5 Advanced SQL концептов которые нужно знать в 2022

1. Common Table Expressions (CTEs)

При работе с данными иногда вам нужно запросить результаты другого запроса. Простой способ добиться этого — использовать sub-query.
Однако с ростом сложности sub-query вычислений становятся трудными для чтения и отладки. Именно тогда на сцену выходят CTE, которые облегчают вашу жизнь. CTE упрощают написание и обслуживание сложных запросов. ✅
Например, рассмотрим следующее извлечение данных с использованием sub-query:
SELECT Sales_Manager, Product_Category, UnitPrice
FROM Dummy_Sales_Data_v1
WHERE Sales_Manager IN (SELECT DISTINCT Sales_Manager
FROM Dummy_Sales_Data_v1
WHERE Shipping_Address = 'Germany'
AND UnitPrice > 150)
AND Product_Category IN (SELECT DISTINCT Product_Category
FROM Dummy_Sales_Data_v1
WHERE Product_Category = 'Healthcare'
AND UnitPrice > 150)
ORDER BY UnitPrice DESCЗдесь используется только два подзапроса с понятным кодом.
Если добавить больше вычислений в подзапросы или даже добавить еще несколько подзапросов — сложность возрастает , что делает код менее читабельным и трудным в обслуживании.
Теперь давайте посмотрим на упрощенную версию вышеуказанного подзапроса с CTE:
WITH SM AS
(
SELECT DISTINCT Sales_Manager
FROM Dummy_Sales_Data_v1
WHERE Shipping_Address = 'Germany'
AND UnitPrice > 150
),
PC AS
(
SELECT DISTINCT Product_Category
FROM Dummy_Sales_Data_v1
WHERE Product_Category = 'Healthcare'
AND UnitPrice > 150
)
SELECT Sales_Manager, Product_Category, UnitPrice
FROM Dummy_Sales_Data_v1
WHERE Product_Category IN (SELECT Product_Category FROM PC)
AND Sales_Manager IN (SELECT Sales_Manager FROM SM)
ORDER BY UnitPrice DESCСложный подзапрос разбивается на более простые блоки кодов, которые необходимо использовать.
Таким образом, сложные подзапросы переписываются в два CTE SM, PCкоторые легче читать и изменять. 🎯
Оба приведенных выше запроса, требующие одинакового времени для выполнения, вернули такой результат:
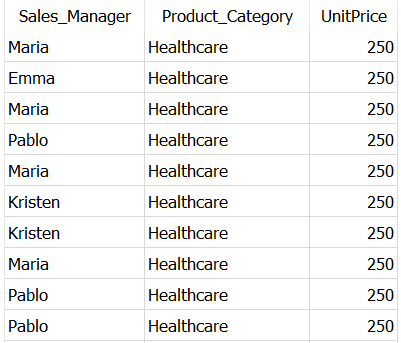
CTE по существу позволяют вам создать временную таблицу из результата запроса. Это улучшает читаемость кода и его обслуживание. ✅
Реальные наборы данных могут содержать миллионы или миллиарды строк, занимающих тысячи ГБ памяти. Выполнение расчетов с использованием данных из этих таблиц и особенно непосредственное объединение их с другими таблицами будет довольно затратным.
Окончательным решением таких задач является использование CTE. 💯
Забегая вперед, давайте посмотрим, как можно присвоить целочисленный «ранг» каждой строке в наборе данных с помощью оконных функций.
2. ROW_NUMBER() vs RANK() vs DENSE_RANK()

Второй часто используемой концепцией при работе с реальными наборами данных является ранжирование записей. Компании используют его в различных сценариях, таких как:
- Рейтинг самых продаваемых брендов по количеству проданных единиц
- Ранжирование лучших продуктовых вертикалей по количеству заказов или полученному доходу
- Получение названия фильма в каждом жанре с наибольшим количеством просмотров
ROW_NUMBER, RANK()и DENSE_RANK()по существу используются для присвоения последовательных целых чисел каждой записи в указанном разделе результирующего набора.
Поведение и способ, которым целые числа присваиваются каждой записи, изменяются, когда в результирующей таблице есть повторяющиеся строки. ✅
Давайте рассмотрим пример с Dummy Sales Dataset, чтобы перечислить все категории продуктов, адрес доставки в порядке убывания стоимости доставки.
SELECT Product_Category,
Shipping_Address,
Shipping_Cost,
ROW_NUMBER() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RowNumber,
RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RankValues,
DENSE_RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as DenseRankValues
FROM Dummy_Sales_Data_v1
WHERE Product_Category IS NOT NULL
AND Shipping_Address IN ('Germany','India')
AND Status IN ('Delivered')Как вы можете видеть, синтаксис для всех трех одинаковый, однако он приводит к разным выводам, как показано ниже:
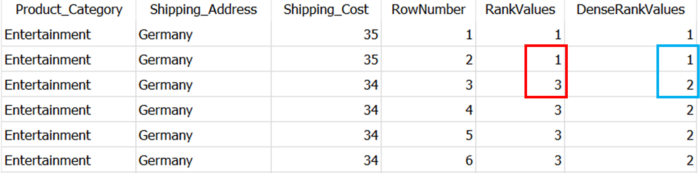
RANK()is извлекает ранжированные строки на основе условия ORDER BYпредложения. Как видите, между первыми двумя строками есть связь, т. е. первые две строки имеют одинаковое значение в столбце Shipping_Cost ( о котором говорится в ORDER BYпункте ).
RANKприсваивает одно и то же целое число обеим строкам. Однако он добавляет количество повторяющихся строк к повторяющемуся рангу, чтобы получить ранг следующей строки. Вот почему третья строка ( отмечена красным ) RANKприсваивает ранг 3( 2 повторяющихся строки + 1 повторяющийся ранг )
DENSE_RANKпохож на RANK, но он не пропускает ни одного числа, даже если между строками есть ничья. Это вы можете увидеть в синей рамке на картинке выше.
В отличие от двух предыдущих, ROW_NUMBERпросто присваивает последовательные номера каждой записи в разделе, начиная с 1. Если он обнаруживает два одинаковых значения в одном разделе, он присваивает обоим разные ранговые номера.
Для следующего partition для product category > shipping address > Entertainment — India, rank по 3-м функциям начнется с 1-цы как показано ниже:
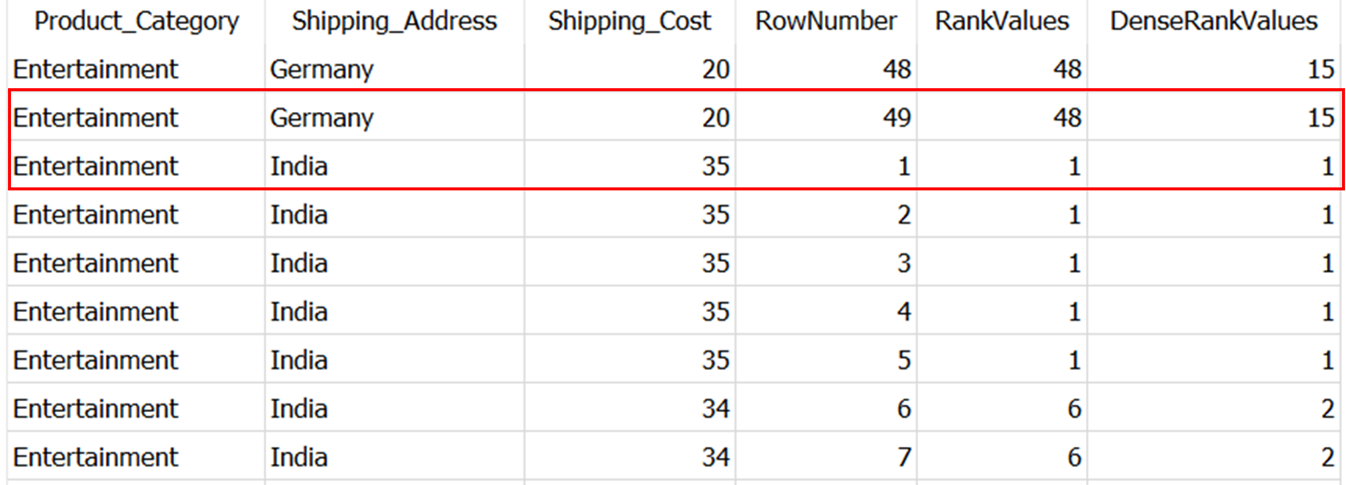
В конечном случае, если в столбце, который юзается для ORDER BY эти фунуции вернут один и тот же результат.
3. CASE WHEN

Оператор Case позволит вам реализовать if-else в SQL.
При работе над реальными проектами данных оператор CASE часто используется для категоризации данных на основе значений в других столбцах. Его также можно использовать вместе с агрегатными функциями.
SELECT OrderID,
OrderDate,
Sales_Manager,
Quantity,
CASE WHEN Quantity > 51 THEN 'High'
WHEN Quantity < 51 THEN 'Low'
ELSE 'Medium'
END AS OrderVolume
FROM Dummy_Sales_Data_v1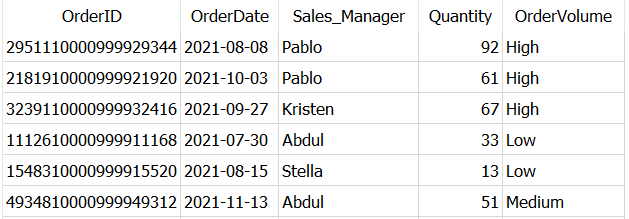
В случае с конкретным примером выражение добавило доп колонку, где вставляет значение high, medium или low в зависимости от значений в столбце Quantity.
Другим часто используемым, но менее известным вариантом использования оператора CASE - Data Pivoting.
Data Pivoting - это когда мы меняем местами колонки со строками.
Например, давайте выясним, сколько заказов обработал каждый менеджер по продажам для Сингапура, Великобритании, Кении и Индии.
SELECT Sales_Manager,
COUNT(CASE WHEN Shipping_Address = 'Singapore' THEN OrderID
END) AS Singapore_Orders,
COUNT(CASE WHEN Shipping_Address = 'UK' THEN OrderID
END) AS UK_Orders,
COUNT(CASE WHEN Shipping_Address = 'Kenya' THEN OrderID
END) AS Kenya_Orders,
COUNT(CASE WHEN Shipping_Address = 'India' THEN OrderID
END) AS India_Orders
FROM Dummy_Sales_Data_v1
GROUP BY Sales_Managerиспользуя CASE..WHEN..THEN, мы создали отдельные столбцы для каждого адреса доставки, чтобы получить ожидаемый результат, как показано ниже.
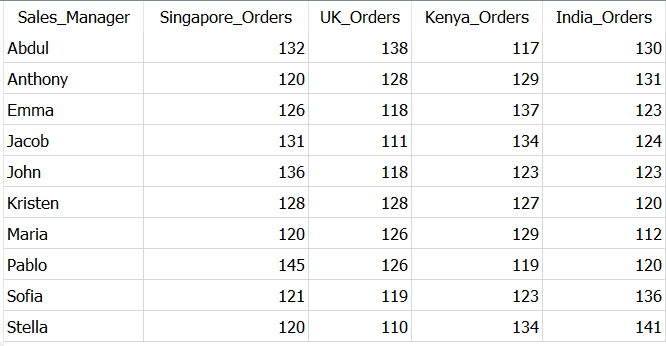
В зависимости от ваших задач вы также можете использовать различные агрегации, такие как SUM, AVG, MAX, MIN с оператором CASE.
4. Extract Data From Date — Time Columns

В некоторых собесах или просто в рабочих задачах вас попросят агрегировать данные по месяцам или рассчитать определенные показатели за конкретный месяц.
И когда в наборе данных нет отдельного столбца месяца, вам нужно извлечь нужную часть даты из переменной даты и времени в данных.
Различные среды SQL имеют разные функции для извлечения частей даты. В MySQL вы должны знать —
EXTRACT(part_of_date FROM date_time_column_name)
YEAR(date_time_column_name)
MONTH(date_time_column_name)
MONTHNAME(date_time_column_name)
DATE_FORMAT(date_time_column_name)например, давайте узнаем общее количество заказов каждый месяц
SELECT strftime('%m', OrderDate) as Month,
SUM(Quantity) as Total_Quantity
from Dummy_Sales_Data_v1
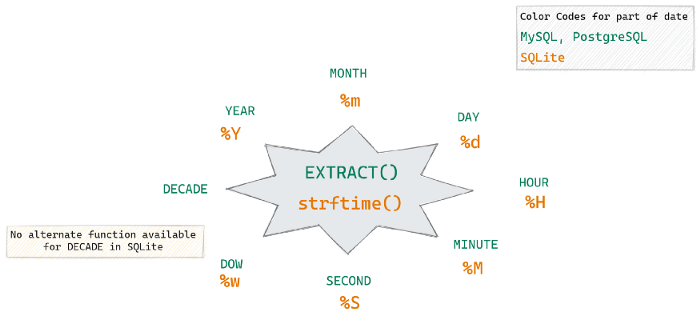
GROUP BY strftime('%m', OrderDate)Ниже приведено изображение, на котором показаны наиболее часто извлекаемые части даты и ключевые слова, которые следует использовать в EXTRACTфункции.
5. SELF JOIN

Они точно такие же, как и другие JOIN в SQL, с той лишь разницей, что SELF JOINвы соединяете таблицу с самой собой.
Ключевого слова SELF JOINнет, вы просто юзаете join где обе таблицы, которые участвуют в нем - это одна и та же таблица
Напишите SQL-запрос, где вы находите сотрудников, которые зарабатывают больше, чем их менеджеры
. Один из наиболее часто задаваемых вопросов на собеседованиях.SELF JOIN
давайте возьмем это в качестве примера и создадим набор данных Dummy_Employees, как показано ниже.
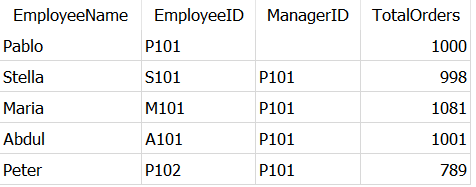
И попробуйте узнать, какие сотрудники обрабатывают больше заказов, чем их менеджер, используя этот запрос:
SELECT t1.EmployeeName, t1.TotalOrders
FROM Dummy_Employees AS t1
JOIN Dummy_Employees AS t2
ON t1.ManagerID = t2.EmployeeID
WHERE t1.TotalOrders > t2.TotalOrders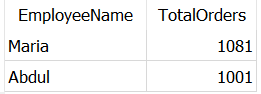
Как и ожидалось, вернулись сотрудники — Абдул и Мария, — которые обработали больше заказов, чем их менеджер — Пабло.