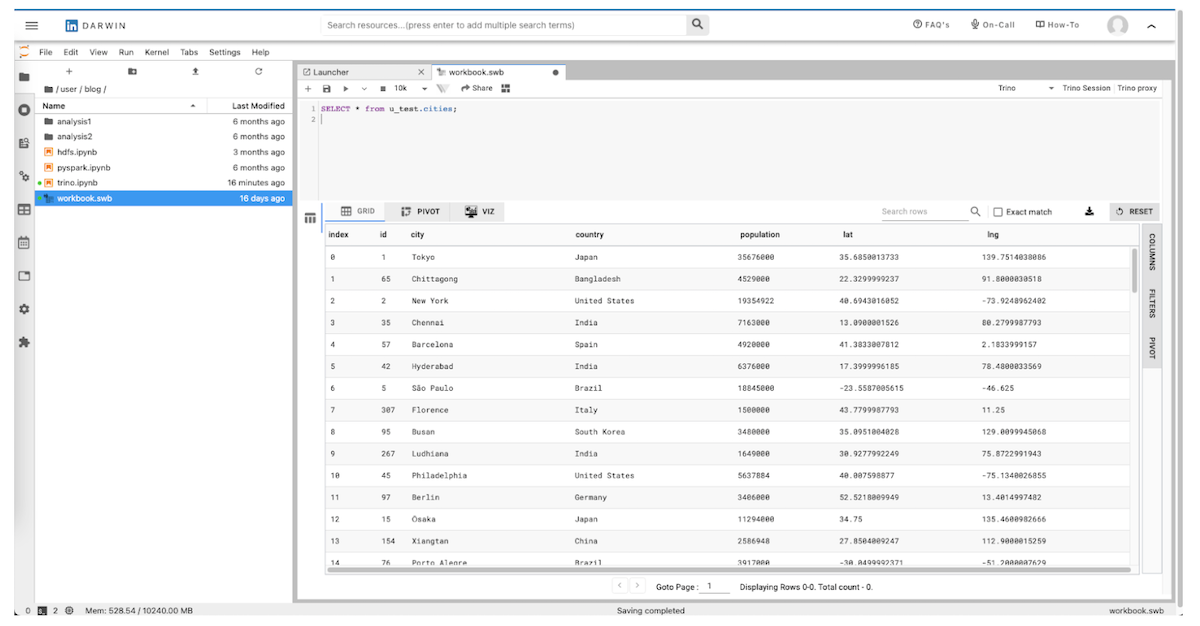
Для работы с SQL в дарвин есть возможность писать запросы и просматривать результаты sql запросов.
Запуск по расписанию воркбуков и notebook'ов
Этот функционал реализован с помощью Azkaban, что позволяет параметризовать запуск и удовлетворить потребности специалистов по анализу данных и генерации новых данных.
Open source DARWIN
LinkedIn планирует сделать его опенсорсным. То как они видят работу DARWIN в опенсорсе и его интеграцию с другими системами можно увидеть ниже: